
深入探索ChatGPT:原理、应用与未来趋势
随着人工智能技术的飞速发展,ChatGPT作为一种先进的自然语言处理工具,正日益受到广泛关注。本文将深入探讨ChatGPT的底层逻辑、实现原理、应用场景,并展望其未来发展趋势。
一、初识ChatGPT:定义与本质
ChatGPT,全称Generative Pre-trained Transformer,是一种基于GPT模型的对话生成系统。它本质上是一种自动编码器语言模型,能够对单词、句子和段落进行预测和生成。作为目前最先进的自然语言处理技术之一,ChatGPT将GPT模型应用于对话生成领域,模拟人类对话行为,实现智能问答、聊天机器人等应用。简单来说,ChatGPT就是一个强大的文字生成器。
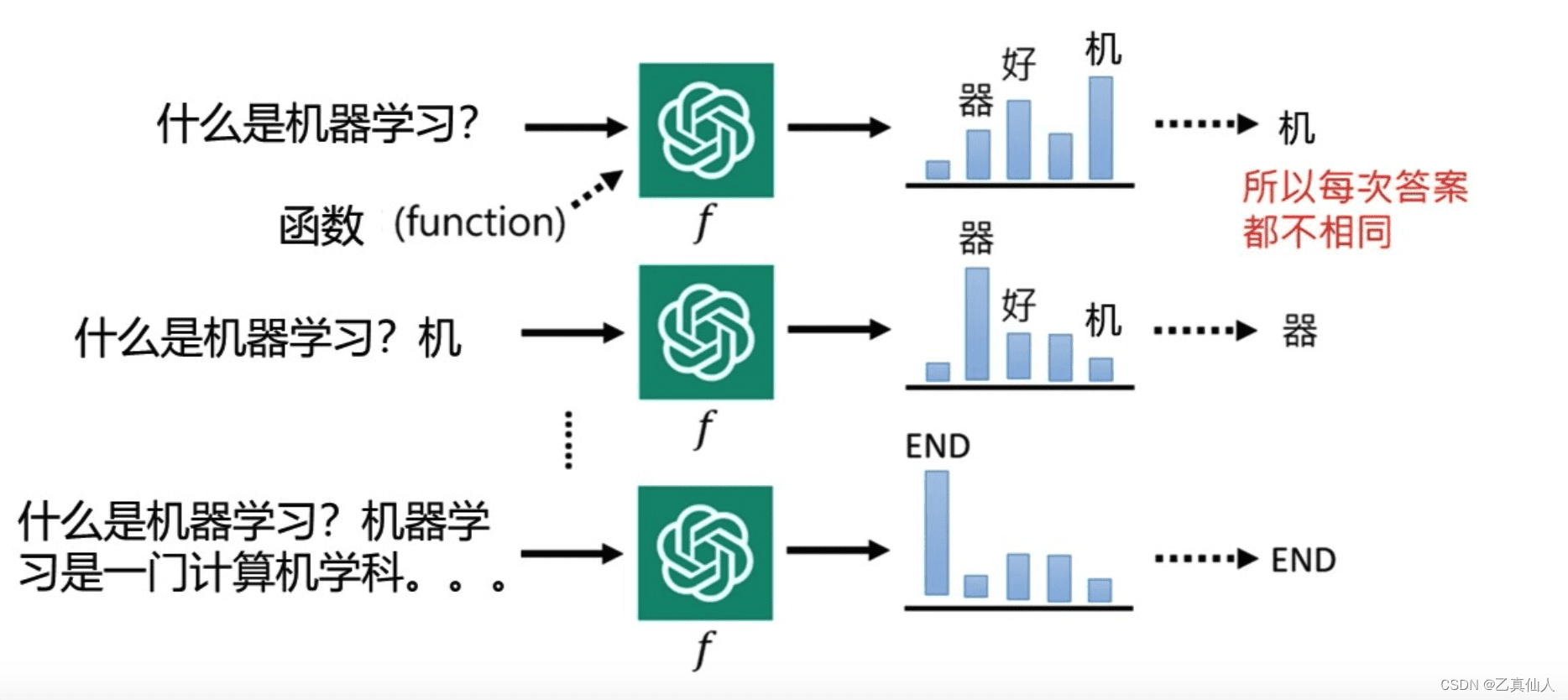
ChatGPT之所以能实现如此复杂的人类意图,得益于机器学习、神经网络以及Transformer模型等多种技术的长期积累。这些技术共同构建了一个针对人类反馈信息学习的大模型预训练语言模型。
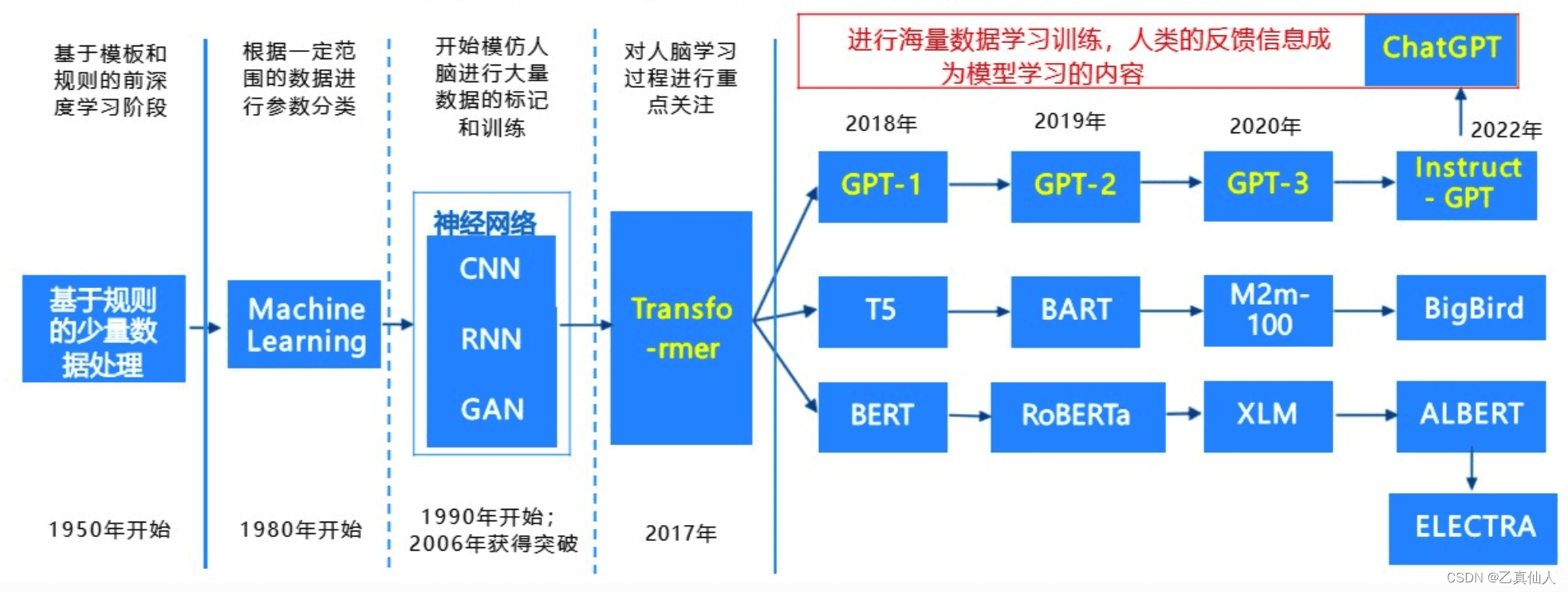
二、ChatGPT的底层逻辑:原理剖析
2.1 实现原理:Transformer架构与深度学习
ChatGPT是基于深度学习的语言模型,采用了Transformer架构。其实现原理主要包括以下几个关键步骤:
- 数据集和预训练:ChatGPT的训练需要海量的文本数据集,包括互联网上的公开数据集、对话记录、书籍等。在预训练阶段,ChatGPT通过大量的自监督学习任务(如遮蔽语言建模)来学习语言的统计规律。自监督学习让模型能够从原始文本中自动学习,无需人工标注,大大提高了训练效率。
- Transformer架构:ChatGPT使用了Transformer模型架构,它由多个编码器层和解码器层组成。编码器负责将输入序列转换为隐藏表示,解码器则根据隐藏表示生成输出序列。Transformer架构通过自注意力机制(self-attention)来捕捉输入序列的上下文依赖关系,从而提高了模型表达能力。自注意力机制使得模型能够关注到输入序列中的不同部分,更好地理解语境。
- 微调和对话生成:在预训练完成后,ChatGPT通过微调阶段来进一步调整模型参数,使其适应特定的任务,如对话生成。微调阶段通常使用特定的对话数据集,其中包含了问题和回答的对应关系。通过在这些数据上进行有监督学习,ChatGPT学会了根据问题生成合理的回答。微调过程可以针对特定领域的知识进行优化,提高模型在特定任务上的表现。
- 上下文处理:ChatGPT能够理解对话的上下文是因为Transformer架构中的自注意力机制,它使模型能够关注到输入序列中的其他部分,从而更好地理解整个对话上下文。ChatGPT会根据之前的对话历史来生成回答,以保持连贯性。上下文处理能力是ChatGPT能够进行自然流畅对话的关键。
- 生成策略:ChatGPT使用一种基于概率的生成策略,通过对词汇表中的词进行采样,从而生成回答。这种生成策略使得ChatGPT能够在一定程度上具备创造性,但也可能导致一些不准确或不符合语境的回答。生成策略的设计需要在创造性和准确性之间找到平衡。

尽管ChatGPT在很多情况下能够生成有意义的回答,但它并不具备真正的理解和推理能力。ChatGPT是通过大量的训练数据来学习统计规律,并且没有对特定领域的专业知识进行注入。因此,在使用ChatGPT时,我们需要仔细审查和验证其输出,以确保其准确性和可靠性。未来的发展方向之一是将外部知识库与ChatGPT结合,提高其专业知识水平。
2.2 IO流程:文本生成的步骤
ChatGPT进行文本内容生成通常可以分为以下几个步骤:
- 输入处理:ChatGPT接收到用户的输入文本后,首先对其进行预处理。这可能包括分词、标记化和向量化等操作,将输入文本转换为模型可以理解和处理的形式。分词是将文本分割成独立的词语,标记化是为每个词语分配唯一的ID,向量化是将词语转换为数值向量,方便模型计算。
- 编码器处理:ChatGPT使用编码器部分来处理输入文本。编码器将输入文本的表示转换成隐藏表示,捕捉输入中的语义信息和上下文关系。这一步通常是通过多层的自注意力机制(self-attention)实现的,使得模型能够对输入序列中不同位置的单词进行关注和权重分配。编码器的作用是将输入的文本转换为一种高度概括性的表示,捕捉文本的核心含义。
- 解码器处理:在编码器处理完输入后,ChatGPT将隐藏表示传递给解码器部分。解码器利用隐藏表示生成输出文本的方式有许多种,其中一个常见的方式是使用自注意力机制结合逐词生成(autoregressive generation)。解码器根据已生成的部分文本以及编码器的隐藏表示,按照一定的规则和概率分布预测下一个要生成的单词。解码器通过不断预测下一个词语,逐步生成完整的文本。
- 采样策略:在生成文本时,ChatGPT采用不同的策略来选择生成的下一个单词。其中一个常见的策略是使用softmax函数将模型输出的概率分布转化为生成概率,并基于这个概率分布进行采样。通过在模型输出的概率分布中选择具有较高概率的单词,ChatGPT可以生成连贯、多样性的文本,但也可能导致一些重复或不符合语境的情况。采样策略的选择对生成文本的质量和多样性有重要影响。
- 重复步骤:生成下一个单词后,ChatGPT将其作为输入的一部分,再进行编码器处理和解码器处理的循环迭代,生成更长的文本序列,直至达到预定的生成长度或生成终止条件。这个循环迭代的过程使得模型能够逐步完善生成的文本,使其更加连贯和完整。

需要注意的是,这只是ChatGPT文本生成的一般流程,实际应用中会根据不同的任务和需求进行调整和优化。例如,可以加入一些约束条件来控制生成文本的风格和内容。同时,在生成文本时,也需要注意对输出进行限制和过滤,以确保生成的文本满足特定的要求和约束,例如避免生成有害或不当内容。
三、ChatGPT的应用场景:无限可能
ChatGPT的应用场景非常广泛,涵盖了问答、对话、文本生成、智能客服和智能编程等多个领域。以下是ChatGPT的一些典型应用场景:
3.1 知心好友:情感陪伴与交流
ChatGPT可以作为用户的知心好友,提供情感陪伴和交流。用户可以与ChatGPT分享生活中的喜怒哀乐,ChatGPT会根据用户的情绪提供安慰和建议。这种应用场景对于那些缺乏社交支持的人来说尤为重要。

3.2 文案助理:高效的内容生成工具
ChatGPT可以作为文案助理,帮助用户快速生成各种类型的文本,例如文章、新闻稿、营销文案等。用户只需要提供一些关键词或主题,ChatGPT就可以自动生成高质量的文案,大大提高工作效率。例如,可以利用ChatGPT快速生成产品描述、广告语等。

3.3 创意助理:激发灵感的源泉
ChatGPT可以作为创意助理,帮助用户激发灵感,提供各种创意方案。例如,用户可以向ChatGPT提出一个问题或挑战,ChatGPT会生成各种可能的解决方案,帮助用户拓展思路。这种应用场景对于那些需要创意灵感的人来说非常有价值。可以利用ChatGPT进行头脑风暴,产生新的想法和概念。

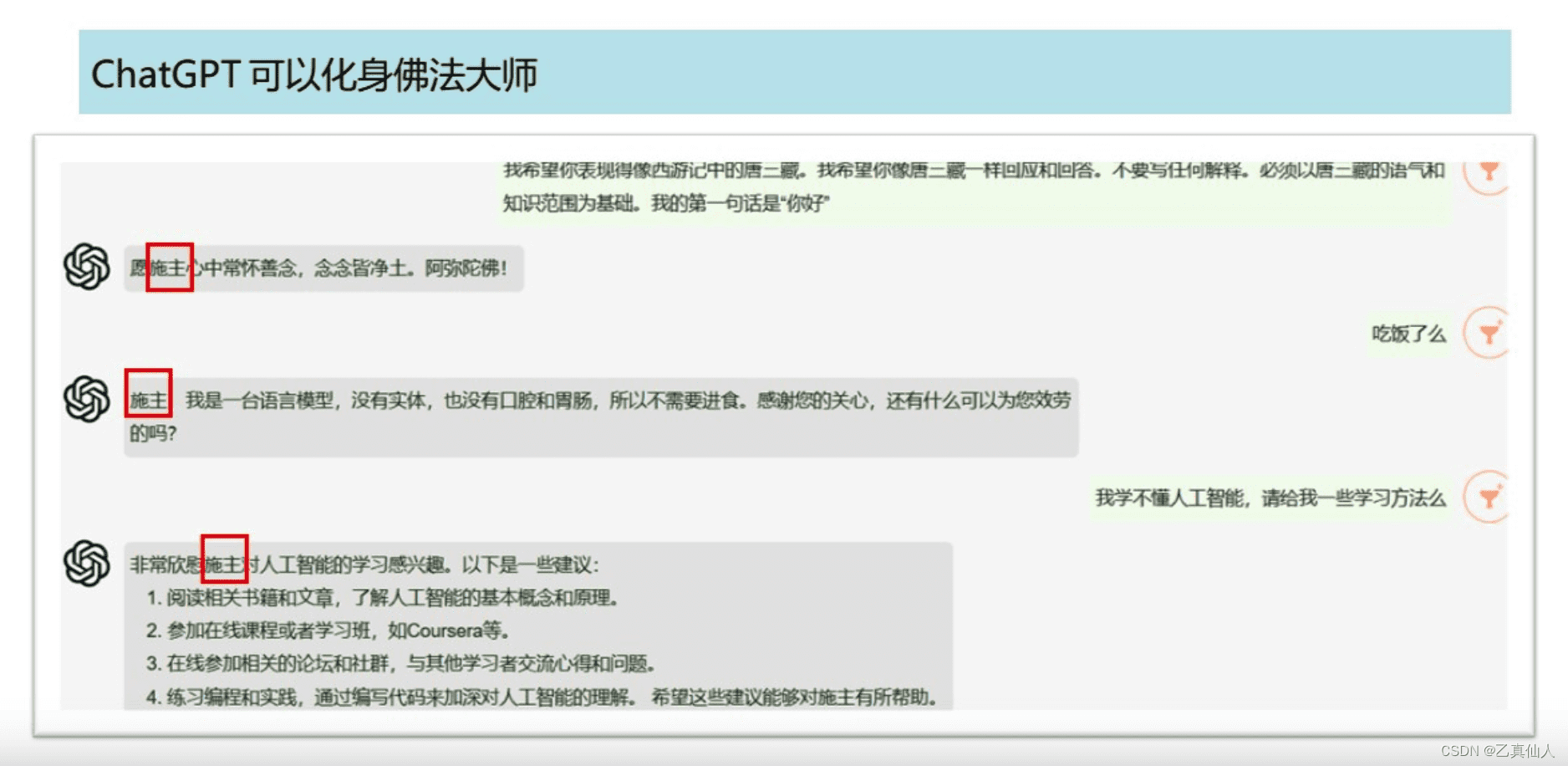
3.4 角色扮演:模拟不同身份与情境
ChatGPT可以进行角色扮演,模拟不同身份和情境,为用户提供沉浸式的体验。例如,用户可以让ChatGPT扮演一个历史人物、科幻角色或虚拟助手,与用户进行对话互动。这种应用场景可以用于娱乐、教育和培训等领域。例如,可以利用ChatGPT进行虚拟客服培训,提高客服人员的沟通技巧。
四、ChatGPT的局限性与未来展望
尽管ChatGPT在自然语言处理领域取得了显著进展,但它仍然存在一些局限性。例如,ChatGPT可能会生成不准确或不符合语境的回答,缺乏真正的理解和推理能力。此外,ChatGPT的训练需要大量的计算资源和数据,对环境造成一定的负担。
未来,ChatGPT的发展方向包括:
- 提高准确性和可靠性:通过改进模型结构、优化训练方法和引入外部知识库,提高ChatGPT生成回答的准确性和可靠性。
- 增强理解和推理能力:研究新的模型架构和算法,使ChatGPT能够更好地理解和推理用户的意图。
- 降低计算成本和环境影响:开发更高效的模型和训练方法,降低ChatGPT的计算成本和环境影响。
- 拓展应用领域:将ChatGPT应用于更多领域,例如医疗、金融和教育等,为人们提供更智能、更便捷的服务。
总之,ChatGPT作为一种先进的自然语言处理工具,具有广阔的应用前景。随着技术的不断发展,ChatGPT将在未来发挥更加重要的作用。








