
大模型落地:挑战、机遇与技术选型白皮书
随着人工智能技术的飞速发展,大型语言模型(LLM)正逐渐渗透到各行各业,驱动着智能化转型的浪潮。然而,LLM的规模化部署并非易事,它面临着诸多挑战,如模型体积庞大、推理效率要求高、上下文理解能力需求高等。本文旨在深入探讨LLM本地部署的必要性,剖析规模化部署所面临的难题,并对比分析主流的大模型部署工具,为企业和开发者提供一份全面的技术选型指南。
本地部署大模型的必要性
在云计算日益普及的今天,为何仍要强调LLM的本地部署?原因在于以下几个关键因素:
数据安全与隐私保护: 对于涉及敏感数据的行业,如金融、医疗等,将数据上传至云端存在潜在的安全风险。本地部署可以将数据控制权牢牢掌握在自己手中,确保数据安全与隐私。
定制化需求: 不同的行业和应用场景对LLM的功能和性能有不同的要求。本地部署可以根据实际需求对模型进行定制和优化,以达到最佳效果。
降低延迟: 对于需要实时响应的应用,如智能客服、实时翻译等,本地部署可以减少网络传输带来的延迟,提高用户体验。
离线环境支持: 在一些特殊的应用场景中,如矿井、野外等,可能无法连接到互联网。本地部署可以保证LLM在离线环境下也能正常运行。
规模化部署LLM的难点
尽管本地部署具有诸多优势,但规模化部署LLM仍然面临着一系列挑战:
- 大规模参数量: LLM动辄拥有数十亿甚至数千亿的参数,导致模型体积庞大,给存储、传输和加载带来巨大压力。模型文件下载、GPU加载时间漫长,严重影响服务启动速度。
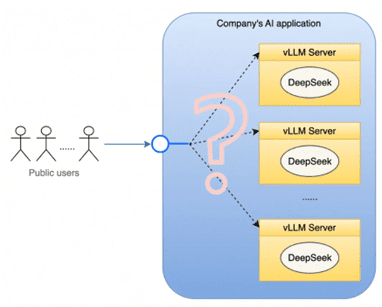
高效推理能力: LLM需要能够在数秒甚至毫秒级别内返回推理结果,以满足实时性要求极高的交互需求。这需要vLLM与内嵌模型的交互能够合理利用缓存数据,维持对话的连续性和响应的速度。
上下文理解: 在对话场景中,LLM需要理解对话的上下文信息,以保证对话的连贯性。避免每次对话被分配到不同的后端资源导致上下文信息丢失。LLM 同时需要稳定的长连接,为用户提供一个持久的交互窗口。这意味着底层系统必须能够有效地管理和协调众多底层资源生命周期,确保对话的连贯性和稳定性。
资源利用与波峰波谷管理: vLLM 业务对显卡集群的资源消耗呈现出明显的波峰和波谷特性。为了确保在业务高峰时段有足够的计算能力,企业通常会提前购买足量的显卡来覆盖峰值需求。然而,在非高峰时段(波谷),大部分显卡将处于空闲状态,造成资源浪费。这种时间上的使用不均,不仅增加了硬件闲置的成本,也降低了投资回报率。
资源使用不均衡与服务质量: 即使在业务高峰期,显卡资源的使用也可能出现不均衡的情况。调度策略不当可能导致某些服务器的显卡、内存和 CPU 资源过度挤兑,而其他服务器则较为空闲。这种负载不均衡现象会影响整体的服务质量,降低用户体验。
DeepSeek系列模型介绍
DeepSeek 是由深度求索公司推出的大语言模型。其技术演进路线为:DeepSeek-LLM、DeepSeek-V2、DeepSeek-V3、DeepSeek-R1。
- DeepSeek LLMs: 这是其发布的第一代大模型,在2万亿标记的英语和中文大型数据集上从头开始训练的开源模型。
- DeepSeek-V2: 这是国产开源MoE大模型,性能达GPT-4级别,但开源、可免费商用、API价格仅为GPT-4-Turbo的百分之一。
- DeepSeek-V3: 是在14.8万亿高质量 token 上完成预训练的一个强大的混合专家 (MoE) 语言模型,拥有6710亿参数。作为通用大语言模型,其在知识问答、内容生成、智能客服等领域表现出色。
- DeepSeek-R1: 这是基于 DeepSeek-V3-Base 训练生成的高性能推理模型,在数学、代码生成和逻辑推断等复杂推理任务上表现优异。
- DeepSeek-R1-Distill: 这是使用 DeepSeek-R1 生成的样本对开源模型进行有监督微调(SFT)得到的小模型,即蒸馏模型。拥有更小参数规模,推理成本更低,基准测试同样表现出色。
DeepSeek系列模型的特点如下表所示:
| 版本 | 技术特点 | 主要贡献 | 数据集 | 性能与效率 | 其他 |
|---|---|---|---|---|---|
| DeepSeek LLM | 开源大语言模型,采用7B和67B两种配置;使用2万亿token数据集;引入多阶段训练和强化学习;通过直接偏好优化提升对话性能 | 提出扩展开源语言模型的规模;通过研究扩展规律指导模型扩展,在代码、数学和推理领域表现优异;提供丰富的预训练数据和多样化的训练信号 | 2万亿token(主要在英语和中文) | 在多个基准测试中优于LLaMA-2 70B,在中文和英文开放式评估中表现优异 | 强调长期主义和开源精神,强调模型在不同领域的泛化能力 |
| DeepSeek-V2 | 采用Mixture-of-Experts (MoE)架构,支持128K上下文长度;采用Multi-head Latent Attention (MLA) 和 DeepSeekMoE;提出辅助损失自由负载均衡策略;通过FP8训练提高训练效率 | 提出高效的MoE架构用于推理和训练通过MLA和DeepSeekMoE实现高效推理和经济训练;在推理吞吐量和生成速度上有显著提升 | 8.1万亿token(扩展到更多中文数据) | 在多个基准测试中表现优异,相比DeepSeek 67B节省42.5%的训练成本,提高最大生成吞吐量5.76倍 | 强调模型的高效性和经济性,提供多种优化策略以提高训练效率 |
| DeepSeek-V3 | 采用671B参数的MoE模型;采用多令牌预测训练目标;引入无辅助损失的负载均衡策略;支持FP8训练,实现高效的训练框架和基础设施优化 | 提出无辅助损失的负载均衡策略;通过多令牌预测增强模型性能;在多个基准测试中表现优异,接近闭源模型水平;在训练效率和成本上有显著优势 | 14.8万亿token(高质量和多样化) | 在多个基准测试中表现最佳,训练成本低,仅需2.788M H800 GPU小时,在推理和部署上表现出色 | 强调模型的高性能和经济性,提供多种优化策略以提高训练和推理效率 |
| DeepSeek-R1 | 通过大规模强化学习提升推理能力;采用冷启动数据和多阶段训练;提出从大模型中蒸馏推理能力到小型模型;在多个基准测试中表现优异 | 通过纯强化学习提升模型推理能力;通过冷启动数据和多阶段训练提高模型性能;通过蒸馏技术将推理能力扩展到小型模型 | 结合多种数据源进行训练,专注于推理任务的强化学习 | 在多个基准测试中表现优异,接近OpenAI o1-1217,在数学和编码任务中表现出色 | 强调模型的推理能力和泛化能力,提供多种优化策略以提高模型性能 |
大模型部署工具对比
选择合适的部署工具是成功部署LLM的关键。以下对几种主流的大模型部署工具进行对比分析:
| 工具名称 | 性能表现 | 易用性 | 适用场景 | 硬件需求 | 模型支持 | 部署方式 | 系统支持 | 总结 |
|---|---|---|---|---|---|---|---|---|
| SGLang v0.4 | 零开销批处理提升1.1倍吞吐量,缓存感知负载均衡提升1.9倍,结构化输出提速10倍 | 需一定技术基础,但提供完整API和示例 | 企业级推理服务、高并发场景、需要结构化输出的应用 | 推荐A100/H100,支持多GPU部署 | 全面支持主流大模型,特别优化DeepSeek等模型 | Docker、Python包 | Linux | 综合来看,如果您是专业的科研团队,拥有强大的计算资源,追求极致的推理速度,那么 SGLang 无疑是首选,它能像一台超级引擎,助力前沿科研探索; |
| Ollama | 继承 llama.cpp 的高效推理能力,提供便捷的模型管理和运行机制 | 小白友好,提供图形界面安装程序一键运行和命令行,支持 REST API | 个人开发者创意验证、学生辅助学习、日常问答、创意写作等个人轻量级应用场景 | 与 llama.cpp 相同,但提供更简便的资源管理 | 模型库丰富,涵盖 1700 多款,支持一键下载安装 | 独立应用程序、Docker、REST API | Windows、macOS、Linux | 要是您是普通的个人开发者、学生,或是刚踏入 AI 领域的新手,渴望在本地轻松玩转大模型,Ollama 就如同贴心伙伴,随时响应您的创意需求; |
| VLLM | 借助 PagedAttention 和 Continuous Batching 技术,多 GPU 环境下性能优异 | 需要一定技术基础,配置相对复杂 | 大规模在线推理服务、高并发场景 | 要求 NVIDIA GPU,推荐 A100/H100 | 支持主流 Hugging Face 模型 | Python包、OpenAI兼容API、Docker | 仅支持 Linux | 对于需要搭建大规模在线服务,面对海量用户请求的开发者而言,VLLM 则是坚实后盾,以高效推理确保服务的流畅稳定; |
| LLaMA.cpp | 多级量化支持,跨平台优化,高效推理 | 命令行界面直观,提供多语言绑定 | 边缘设备部署、移动端应用、本地服务 | CPU/GPU 均可,针对各类硬件优化 | GGUF格式模型,广泛兼容性 | 命令行工具、API服务器、多语言绑定 | 全平台支持 | 而要是您手头硬件有限,只是想在小型设备上浅尝大模型的魅力,或者快速验证一些简单想法,LLaMA.cpp 就是那把开启便捷之门的钥匙,让 AI 触手可及。 |
LLM推理速度指标
LLM推理速度的指标主要包括:
- Time to First Token(TTFT): 第一个Token出来的延迟,用户在输入查询后开始看到模型输出的速度,低等待响应时间在实时交互中至关重要。
- Time Per output Token(TPOT): 每输出令牌时间,为每个查询系统生成输出令牌所需的时间。这个指标对应于每个用户对模型“速度”的感知。
- 延迟: 模型为用户生成完整响应所需的总时间。延迟计算公式为:延迟=(TTFT)+(TPOT)*(要生成的令牌数量)。
- 吞吐量: 推理服务器每秒可以跨所有用户和请求生成的输出令牌数。
这些指标共同决定了LLM服务的性能,包括响应速度和处理能力。这些指标的测试工具是采用vllm的benchmark_serving或者采用sglang.bench_serving。
LLM精度指标
- GPQA (Graduate-Level Google-Proof Q&A Benchmark):研究生级别的谷歌防护问答基准
- MMLU (Massive Multitask Language Understanding):测量大量多任务的语言理解
- SWE-bench Verified:OpenAI 推出更可靠的代码生成评估基准
- MATH500:高中竞赛级别题目,测量数学问题解决能力
- AIME2024 (American Invitational Mathematics Examination):美国奥数比赛
- Codeforces:为计算机编程爱好者提供在线评测系统的俄罗斯网站
- DROP (Discrete Reasoning Over Paragraphs):需要对段落进行离散推理的阅读理解基准
- MGSM (Multilingual General Semantic Understanding):多语言小学数学基准,语言模型作为多语言思维链推理者
- HumanEval:评估在代码上训练的大型语言模型
- MMMU (More Robust Multi-discipline Multimodal Understanding Benchmark):用于专家通用人工智能的大规模多学科多模态理解和推理基准
大厂LLM云服务现状
各大云巨头纷纷上线DeepSeek大模型,如华为云、腾讯云、火山引擎等,国产AI芯片企业也相继宣布适配或上架DeepSeek模型服务,如华为昇腾、沐曦、天数智芯、摩尔线程等。
可以做的事情
- 模型参数高效微调(Parameter-Effcient Fine-Tuning, PEFT)、LoRA等、小模型蒸馏distlation
- 模型编辑,减少模型偏见、毒瘤、知识错误等,进行风控。
- 检索增强生成(Retrieval-Augmented Generation, RAG)
- 视觉-语言模型(VLMs)(Mllama、Qwen2-VL、DeepSeek-VL2)
- 智能体Agent(面向不同厅局、单位的专业模型)
- 信创下的LLM(政务云、超算)
- 一键部署的云服务(政务云、超算)
- AIOps 平台
- DevOps 和 AIOps 的融合
- 面向OA网站的文稿校对编写(错别字、语义歧义、)
- 面向OA网站的自动创建公告通知、应用表单,智能检索文件柜中的内容等(类似通达OA)
总结
深度探索,智领未来,自主信创、云端赋能。LLM的本地部署是机遇与挑战并存的领域,需要综合考虑数据安全、定制化需求、推理效率和资源成本等因素,选择合适的模型和部署工具,才能充分发挥LLM的潜力,驱动智能化转型。








