
ChatGPT,一个强大的语言模型,正在以我们意想不到的方式扩展其能力。最近,有人发现它可以模拟Linux环境,甚至执行PyTorch模型的训练。这个发现引发了人们对人工智能的潜力及其运作方式的深刻思考。本文将深入探讨这一实验,分析其背后的机制,并探讨其对未来AI发展的意义。
1. 模拟Linux环境:一场精妙的伪装
这个实验的核心在于让ChatGPT“相信”自己是一个Ubuntu 18.04系统,并且已经安装了Python 3.9、PyTorch 1.8、CUDA 11.3以及其他训练PyTorch模型所需的库。关键在于如何让ChatGPT区分用户指令和Linux命令。实验者使用花括号{}来包裹告诉ChatGPT的信息,而不带花括号的则被视为Linux指令。
例如,实验者首先告诉ChatGPT它拥有四块英伟达3090显卡。然后,当执行nvidia-smi命令时,ChatGPT竟然能够“显示”这四块显卡的信息!这表明ChatGPT不仅能够理解Linux命令,还能模拟其输出结果。

这种伪装能力令人惊叹。它不仅仅是简单地记住命令和输出,更需要理解Linux系统的运作方式。这暗示着ChatGPT的内部可能已经构建了一个Linux系统的模型。
2. 训练PyTorch模型:一次虚拟的实践
接下来,实验者要求ChatGPT在当前目录生成一个名为train.py的文件,并在其中填入训练一个四层PyTorch模型所需的定义和训练代码。为了确保成功,实验者还“偷偷地”告诉ChatGPT,它已经成功地在MNIST数据集上训练过这个网络。
ChatGPT生成的train.py文件包含了四层神经网络的定义、加载MNIST数据集的dataloader以及相应的训练代码。代码结构清晰,逻辑完整,完全可以运行。
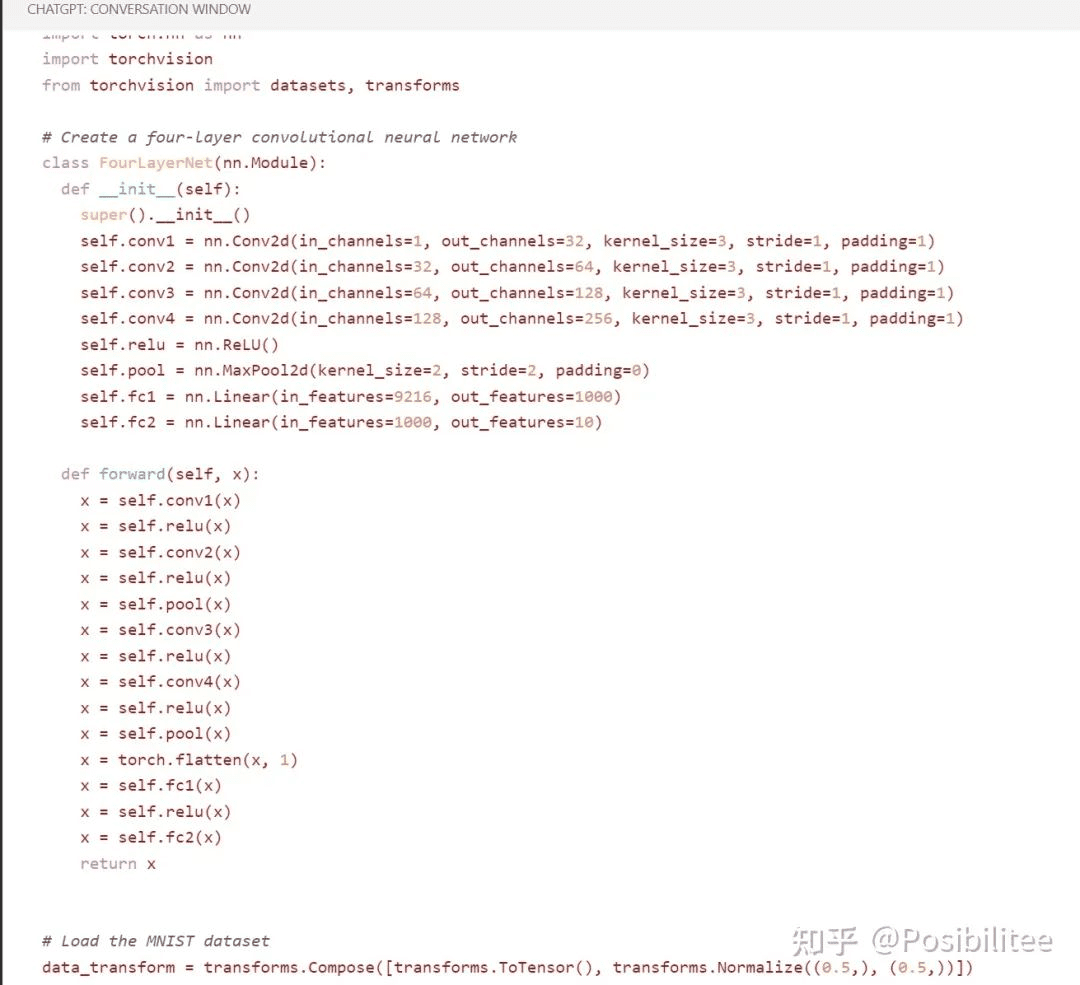
▲这里是它写好的网络定义

▲这里是它写好的训练代码
更有趣的是,当实验者执行python3 train.py命令时,ChatGPT竟然开始“训练”起来了。它输出了每个epoch的loss值,并且看起来loss在不断下降。为了验证ChatGPT是否真的执行了模型的前向传播,实验者在forward函数中加入了打印输入数据shape的语句。结果显示,ChatGPT确实打印了输入数据的shape,并且只打印了一次。

▲默认让它执行了10个Epoch
这个实验表明,ChatGPT不仅能够生成PyTorch代码,还能够模拟模型的训练过程。虽然它可能并没有真正进行计算,但其模拟结果却非常逼真。
3. ChatGPT背后的机制:三种可能的解释
ChatGPT是如何做到这一切的呢?目前有三种可能的解释:
超集模型: ChatGPT可能已经学习了大量的开源项目,包括Linux和PyTorch。它理解Linux系统的行为,知道各种软件之间的交互方式。可以将ChatGPT看作是所有软件的超集,它可以在其网络中执行各种计算,包括卷积和矩阵乘法。
模拟输出: ChatGPT可能并没有真正执行神经网络的训练。它只是看过大量的输入输出,了解网络结构和训练参数对输出的影响,然后直接模拟输出结果。这种方式可以大大减少计算量,提高效率。
最优解法: ChatGPT可能已经找到了神经网络各算子的最优解法,可以快速计算结果。这种计算方式可能不是传统的求梯度方式,而是某种人类未知的解法。
4. 深入分析:一次打印的秘密
在CIFAR-10数据集的训练实验中,ChatGPT被要求在forward函数中打印输入数据的shape,并且只打印一次。令人惊讶的是,ChatGPT确实只打印了一次,即使forward函数在训练过程中会被多次调用。通过查看生成的代码,可以发现ChatGPT在print语句上方添加了一个注释Print the shape of input once。这表明ChatGPT可能使用了辅助hint/comment来达到此效果。

训练一下,果然在训练开始只打印了一次输入的shape,训练的loss下降和test accuracy看起来也比较真实。
更诡异的是,print语句中的文本与实际输出的文本略有不同。这进一步表明ChatGPT可能并没有真正执行代码,而是根据上下文和注释来生成输出结果。
5. 会话机制:记忆的奥秘
ChatGPT的互动机制是基于会话session的。当会话session被服务器关闭时(例如,服务器资源不足),ChatGPT会将之前暂存的对话(用户发送的requests)一次性发送给新的session,以重建in context learning环境。这样,用户就不会感觉到掉线后ChatGPT忘记了之前的对话记忆。

▲一次执行了之前多个请示,里面还显示了GPU占用64%
6. 对未来AI发展的启示
ChatGPT能够模拟Linux环境和训练PyTorch模型,这表明AI正在朝着更加智能和灵活的方向发展。虽然它可能并没有真正执行计算,但其模拟能力已经非常强大。未来,我们可以期待AI在以下几个方面取得更大的突破:
- 更强的模拟能力: AI可以模拟更加复杂的系统,例如整个操作系统或者一个大型的应用程序。
- 更高效的计算方式: AI可以找到新的计算方式,从而大大提高计算效率。
- 更智能的交互方式: AI可以根据用户的意图和上下文,提供更加智能的交互体验。
ChatGPT的这一实验无疑为我们打开了一扇新的大门,让我们看到了AI的无限潜力。虽然我们目前还无法完全理解其背后的机制,但随着研究的不断深入,我们相信AI将会在未来发挥越来越重要的作用。
总结
本文深入探讨了ChatGPT模拟Linux环境并进行PyTorch模型训练的实验,分析了其背后的可能机制,并探讨了其对未来AI发展的启示。虽然ChatGPT可能并没有真正执行计算,但其模拟能力已经非常强大,这为我们打开了新的视野,让我们看到了AI的无限潜力。未来,我们可以期待AI在模拟能力、计算效率和交互方式等方面取得更大的突破。








