
随着人工智能技术的飞速发展,大型语言模型(LLM)正日益成为学术界和产业界关注的焦点。近日,国内首部由复旦大学团队编著的中文版大模型书籍正式面世,为广大读者提供了一扇深入了解LLM理论与实践的窗口。本文将对该书进行全面解读,探讨其核心内容、特色亮点以及对国内大模型研究的潜在影响。
书籍概述:
这本由复旦大学团队打造的中文书籍,全面且深入地探讨了大模型的相关知识。本书系统地梳理了LLM的发展历程,详细阐述了LLM的基本原理、关键技术和应用场景,并结合大量案例,深入剖析了LLM在自然语言处理、机器翻译、文本生成等领域的应用。该书还涵盖了大模型训练、优化和部署等方面的实践指导,为读者提供了从理论到实践的全面学习资源。
核心内容解读:
- LLM基础理论:
书籍首先从LLM的基本概念入手,介绍了神经网络、深度学习等相关理论。随后,详细阐述了Transformer模型的架构和原理,这是当前LLM最常用的模型结构。Transformer模型采用自注意力机制,能够捕捉文本中的长距离依赖关系,从而提高模型的性能。书中还深入探讨了Attention机制的各种变体,例如Multi-Head Attention、Scaled Dot-Product Attention等,帮助读者全面理解LLM的核心技术。
- LLM训练与优化:
训练LLM需要大量的计算资源和数据。本书详细介绍了LLM的训练方法,包括预训练、微调等。预训练是指使用大规模无标注数据训练模型,使其具备一定的语言理解能力。微调是指使用少量标注数据对预训练模型进行调整,使其适应特定的任务。书中还介绍了各种优化算法,例如Adam、SGD等,以及一些提高训练效率的技术,例如梯度累积、混合精度训练等。
- LLM应用场景:
LLM在自然语言处理领域有着广泛的应用,例如机器翻译、文本生成、问答系统等。本书详细介绍了LLM在这些领域的应用案例,并对各种应用场景进行了深入分析。例如,在机器翻译方面,LLM可以生成高质量的翻译结果,甚至可以实现零样本翻译。在文本生成方面,LLM可以生成各种类型的文本,例如新闻报道、小说、诗歌等。在问答系统方面,LLM可以根据用户的问题,从大量文本中找到答案。
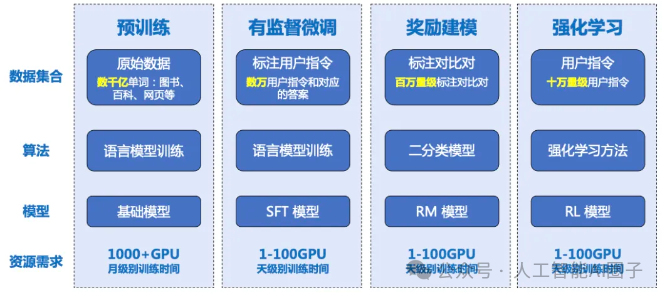
- LLM部署与实践:
将LLM部署到实际应用中需要考虑很多因素,例如计算资源、模型大小、推理速度等。本书介绍了各种LLM部署方法,包括CPU部署、GPU部署、TPU部署等。书中还介绍了一些模型压缩技术,例如剪枝、量化等,可以有效减小模型大小,提高推理速度。此外,书中还提供了一些LLM实践案例,帮助读者了解如何将LLM应用到实际项目中。
书籍特色亮点:
- 系统性与全面性:
该书系统地梳理了LLM的各个方面,从基础理论到应用实践,覆盖了LLM的各个重要环节。无论读者是初学者还是专业人士,都能从中获得有价值的信息。
- 实战性与可操作性:
书中结合大量案例,深入剖析了LLM在各个领域的应用。同时,该书还提供了详细的实践指导,帮助读者了解如何训练、优化和部署LLM。此外,书中还提供了大量的代码示例,方便读者进行实践。
- 前沿性与创新性:
该书紧跟LLM的最新发展动态,介绍了最新的技术和方法。例如,书中介绍了Prompt Engineering、In-Context Learning等新兴技术,这些技术可以有效提高LLM的性能。
对国内大模型研究的潜在影响:
- 推动LLM技术普及:
该书的出版将有助于推动LLM技术在国内的普及。通过阅读该书,更多的研究人员和工程师将能够了解LLM的基本原理、关键技术和应用场景,从而加速LLM技术在国内的发展。
- 促进LLM应用创新:
该书的出版将有助于促进LLM应用创新。通过学习该书中的案例和实践指导,更多的研究人员和工程师将能够将LLM应用到各种实际项目中,从而创造出更多的价值。
- 提升国内LLM研究水平:
该书的出版将有助于提升国内LLM研究水平。通过阅读该书,国内的研究人员可以了解国际上LLM研究的最新进展,从而更好地开展自己的研究工作。
总结:
复旦大学团队编著的这本中文版大模型书籍,是一本全面、系统、实战、前沿的LLM学习资源。该书的出版将有助于推动LLM技术在国内的普及、促进LLM应用创新、提升国内LLM研究水平。相信在不久的将来,LLM将在各个领域发挥更大的作用,为人类社会带来更多的福祉。
本书籍的发布,无疑为国内的大模型研究注入了一剂强心剂。它不仅为广大的AI爱好者和从业者提供了一个系统学习的平台,更为国内大模型技术的自主创新和发展奠定了坚实的基础。随着越来越多的研究者和开发者加入到大模型的探索中来,我们有理由相信,中国的大模型技术将在世界舞台上绽放出更加绚丽的光彩。未来的AI世界,值得我们共同期待。
教程内容概要:
该书还附带了详细的教程,内容涵盖了以下几个方面:
- 环境搭建:
介绍如何搭建LLM开发环境,包括安装Python、TensorFlow、PyTorch等必要的软件和库。
- 数据准备:
介绍如何准备LLM训练数据,包括数据清洗、数据标注等。
- 模型训练:
介绍如何使用TensorFlow或PyTorch训练LLM,包括模型定义、损失函数定义、优化器选择等。
- 模型评估:
介绍如何评估LLM的性能,包括使用各种评估指标,例如BLEU、ROUGE等。
- 模型部署:
介绍如何将LLM部署到实际应用中,包括使用各种部署工具,例如TensorFlow Serving、TorchServe等。








