
深入剖析ChatGPT:原理、发展与训练全景解读
人工智能领域近年来发展迅猛,其中,由OpenAI开发的ChatGPT无疑是备受瞩目的焦点。它不仅能够以自然流畅的语言与人类进行交互,还在知识问答、代码生成、Debug等方面展现出强大的能力。那么,ChatGPT究竟是什么?它又是如何工作的?本文将从原理、发展历程以及训练过程三个维度,对ChatGPT进行全面而深入的剖析。
ChatGPT:AI交互的新范式
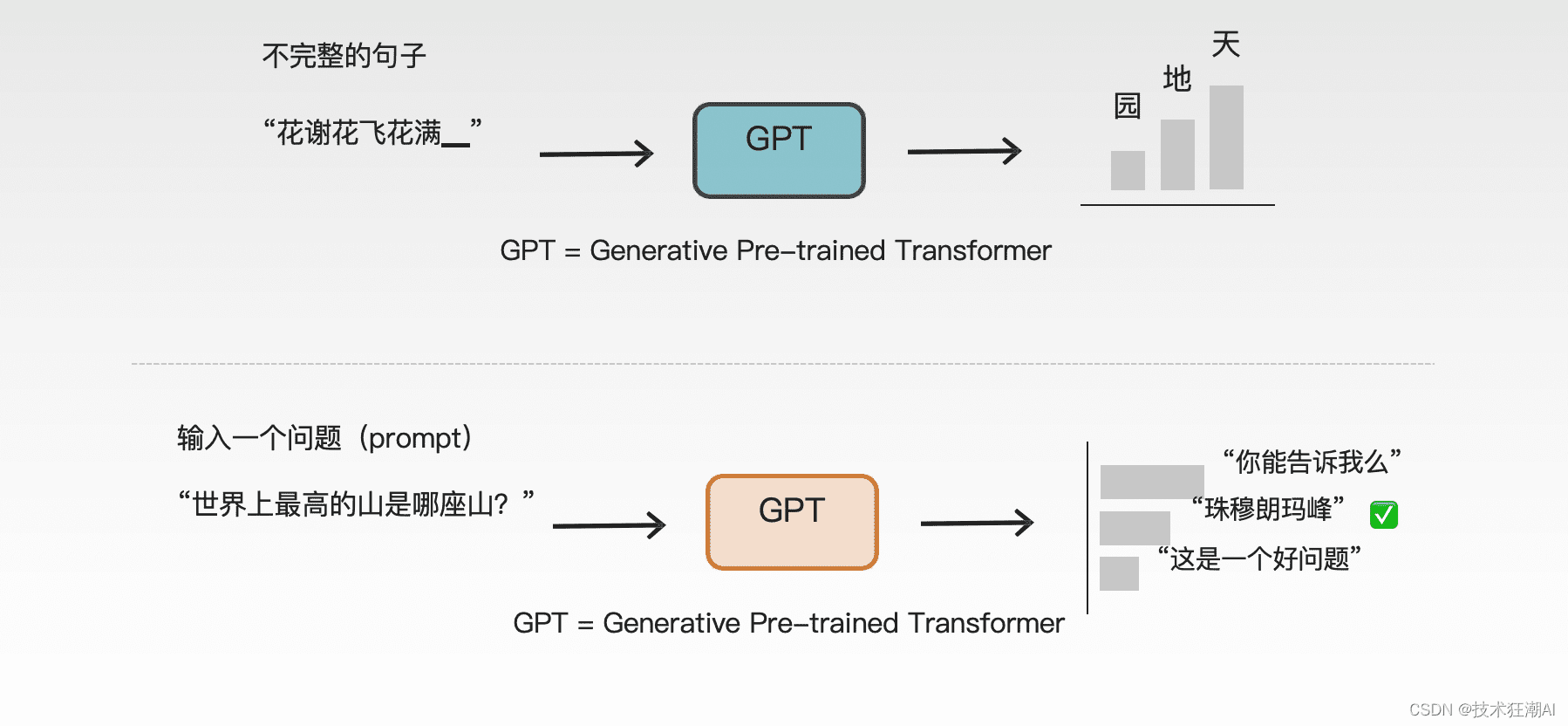
ChatGPT是一种基于语言模型的人工智能程序,其核心在于GPT(Generative Pre-trained Transformer)技术。GPT代表“生成式预训练”,是一种基于深度学习的自然语言处理技术。通过海量语言数据的预训练,ChatGPT能够在多种自然语言任务中表现出色,实现与人类的自然语言交互。

如何高效利用ChatGPT?
ChatGPT的应用场景十分广泛,掌握正确的使用方法至关重要。以下是一些关键技巧:
- 增加细节: 在提问时,提供尽可能详细的背景信息和具体要求,有助于ChatGPT更好地理解问题并给出精准的答案。
- 不断追问: 针对ChatGPT生成的内容,进行深入追问,引导其进一步挖掘和完善答案。
- 保持质疑: 虽然ChatGPT知识储备丰富,但其回答并非绝对正确。在使用过程中,应保持批判性思维,对答案进行验证。
ChatGPT的局限性
虽然ChatGPT功能强大,但并非万能。由于其模型是基于自动推理产生的,未经严格验证,因此存在一定的局限性:
- 中文知识相对匮乏: 相较于英文,中文训练语料库较小,导致ChatGPT在中文知识方面存在一定的不足。
- 缺乏信息来源: ChatGPT无法提供信息来源,这与搜索引擎存在本质区别。用户只能依赖其训练的知识。
- 无法获取最新数据: ChatGPT只能提供训练时间节点之前的数据,无法获取最新的信息。
这些局限性可能会随着ChatGPT的不断训练和进化而得到改善,但答案出错的可能性始终存在。因此,在使用ChatGPT时,务必保持批判性思维,对答案进行验证。
ChatGPT的底层原理
ChatGPT基于Transformer架构,这是一种比RNN和LSTM更为先进的深度学习模型。Transformer架构主要用于处理序列类型数据。我们可以通过ChatGPT的自述来了解其底层原理:

Transformer模型利用自注意力机制(self-attention)来捕捉输入序列的上下文关系,使得每个词都能与整个序列的其他词建立连接,从而有效地捕捉文本中的长距离依赖关系。与传统的RNN相比,Transformer具有更快的训练速度和更强的上下文捕捉能力。
预训练大语言模型的发展历程
Transformer架构出现之前的NLP发展
在Transformer架构和预训练大模型出现之前,NLP领域经历了漫长的发展。深度学习在NLP领域的突破相对较晚,早期主要集中在计算机视觉领域。
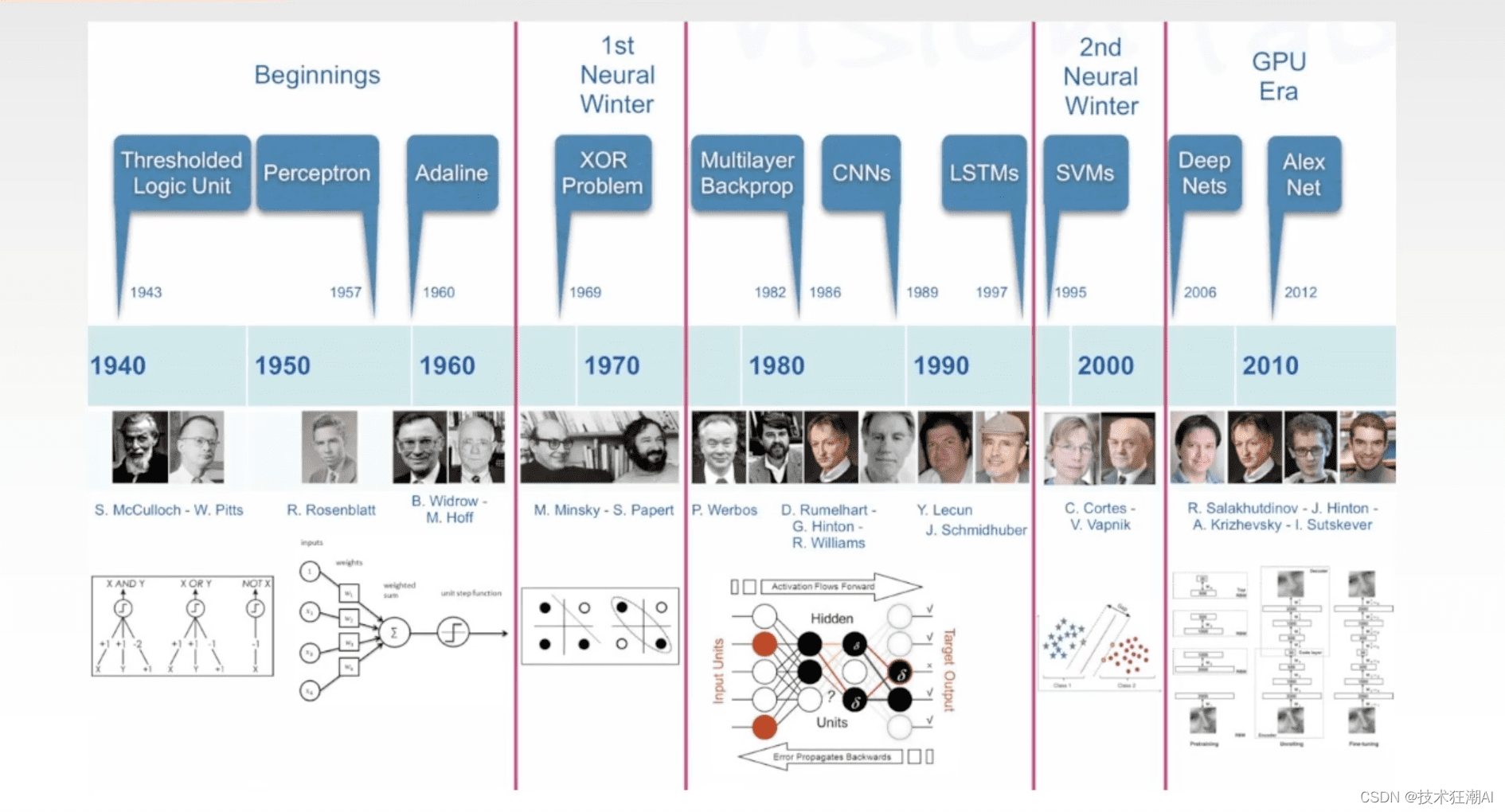
2012年,AlexNet模型在ImageNet图像识别大赛中取得突破,标志着CNN卷积神经网络的兴起。随后,GoogleNet、VGG、ResNet等深度学习模型不断涌现,大幅提升了图像分类、目标检测、语义分割等CV任务的准确性。
然而,在2018年之前,NLP领域虽然有RNN和LSTM,但缺乏真正落地应用的突破性进展。
NLP领域的飞跃:Transformer与BERT的诞生
2018年,Transformer和BERT的诞生为NLP领域带来了第一轮飞跃。这些模型的出现使得NLP的节奏逐渐加快,一系列预训练大模型如雨后春笋般涌现。研究人员可以下载这些预训练大模型,并通过微调,将其应用于各种自然语言处理任务,如语音识别、文本分类、情感分类、命名实体识别、机器翻译、文本摘要、文本生成等。
深度神经网络如何解决NLP问题?
深度神经网络由多层组成,每一层都有许多神经元(节点),每个节点都有一系列参数。当数据输入模型时,这些节点通过参数对数据进行运算,实现从输入空间到输出空间的函数映射。
以微博情感分类为例,一条200字的微博可以转化为200个token输入模型。经过神经网络的计算,最终输出一个二维结果(0或1),代表博主的情绪是负面或正面。
大型预训练网络的发展趋势
从早期的ELMo到2021年左右,预训练网络的发展呈现出明显的趋势:模型越来越大,参数越来越多,训练的语料库也越来越大。
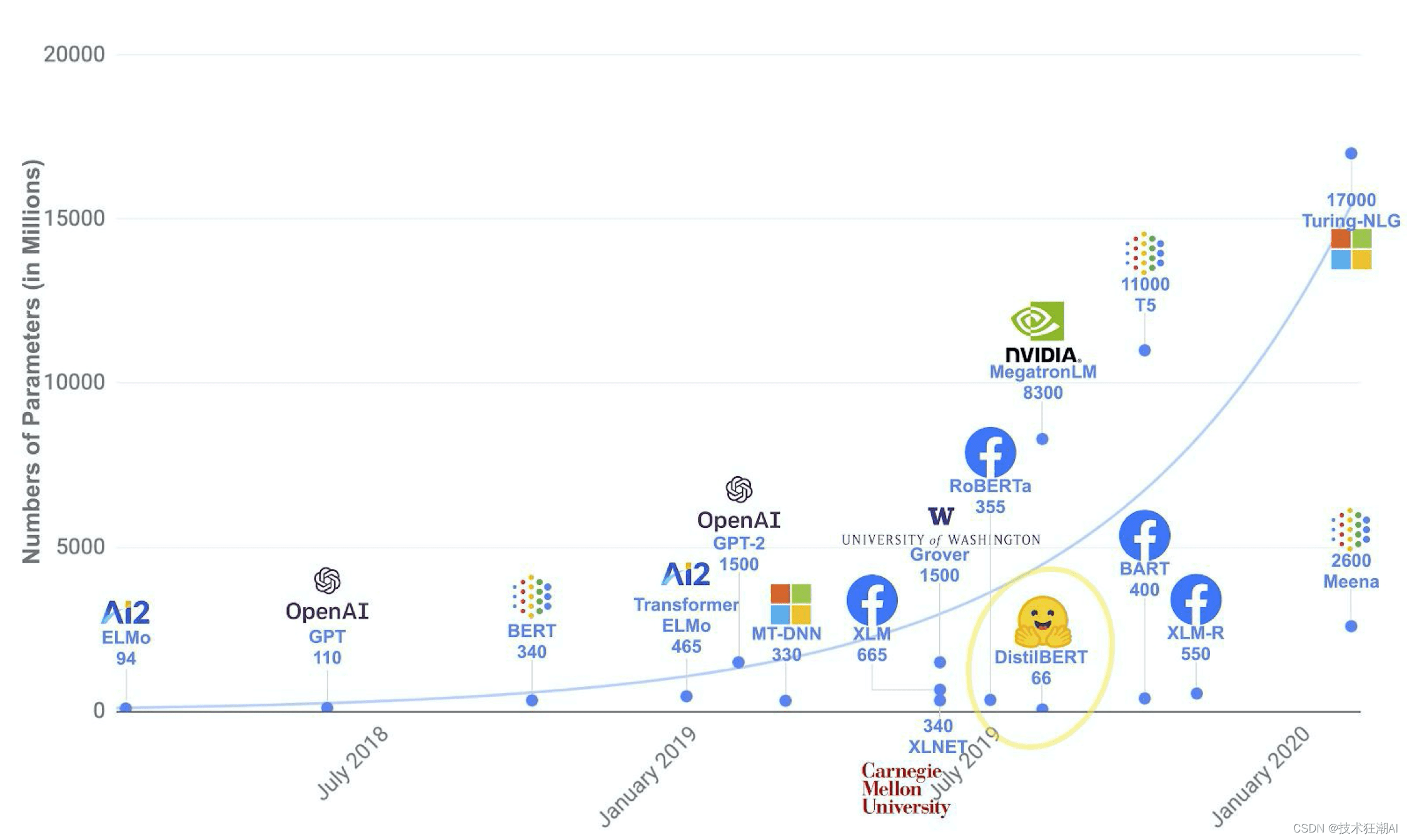
例如,BERT基于Wikidata进行训练,而后续的模型则收录了更多的书籍和网络文本,知识库不断扩大。
2022年的预训练大模型格局
截至2022年12月,预训练大模型已经非常庞大。ChatGPT所基于的GPT-3模型拥有1750亿个参数,虽然在整个大语言模型生态中不算最大,但其效果却超越了许多更大的模型。

Transformer架构:预训练语言模型的基础
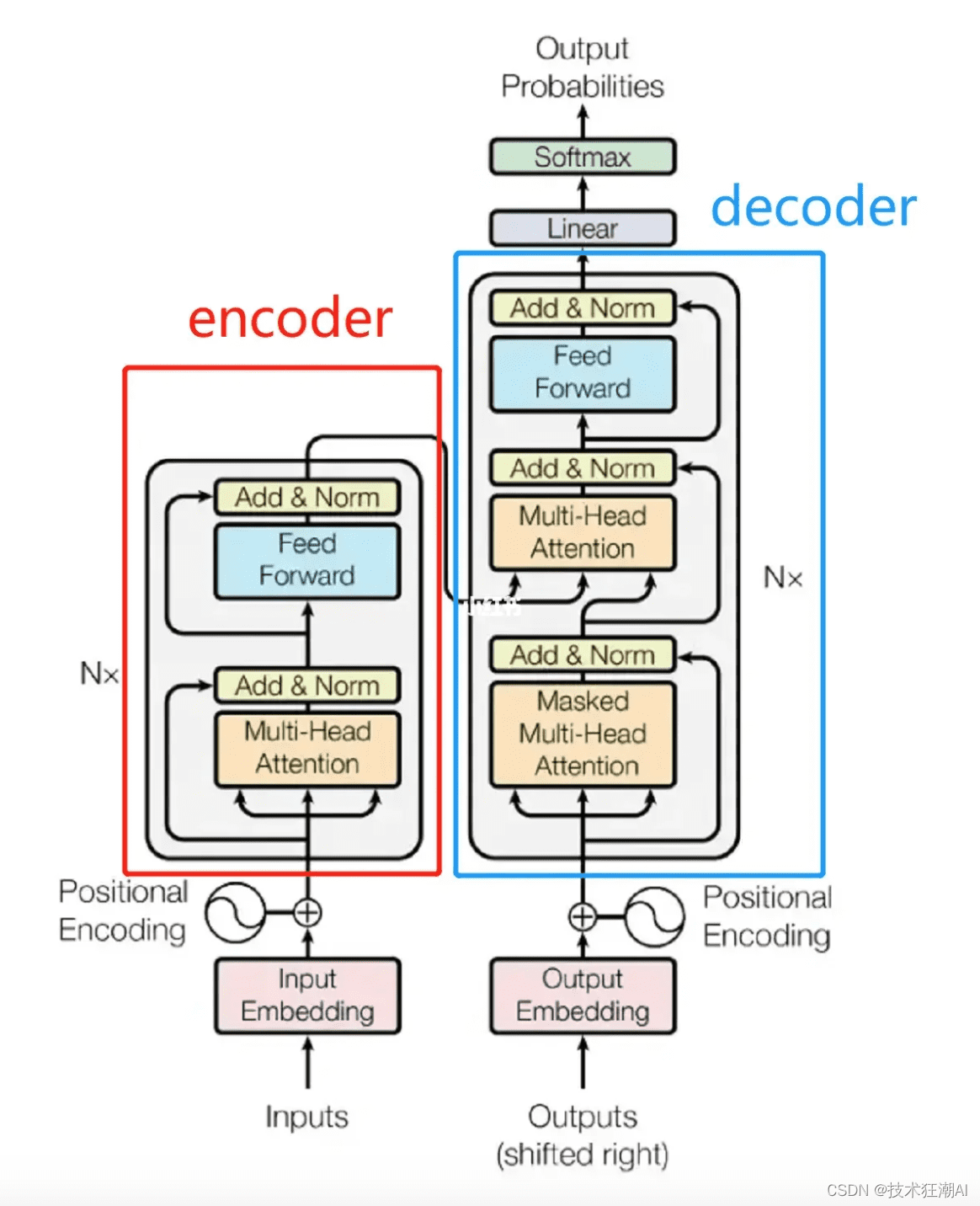
Transformer架构是所有预训练语言模型的基础。它最早由Google在2017年提出,旨在解决传统训练模型(如循环神经网络)中存在的效率问题和并行计算问题。
Transformer模型通过堆叠多个层来构建深度学习模型,从而不断扩大规模,提高模型性能。研究表明,模型越大,越有可能出现更多的涌现能力,例如从不能对话到拥有流畅对话能力。
Seq2Seq:序列到序列的转换
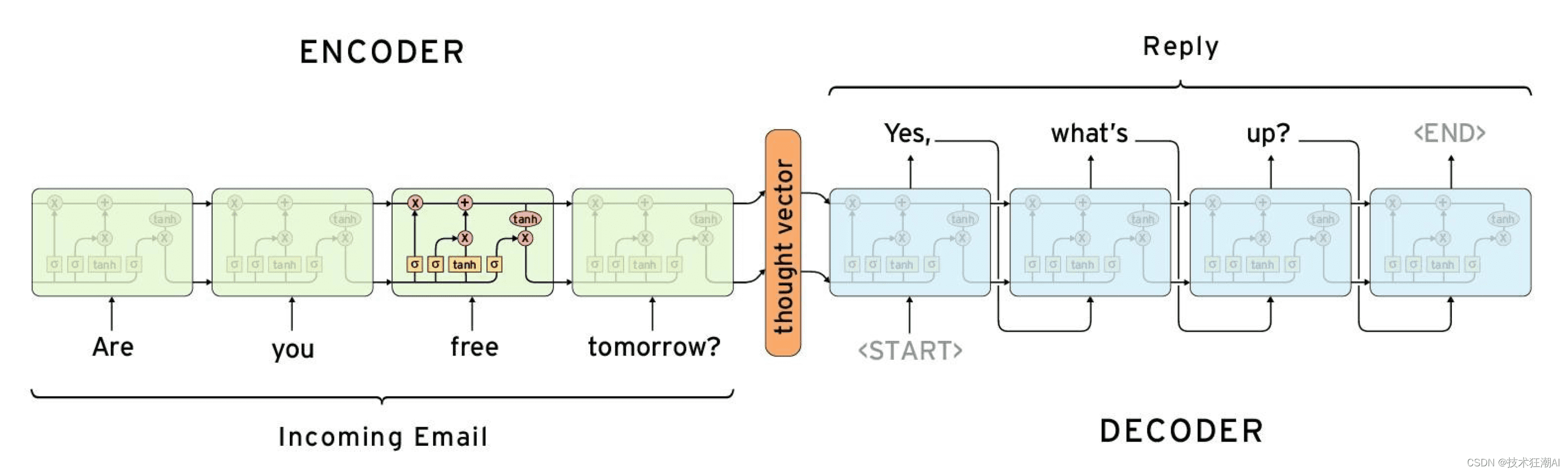
Transformer本身是一种序列到序列的架构。在Seq2Seq架构中,输入的序列会被深度神经网络处理,产生一个输出的文本序列。机器翻译和聊天机器人是典型的应用场景。
Seq2Seq架构包含编码器和解码器。编码器负责将输入序列编码成固定长度的向量表示,解码器则负责将该向量生成对应的输出序列。在聊天机器人中,输入序列通常是用户的提问,输出序列则是机器人的回答或响应。
BERT vs GPT:不同的任务,不同的侧重
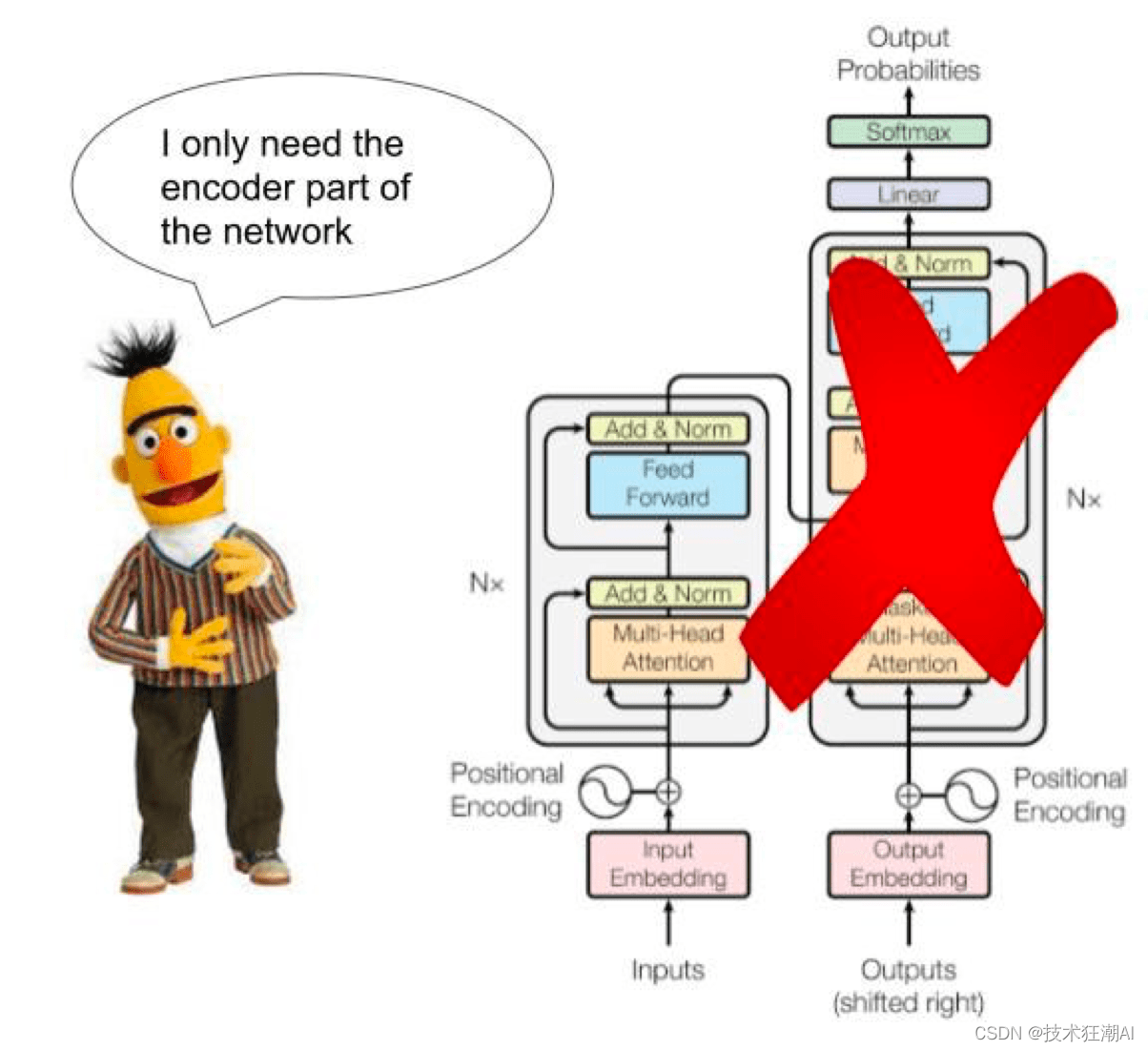
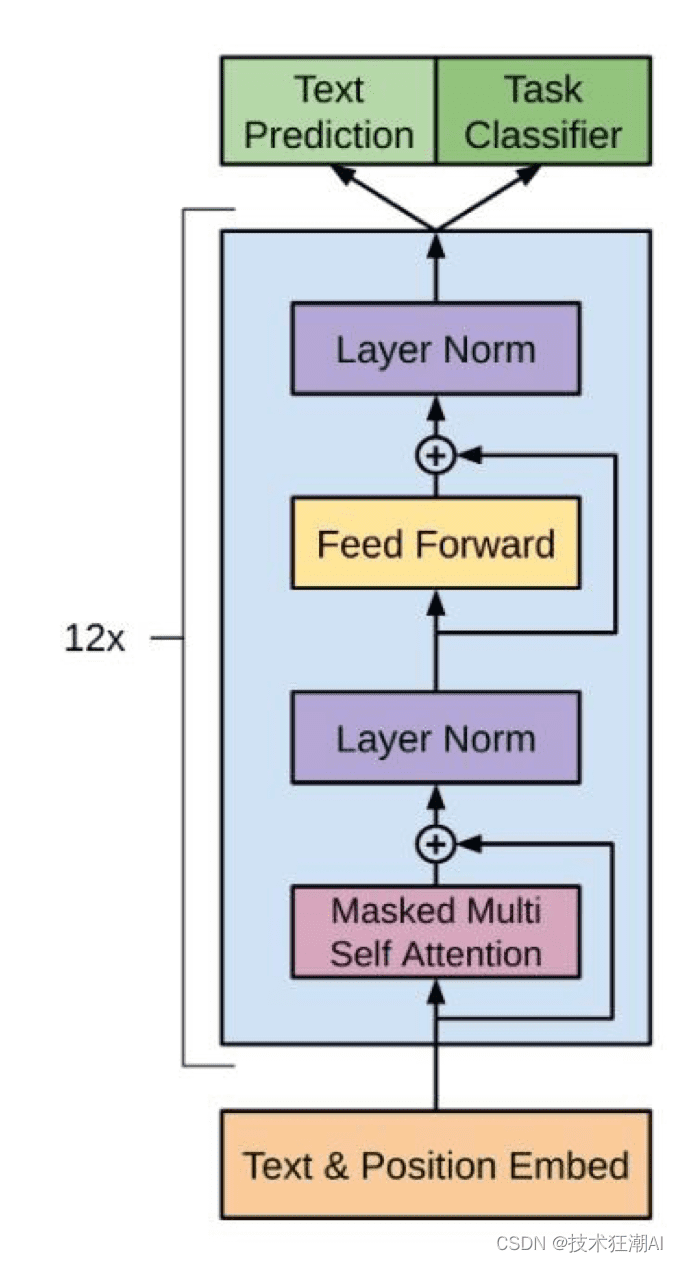
BERT(Bidirectional Encoder Representations from Transformers)和GPT-3是两个最经典的基于Transformer的预训练模型。BERT擅长于掌控全局,适用于自然语言推理任务,如情感分类、完形填空、命名实体识别、关系抽取等。GPT-3则专注于文本生成,更适用于聊天机器人或问答系统。
BERT只需要编码器的内容,不需要生成文本,而GPT是生成式的。
从GPT到ChatGPT的演变
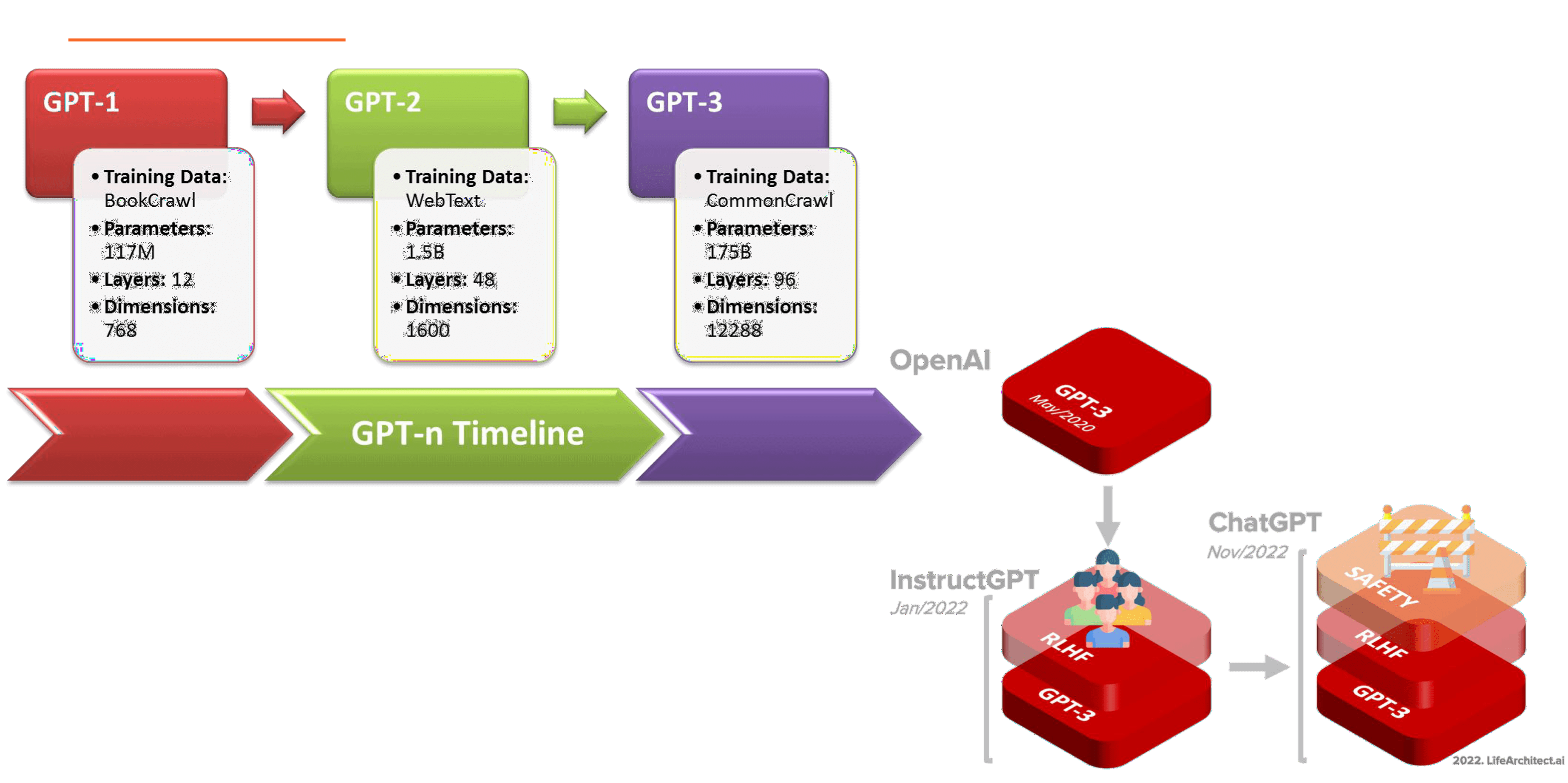
GPT是OpenAI的序列生成模型系列,能够产生高质量的自然语言文本。从GPT-1到GPT-3,参数数量呈指数级增长,使得模型能够更好地学习自然语言的规律,理解序列中的上下文信息,生成更连贯、更准确的文本。
ChatGPT是GPT-3模型在聊天机器人任务上的优化版本(GPT-3.5)。为了提升ChatGPT的性能,OpenAI对预训练数据集进行了微调,并增加了基于人类反馈的强化学习,使其更了解人类的需求,能够更好地处理用户提出的问题。此外,ChatGPT还增加了一层Safety Layer,以确保其回答合理且符合伦理规范。
ChatGPT的训练过程:基于人类反馈的强化学习
ChatGPT系列模型的基本思路是让AI在通用的数据上学习文字接龙,掌握生成后续文本的能力。这种训练方式无需人工标注,只需将大量的语料库输入模型,即可进行训练。
由于一个问题可能存在多个答案,为了获得更符合人类期望的答案,ChatGPT的训练过程中引入了人类指导,即基于人类反馈的训练(RLHF)。RLHF训练过程主要包括三个步骤:
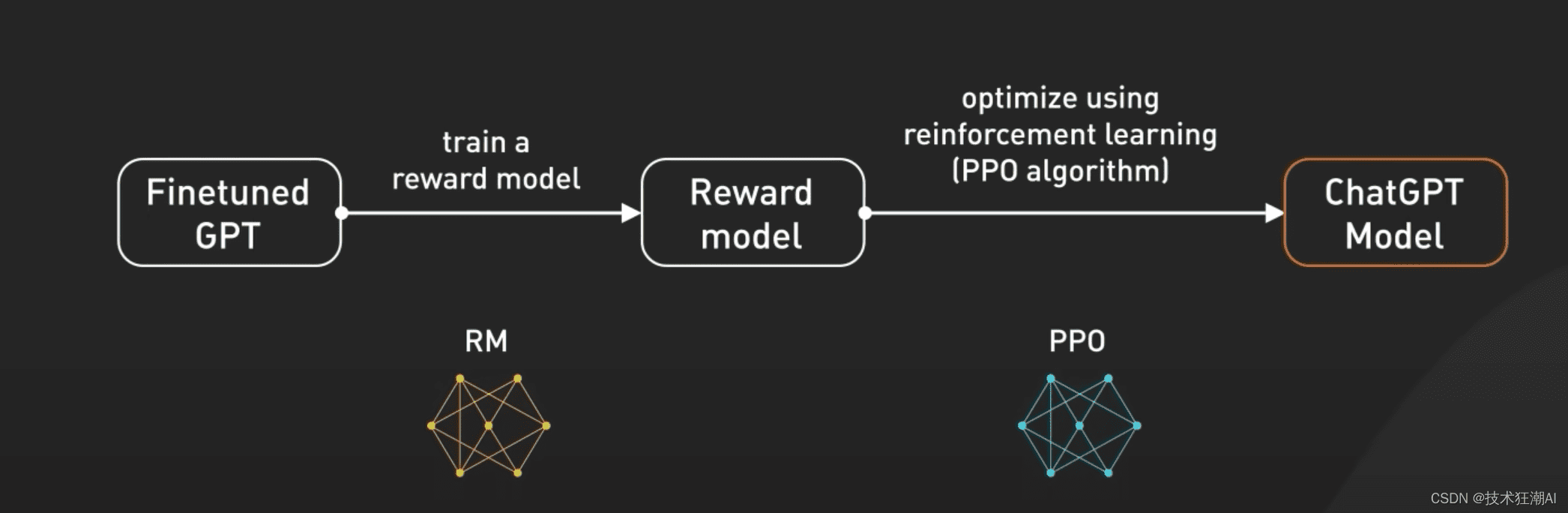
- 监督调优模型(SFT): 收集演示数据,使用监督学习训练生成规则。通过提供带有答案的问题,引导AI朝着人类期望的方向进行回答。
- 训练回报模型(Reward Model): 让ChatGPT输出多个答案,并基于生成的答案进行排序,人工标注出最佳答案。
- 使用PPO模型微调SFT模型: 通过PPO(Proximal Policy Optimization)强化学习算法,实现模型的自我优化。PPO算法通过让AI在不断试错的过程中自我调整优化策略,从而最大化预期的长期奖励。

通过以上三个步骤,一个真正的ChatGPT得以训练完成,能够生成更符合人类期望的回答。
总而言之,ChatGPT是人工智能领域的一项重要突破,它的出现为我们提供了一种全新的交互方式。虽然ChatGPT还存在一些局限性,但随着技术的不断发展,相信它将在未来发挥更大的作用。








