
深入剖析ChatGPT:原理、应用与未来趋势
在人工智能领域,ChatGPT无疑是最耀眼的明星之一。它不仅能流畅地进行对话,还能创作文章、编写代码,甚至进行创意性的文本生成。那么,ChatGPT究竟是如何实现的?它的背后蕴藏着怎样的技术原理?本文将深入剖析ChatGPT,揭示其核心技术、应用场景以及未来的发展趋势。
ChatGPT是什么?
ChatGPT,全称为Generative Pre-trained Transformer,即生成式预训练变换模型。它是由OpenAI开发的一种自然语言处理(NLP)模型,其核心功能是根据输入的文本生成自然语言回复。简单来说,ChatGPT是一个基于人工智能技术的语言模型,它能够理解人类的语言,并以自然、流畅的方式进行回应。
GPT中的“生成式”意味着什么?
在ChatGPT中,“生成式”指的是模型能够自主地生成新的文本序列。这与传统的NLP模型有所不同,后者主要用于文本分类、情感分析等任务,而ChatGPT则具备更强的创造性,能够根据输入的提示或指令,生成全新的、原创的文本内容。这种生成能力使得ChatGPT在文本摘要、机器翻译、对话系统、自动写作等领域具有广泛的应用前景。
生成式AI的应用正在改变许多行业。从自动摘要到文本生成,从语音合成到自然语言理解,从图像生成到计算机视觉,生成式AI正在为各个领域带来新的可能性。
GPT中的“预训练”是什么意思?
“预训练”是指模型在正式应用之前,先在一个大规模的语料库上进行无监督学习,从而学习到通用的语言知识。这个过程就像人类在学习新知识之前,需要先掌握一些基础概念和常识。通过预训练,ChatGPT能够学习到大量的自然语言文本,从而捕捉到语言的语法、结构和语义等方面的规律。这使得它在面对各种不同的任务时,能够更快地适应并取得更好的效果。
预训练模型(Pre-trained Model)已经过大量语料库的训练,可以针对各种任务和领域进行优化,从而在性能上比传统的全手动训练模型更加优越。
GPT中的“变换模型”指的是什么?
“变换模型”(Transformer)是一种基于自注意力机制的神经网络结构,由Google在2017年提出。它主要用于处理序列到序列的任务,例如机器翻译、文本生成、语言模型等。传统的循环神经网络(RNN)和长短期记忆网络(LSTM)在处理序列数据时,容易出现梯度消失或梯度爆炸的问题,导致模型难以训练和效果不佳。而变换模型则引入了新的变换方式,如位置编码、注意力机制等,使得模型能够更好地捕捉序列数据中的长期依赖关系。
变换模型在自然语言处理领域中应用广泛,特别是在机器翻译、文本分类、语言模型等任务中取得了非常好的效果。同时,变换模型的结构也被广泛应用到其他领域,例如图像处理、语音识别等任务中,成为了一种重要的神经网络结构。
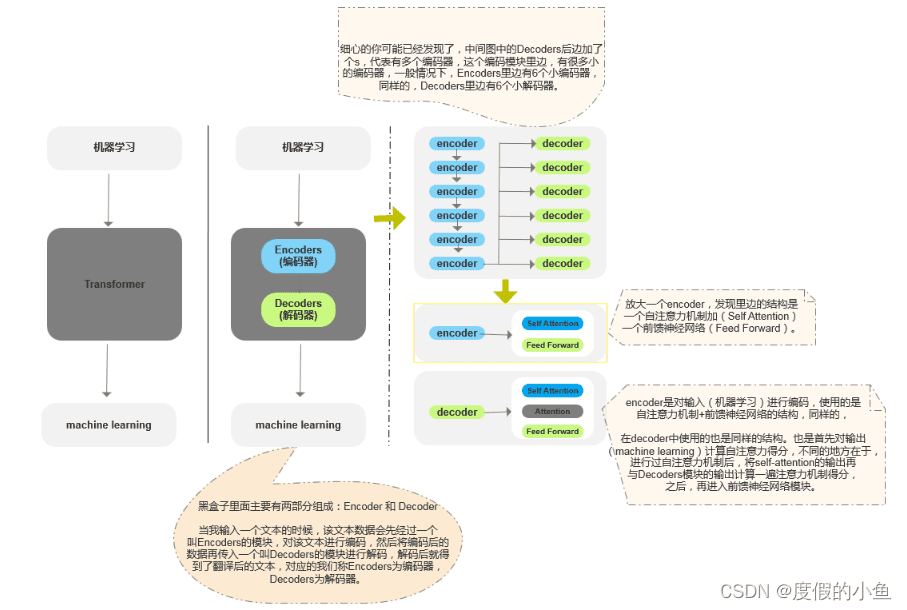
深入理解Transformer架构
Transformer架构是ChatGPT的核心组成部分。它是一种基于自注意力机制的神经网络结构,能够有效地处理序列数据,并捕捉序列中的长期依赖关系。Transformer架构主要由编码器(Encoder)和解码器(Decoder)组成。
- 编码器:负责将输入的文本序列转换为一种中间表示,这种表示能够捕捉文本的语义信息。
- 解码器:负责将编码器生成的中间表示转换为目标文本序列。在机器翻译任务中,目标文本序列就是翻译后的文本;在文本生成任务中,目标文本序列就是生成的文本。
什么是注意力机制?
注意力机制(Attention Mechanism)是一种神经网络结构,用于计算输入序列中不同部分之间的重要性,并将其应用于不同的自然语言处理任务中。在自然语言处理中,注意力机制可以用于计算每个单词在上下文中的重要性,并将这些重要性应用于模型的输出中。例如,在机器翻译任务中,输入是源语言的一句话,输出是目标语言的一句话。注意力机制可以帮助模型关注源语言中与目标语言相关的部分,并将其翻译为目标语言。
让我们用一个例子来解释下Transformer模型中的注意力机制。 比如你正在学习一个英文句子:"The cat sat on the mat"想要将其翻译成中文。当Transformer模型对这个句子进行编码时,它会将句子中每个单词表示成一个向量,然后将这些向量输入到一个注意力机制中。
注意力机制会计算每个单词与其他单词的相关性,并给它们分配一个注意力权重。在这个例子中,注意力机制可能会将“cat"和"mat"之间的关系分配更高的权重,因为它们之间有一个"on the"短语,而这个短语对于理解整个句子的意思非常重要要。然后,这些注意力权重会被用来对单词向量进行加权产生一个加权向量,表示整个输入序列的含义。
在翻译过程中,这个加权向量会被传递到解码器中,解码器会根据这个加权向量生成对应的中文句子。这样,注意力机制就可以帮助Transformer模型集中注意力在输入序列中最重要的部分上,从而更好地理解输入序列和生成输出序列。
监督学习、无监督学习与强化学习
生成式AI,如ChatGPT,主要依赖于以下三种机器学习方法:
监督学习:在预训练过程中,模型使用一组监督信号进行训练。这些信号可以是真实的文本数据,也可以是一些标注数据,用来指示模型应该生成怎样的输出。通过在训练过程中使用这些监督信号,可以帮助模型更好地学习语言模式和知识,并生成更加自然和准确的输出。
无监督学习:生成式模型不需要标签来指定输入数据的类别,而是利用输入数据本身的特征进行训练。ChatGPT通过阅读大量的无标签文本数据,学习语言的结构、语法和语义信息。
强化学习:生成式模型可以通过尝试不同的行动来学习,就像在现实世界中一样,它可以通过尝试不同的行动来学习最佳策略。

ChatGPT的应用场景
ChatGPT的应用非常广泛,涵盖了多个领域:
- 自动摘要:ChatGPT可以根据一篇长篇文章,自动生成简洁、准确的摘要,帮助用户快速了解文章的核心内容。
- 文本生成:ChatGPT可以根据用户的需求,生成各种类型的文本,例如新闻报道、小说、诗歌等。
- 语音合成:ChatGPT可以将文本转换为自然、流畅的语音,实现文本到语音的转换。
- 自然语言理解:ChatGPT可以理解人类的语言,并根据用户的意图,执行相应的操作。
- 图像生成:ChatGPT可以根据文本描述,生成相应的图像,实现文本到图像的转换。
- 计算机视觉:ChatGPT可以分析图像中的内容,并根据图像的特征,生成相应的描述。
ChatGPT的未来发展趋势
随着人工智能技术的不断发展,ChatGPT的未来发展趋势主要集中在以下几个方面:
- 模型规模更大:未来的ChatGPT模型将拥有更大的参数规模,能够学习到更多的语言知识,并生成更加自然、流畅的文本。
- 训练数据更多:未来的ChatGPT模型将使用更多的训练数据,能够覆盖更广泛的领域,并提高模型的泛化能力。
- 应用场景更广:未来的ChatGPT模型将在更多的领域得到应用,例如医疗、金融、教育等。
- 人机交互更自然:未来的ChatGPT模型将能够实现更自然、流畅的人机交互,使用户能够更加方便地使用ChatGPT。
结语
ChatGPT作为一种强大的自然语言处理模型,正在深刻地改变着我们与计算机交互的方式。随着技术的不断进步,ChatGPT将在更多的领域发挥作用,为人类带来更多的便利和创新。让我们拭目以待,共同迎接人工智能时代的到来。








