
在人工智能领域,大型语言模型(LLM)正以前所未有的速度发展。其中,DeepSeek系列模型以其卓越的性能和创新性设计,受到了广泛关注。本文将深入探讨DeepSeek-R1模型,特别是其在强化学习(RL)方面的独特之处——带有冷启动的强化学习,并分析其在推理任务上的表现和优势。
DeepSeek-R1的诞生背景
DeepSeek系列模型,正如其名,致力于在深度学习领域进行更深层次的探索。此前推出的DeepSeek-R1-Zero模型,以其强大的推理能力令人印象深刻。然而,该模型也存在一些局限性,例如可读性较差,以及在生成文本时可能出现多种语言混用的情况。为了克服这些问题,并进一步提升模型在复杂推理任务中的性能,DeepSeek团队推出了DeepSeek-R1模型。
冷启动的强化学习:DeepSeek-R1的核心创新
DeepSeek-R1模型最显著的特点是在强化学习(RL)之前引入了多阶段训练和冷启动数据。这种方法旨在通过预训练阶段为模型提供更丰富的知识储备和更稳定的学习起点。传统的强化学习往往从零开始,模型需要通过大量的试错来学习最优策略。而DeepSeek-R1的冷启动机制,则可以有效地减少试错次数,加速学习过程,并提高学习效率。
多阶段训练
DeepSeek-R1的多阶段训练通常包括以下几个阶段:
预训练阶段:在这个阶段,模型会学习大量的文本数据,掌握语言的语法、语义和常识知识。预训练的目标是让模型具备一定的语言理解和生成能力。
指令微调阶段:在这个阶段,模型会学习如何根据给定的指令生成相应的输出。指令微调的目标是让模型能够更好地理解用户的意图,并生成符合用户需求的文本。
奖励模型训练阶段:在这个阶段,会训练一个奖励模型,用于评估模型生成的文本质量。奖励模型会根据文本的流畅度、相关性、准确性等指标,给出一个奖励值。这个奖励值将用于指导强化学习过程。
强化学习阶段:在这个阶段,模型会根据奖励模型的反馈,不断调整自身的策略,以最大化奖励值。强化学习的目标是让模型能够生成更高质量的文本。
冷启动数据
冷启动数据是指在强化学习之前,为模型提供的一些高质量的样本数据。这些数据可以帮助模型更快地找到一个好的策略,并避免陷入局部最优解。冷启动数据通常包括以下几种类型:
专家数据:由领域专家生成的数据,通常具有很高的质量和准确性。
人工标注数据:由人工标注员标注的数据,通常具有很高的相关性和可读性。
自生成数据:由模型自身生成的数据,经过筛选和过滤后,可以作为冷启动数据。
通过多阶段训练和冷启动数据的引入,DeepSeek-R1模型能够更快地学习到有效的策略,并在推理任务中表现出更强的性能。
DeepSeek-R1在推理任务上的表现
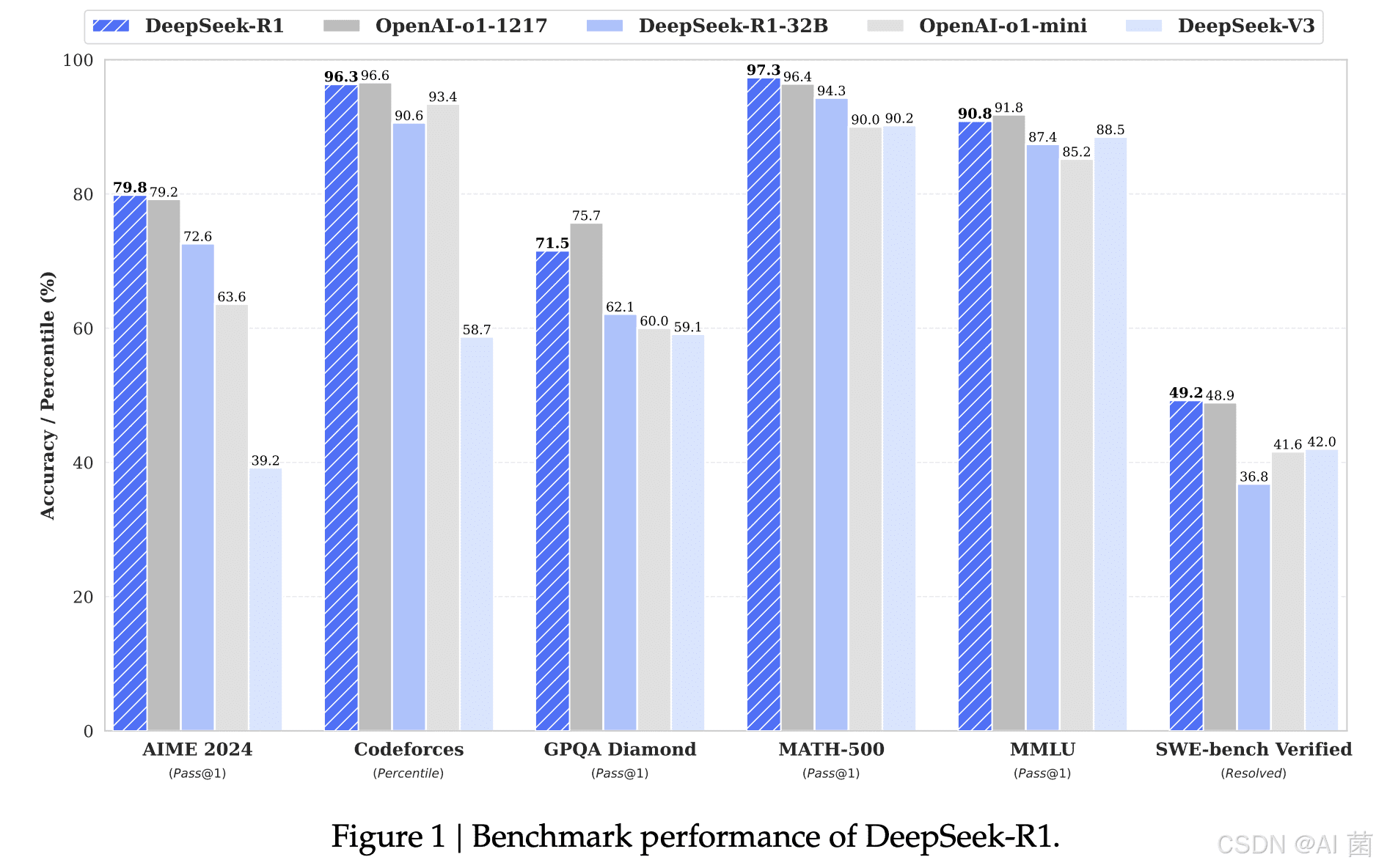
推理是大型语言模型的一项关键能力,它涉及到对已知信息的整合、分析和推断,以解决新的问题。DeepSeek-R1在推理任务上的表现与OpenAI的o1-1217模型相当,这表明其在逻辑推理、常识推理和数学推理等方面都具备了强大的能力。具体的,DeepSeek-R1在以下几个方面表现突出:
复杂逻辑推理:能够处理多步骤的逻辑推理问题,例如根据一系列前提条件推导出结论。
常识推理:能够利用常识知识来解决问题,例如理解物理世界的规律、社会规范和人类行为。
数学推理:能够进行数学计算和符号推理,例如解决数学问题、证明数学定理。
为了验证DeepSeek-R1在推理任务上的性能,研究人员通常会使用一些标准的benchmark数据集,例如:
MMLU (Massive Multitask Language Understanding):一个包含多个学科的常识推理数据集。
HellaSwag:一个用于评估模型常识推理能力的数据集。
GSM8K (Grade School Math 8K):一个包含小学数学应用题的数据集。
通过在这些数据集上进行测试,可以客观地评估DeepSeek-R1的推理能力。
DeepSeek-R1的优势与局限
优势:
强大的推理能力:DeepSeek-R1在推理任务上的表现与OpenAI-o1-1217相当,这表明其具备了强大的逻辑推理、常识推理和数学推理能力。
可读性好:相比于DeepSeek-R1-Zero,DeepSeek-R1生成的文本可读性更好,更易于理解。
语言混用问题得到缓解:DeepSeek-R1在生成文本时,语言混用的问题得到了有效缓解,能够生成更流畅、更自然的文本。
冷启动加速学习:通过多阶段训练和冷启动数据的引入,DeepSeek-R1能够更快地学习到有效的策略,并提高学习效率。
局限:
计算资源需求高:训练大型语言模型需要大量的计算资源,这对于一些研究机构和个人开发者来说是一个挑战。
数据依赖性强:模型的性能很大程度上取决于训练数据的质量和数量,如果训练数据不足或者质量不高,模型的性能可能会受到影响。
可解释性不足:大型语言模型的内部机制复杂,难以解释其推理过程,这给模型的应用带来了一定的挑战。
DeepSeek-R1的未来发展方向
DeepSeek-R1作为一款先进的大型语言模型,在推理任务上表现出色。未来,DeepSeek-R1可以朝着以下几个方向发展:
进一步提升推理能力:可以通过引入更先进的算法和技术,进一步提升模型在复杂推理任务上的性能。
提高可解释性:可以研究如何提高模型的可解释性,让人们更容易理解其推理过程。
降低计算资源需求:可以研究如何降低模型的计算资源需求,使其更容易部署和应用。
拓展应用领域:可以将DeepSeek-R1应用于更多的领域,例如智能客服、知识问答、代码生成等。
结论
DeepSeek-R1模型通过引入带有冷启动的强化学习方法,在推理任务上取得了显著的进展。它不仅展现了强大的推理能力,还在可读性和语言混用问题上得到了改善。尽管仍存在一些局限性,但DeepSeek-R1无疑是大型语言模型领域的一个重要里程碑,为未来的研究和应用提供了新的思路和方向。随着技术的不断发展,我们有理由相信,DeepSeek系列模型将在人工智能领域发挥越来越重要的作用。








