
阿里大模型面试:后训练(Post-Training)真的是必备技能?
随着今年工业界涌现出众多优秀的开源大语言模型,相关的技术报告也纷纷发布。本文旨在梳理当前工业界主流开源LLM的后训练方案,重点关注训练算法和数据处理两个关键环节。后训练,作为提升大型语言模型性能的重要手段,正在受到越来越多的关注。那么,究竟什么是后训练?它在实际应用中又扮演着怎样的角色?本文将深入探讨这些问题。
后训练的概念与意义
后训练,顾名思义,是指在预训练模型的基础上,利用特定的数据和算法进行进一步的训练,以提升模型在特定任务或领域的性能。与从头开始训练一个大型模型相比,后训练具有更高的效率和更低的成本。通过后训练,我们可以使模型更好地适应特定的应用场景,从而获得更好的性能表现。
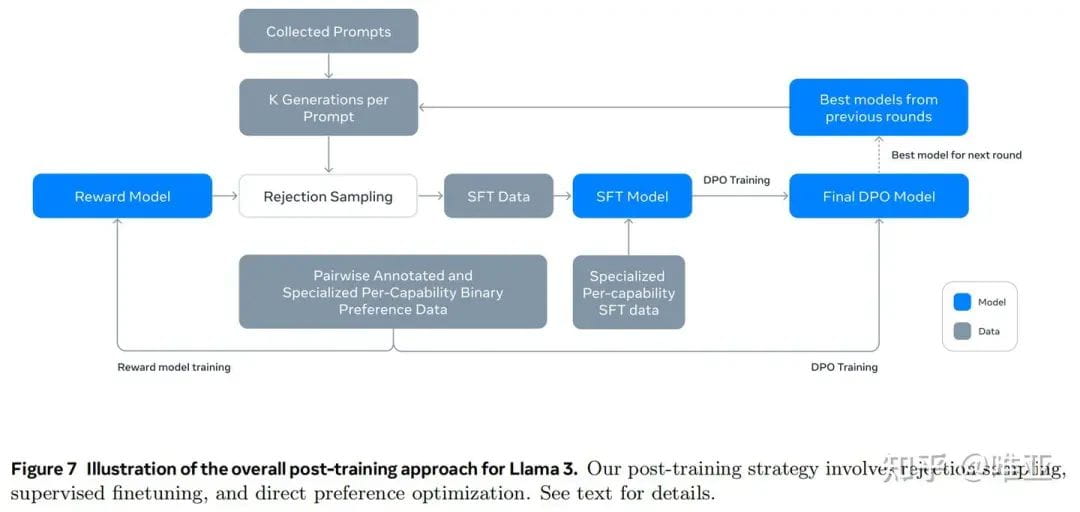
主流开源LLM的后训练方案
当前,工业界主流的开源LLM,如LLaMA、GLM等,都采用了后训练技术。这些模型在预训练阶段已经学习了大量的通用知识,但在特定任务或领域,仍然存在一定的不足。因此,通过后训练,可以进一步提升模型在这些特定领域的性能。
1. LLaMA的后训练方案
LLaMA是由Meta AI开源的大型语言模型。在预训练之后,LLaMA采用了多种后训练策略,以提升模型在不同任务上的性能。其中,指令微调(Instruction Tuning)是一种常用的后训练方法。通过在大量的指令数据上进行微调,可以使模型更好地理解人类的指令,从而更好地完成各种任务。
具体来说,LLaMA的指令微调过程包括以下几个步骤:
- 数据收集:收集大量的指令数据,这些数据包括指令文本和对应的输出文本。
- 数据清洗:对收集到的数据进行清洗,去除噪声和错误。
- 模型微调:使用清洗后的数据对预训练的LLaMA模型进行微调。在微调过程中,可以使用各种优化算法,如AdamW等。
- 评估与调整:对微调后的模型进行评估,根据评估结果调整微调策略。
2. GLM的后训练方案
GLM是由清华大学知识工程研究室开源的大型语言模型。与LLaMA类似,GLM也采用了后训练技术来提升模型性能。GLM的后训练方案主要包括以下几个方面:
- 多任务学习:通过在多个任务上进行联合训练,可以使模型学习到更加通用的知识表示,从而提升模型在各种任务上的性能。
- 对比学习:通过对比学习,可以使模型学习到更加鲁棒的特征表示,从而提升模型在噪声环境下的性能。
- 知识蒸馏:通过知识蒸馏,可以将大型模型的知识迁移到小型模型中,从而在保证性能的同时,降低模型的计算复杂度。
3. 其他开源LLM的后训练方案
除了LLaMA和GLM之外,还有许多其他的开源LLM也采用了后训练技术。这些模型的后训练方案各有特点,但都旨在提升模型在特定任务或领域的性能。
例如,一些模型采用了强化学习的方法进行后训练。通过与环境进行交互,模型可以学习到更加有效的策略,从而提升模型在特定任务上的性能。另一些模型则采用了对抗训练的方法进行后训练。通过对抗训练,可以使模型学习到更加鲁棒的特征表示,从而提升模型在对抗攻击下的性能。
后训练的数据处理
数据是后训练的基础。高质量的数据可以显著提升后训练的效果。在后训练中,数据处理是一个至关重要的环节。数据处理的目标是清洗、整理和增强数据,以便更好地用于模型训练。
1. 数据清洗
数据清洗是指去除数据中的噪声、错误和不一致性。数据清洗是后训练的第一步,也是最重要的一步。如果数据质量不高,即使采用再先进的训练算法,也难以获得理想的效果。
常见的数据清洗方法包括:
- 去除重复数据:去除数据集中重复的样本。
- 去除缺失值:处理数据集中缺失的特征值。常用的方法包括填充缺失值、删除包含缺失值的样本等。
- 去除异常值:识别并去除数据集中异常的样本。常用的方法包括箱线图、Z-score等。
- 纠正错误数据:纠正数据集中错误的标签或特征值。
2. 数据整理
数据整理是指将数据转换为适合模型训练的格式。数据整理的目的是使模型能够更好地理解和利用数据。
常见的数据整理方法包括:
- 文本分词:将文本数据分割成单词或短语。
- 词干提取:将单词转换为其词干形式。例如,将“running”转换为“run”。
- 词形还原:将单词转换为其基本形式。例如,将“better”转换为“good”。
- 向量化:将文本数据转换为向量表示。常用的方法包括词袋模型、TF-IDF、Word2Vec等。
3. 数据增强
数据增强是指通过对现有数据进行变换,生成新的数据。数据增强的目的是增加数据集的大小和多样性,从而提升模型的泛化能力。
常见的数据增强方法包括:
- 文本替换:将文本中的某些词语替换为同义词或近义词。
- 文本插入:在文本中随机插入一些词语。
- 文本删除:随机删除文本中的一些词语。
- 文本回译:将文本翻译成另一种语言,然后再翻译回原始语言。
后训练的训练算法
训练算法是后训练的核心。选择合适的训练算法可以显著提升后训练的效果。在后训练中,常用的训练算法包括:
1. 指令微调
指令微调是一种常用的后训练方法。通过在大量的指令数据上进行微调,可以使模型更好地理解人类的指令,从而更好地完成各种任务。指令微调通常采用监督学习的方法,即利用标注好的指令数据进行训练。
2. 对比学习
对比学习是一种自监督学习方法。通过对比学习,可以使模型学习到更加鲁棒的特征表示,从而提升模型在噪声环境下的性能。对比学习通常采用孪生网络或三元组网络结构,通过最大化相似样本之间的相似度,最小化不相似样本之间的相似度来进行训练。
3. 强化学习
强化学习是一种通过与环境进行交互来学习策略的方法。在后训练中,可以使用强化学习来优化模型的生成策略,从而提升模型在特定任务上的性能。强化学习通常需要定义一个奖励函数,用于评估模型生成的输出的质量。模型通过不断地与环境进行交互,调整自身的策略,以最大化累计奖励。
4. 对抗训练
对抗训练是一种通过引入对抗样本来提升模型鲁棒性的方法。在后训练中,可以使用对抗训练来提升模型在对抗攻击下的性能。对抗训练通常通过生成对抗样本,并将其加入到训练数据中来进行训练。对抗样本是指那些经过微小扰动后,会导致模型产生错误预测的样本。
案例分析:基于后训练的智能客服系统
为了更好地理解后训练在实际应用中的价值,我们来看一个案例:基于后训练的智能客服系统。
1. 背景
某电商平台拥有庞大的用户群体,每天需要处理大量的用户咨询。为了提升客户服务效率,该平台决定引入智能客服系统。然而,由于预训练的通用语言模型在电商领域的专业知识方面存在不足,直接应用效果并不理想。
2. 解决方案
为了解决上述问题,该平台采用了后训练技术,对预训练的语言模型进行微调。
- 数据准备:收集了大量的用户咨询数据,包括用户的问题和客服的回答。对这些数据进行清洗、整理和增强,构建了一个高质量的后训练数据集。
- 模型微调:使用指令微调的方法,在后训练数据集上对预训练的语言模型进行微调。通过微调,模型学习到了电商领域的专业知识,提升了对用户问题的理解能力。
- 效果评估:对微调后的模型进行评估,结果表明,模型在电商领域的问答准确率得到了显著提升。
3. 效果
通过后训练,该电商平台的智能客服系统在以下几个方面取得了显著的效果:
- 提升了问答准确率:模型能够更准确地理解用户的问题,并给出更准确的答案。
- 提高了客户服务效率:智能客服系统能够自动处理大部分用户咨询,减少了人工客服的工作量。
- 降低了运营成本:智能客服系统能够24小时不间断地提供服务,降低了人力成本。
结论
后训练作为提升大型语言模型性能的关键技术,在工业界受到了广泛关注。通过选择合适的训练算法和数据处理方法,可以显著提升模型在特定任务或领域的性能。随着大型语言模型的不断发展,后训练技术也将发挥越来越重要的作用。








