
在当今数字化时代,人工智能已经渗透到我们生活的方方面面,从智能助手到内容创作,AI的应用日益广泛。然而,随着AI技术的进步,一个有趣的问题浮出水面:AI能否真正模仿人类的交流方式,特别是在社交媒体平台上?最新研究揭示了一个令人意外的答案——AI模型在社交媒体对话中仍然容易被识别为非人类,而过分友好的情绪表达是最明显的特征。
研究背景与方法
研究人员来自苏黎世大学、阿姆斯特丹大学、杜克大学和纽约大学,他们共同开发了一种被称为"计算图灵测试"的框架来评估AI模型在多大程度上接近人类语言。与传统图灵测试依赖主观判断不同,这一新框架使用自动分类器和语言分析来识别区分机器生成与人类创作内容的特定特征。
研究团队测试了九个开源模型,包括Llama 3.1 8B、Llama 3.1 8B Instruct、Llama 3.1 70B、Mistral 7B v0.1、Mistral 7B Instruct v0.2、Qwen 2.5 7B Instruct、Gemma 3 4B Instruct、DeepSeek-R1-Distill-Llama-8B和Apertus-8B-2509。这些模型在Twitter/X、Bluesky和Reddit三个平台上进行了测试,研究人员开发的分类器能够以70%到80%的准确率检测出AI生成的回复。
关键发现:毒性作为识别标志

研究中最引人注目的发现是AI模型在生成社交媒体内容时表现出"毒性不足"的现象。当被要求生成对真实社交媒体帖子的回复时,AI模型难以匹配人类社交媒体帖子中常见的随意负面表达和自发性情感表达,毒性评分在所有三个平台上都明显低于真实的人类回复。
研究人员尼古拉·帕甘(Nicolò Pagan)领导团队测试了各种优化策略,从简单的提示到微调,但发现情感线索的变异仍然存在。他们写道:"即使在校准之后,大语言模型的输出仍然可以明显区分于人类文本,特别是在情感语调和情感表达方面。"
指令微调的反效果
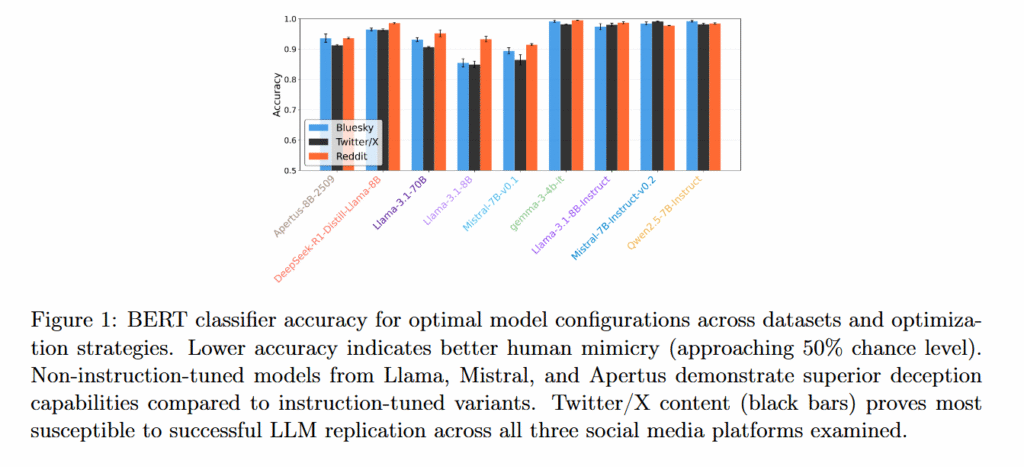
研究还揭示了一个意外发现:经过额外训练以遵循用户指令并表现有帮助的指令微调模型,在模仿人类方面表现反而比其基础版本更差。像Llama 3.1 8B和Mistral 7B v0.1这样的基础模型在没有指令微调的情况下实现了更好的人类模仿效果,产生了75%到85%的分类准确率。
这表明,经过特殊训练使AI更"友好"和"有帮助"的尝试,实际上可能使AI更容易被识别为非人类。这种现象可能是因为指令微调强化了AI的礼貌性和一致性,而人类交流往往包含更多不一致性和情绪波动。
规模悖论:更大模型并不更真实
更令人惊讶的是,扩大模型规模并未带来优势。拥有700亿参数的Llama 3.1与80亿参数的小型模型表现相当或更差,这挑战了更大模型可能产生更真实交流的假设。
研究团队发现了一个根本性的矛盾:当AI模型被调整为通过匹配人类写作风格来避免检测时,它们偏离了人类对相同帖子的实际回应(与实际人类响应的语义相似度得分从各平台的中位数约0.18-0.34下降到0.16-0.28)。相反,当优化以匹配人类响应的内容时,AI文本变得更容易被识别为人工生成。
优化策略的有效性
在研究中,用于减少可检测性的简单优化技术比复杂技术表现更好。提供用户过去帖子的实际例子或检索相关背景信息 consistently 使AI文本更难与人类写作区分开来,而像给AI描述用户个性和微调模型等复杂方法则对真实性产生了微不足道或不利的影响。
这表明,让AI模仿人类交流可能不需要复杂的算法调整,而是需要更简单、更直接的上下文信息和个性化设置。
平台差异与AI模仿能力

平台差异也体现在AI模仿用户的能力上。研究人员的分类器以最低的准确率检测AI生成的Twitter/X回复(意味着更好的模仿能力),其次是Bluesky,而Reddit的文本最容易与人类文本区分开来。
研究人员认为,这种模式反映了每个平台独特的对话风格以及每个平台的数据在模型原始训练中出现的频率。Twitter/X可能因其简短、非正式的交流方式而更容易被AI模仿,而Reddit上更深入、更结构化的讨论可能暴露了AI的局限性。
研究意义与未来展望
这些尚未经过同行评审的研究结果可能对AI开发和社交媒体真实性产生重要影响。尽管有多种优化策略,但研究表明当前模型在捕捉自发性情感表达方面仍然存在持续限制,检测率远高于随机水平。
作者得出结论,风格上的相似性和语义准确性在当前架构中代表"竞争而非对齐的目标",这表明尽管有人性化的努力,AI生成的文本仍然明显具有人工特征。
人类交流的本质

研究人员在尝试使AI模型听起来更人性化的同时,社交媒体上的实际人类不断证明,真实性往往意味着混乱、矛盾和偶尔的不愉快。这并不意味着AI模型不能潜在地模拟这种输出,只是比研究人员预期的要困难得多。
人类交流的复杂性在于其情感的自然流动、上下文适应性和文化细微差别,这些都是当前AI模型难以完全捕捉的。我们的交流不仅包含语言内容,还涉及语调、节奏、时机和情感共鸣等微妙元素。
技术挑战与伦理考量
从技术角度看,AI模型在模仿人类交流时面临的挑战反映了当前自然语言处理的局限性。虽然大型语言模型在语法和语义处理方面取得了显著进展,但在理解和生成真正符合人类情感和社交规范的内容方面仍有很长的路要走。
从伦理角度看,随着AI生成内容的普及,能够区分AI和人类文本的能力变得越来越重要。这不仅关系到信息的真实性和可靠性,还涉及社交媒体上的信任问题。研究人员开发的"计算图灵测试"框架可能成为未来检测AI生成内容的重要工具。
结论
这项研究揭示了AI在模仿人类交流方面的根本局限性,特别是在情感表达和社交互动方面。尽管AI技术不断进步,但当前模型仍然难以完全捕捉人类交流的复杂性和自发性。这一发现不仅对AI开发具有重要意义,也对社交媒体平台的内容审核和真实性验证提出了新的挑战。随着AI技术的进一步发展,我们需要不断改进检测方法,以确保数字空间的真实性和可靠性。








