
近年来,人工智能(AI)领域最引人瞩目的进展之一莫过于大型AI模型的崛起。这些模型凭借其庞大的参数规模和卓越的性能,正在重塑各个行业,并为解决复杂问题提供了前所未有的可能性。本文将深入探讨AI大模型的定义、发展历程、使用方法、关键构成、应用领域以及未来发展趋势,旨在为读者提供一个全面而深入的理解。
AI大模型:概念解析
AI大模型指的是拥有数百万甚至数千亿参数的人工智能模型,它们通过深度学习技术,能够从海量数据中学习并提取复杂的模式和规律。这些模型通常基于深度神经网络架构,如Transformer,能够处理各种复杂的任务,例如自然语言处理、图像识别、语音识别等。与传统的机器学习模型相比,AI大模型具有更强的学习能力和泛化能力,能够在各种任务上展现出卓越的性能。简而言之,AI大模型就像一个拥有巨大知识库和强大推理能力的“超级大脑”,能够处理各种复杂的问题。
随着深度学习技术的快速发展和计算能力的不断提升,AI大模型已经成为人工智能领域的重要发展方向。它们能够更好地理解和模拟人类的思维方式,从而实现各种任务的自动化处理。这些模型不仅在学术研究中取得了重大突破,也在工业界和商业应用中发挥着越来越重要的作用。
AI大模型的发展历程
AI大模型的发展并非一蹴而就,而是经历了多个阶段的演进。以下是其发展历程的简要回顾:
深度学习的兴起(21世纪初):随着计算机硬件性能的提升和数据规模的增加,深度学习技术开始崭露头角。神经网络模型在图像识别、语音识别等领域取得了突破性进展,引发了学术界和工业界对人工智能的新一轮兴趣。这一阶段为AI大模型的发展奠定了基础。
Transformer模型的提出(2017年):Transformer模型是一种基于注意力机制的深度学习模型,它在自然语言处理任务中表现出色,并为后续的AI大模型奠定了基础。Transformer模型的出现标志着注意力机制在深度学习中的重要性,并为后续的模型架构设计提供了新的思路。
GPT模型的问世(2018年):基于Transformer架构的自回归式语言模型GPT模型问世,在自然语言处理任务中表现出色,吸引了广泛的关注,成为AI大模型发展的重要标志之一。GPT模型的成功证明了大规模预训练模型在自然语言处理领域的巨大潜力。
BERT模型的提出(2018年底):Google提出了BERT(Bidirectional Encoder Representations from Transformers)模型,它通过预训练和微调的方式,显著提升了自然语言处理任务的性能,成为自然语言处理领域的重要突破之一。BERT模型的出现改变了自然语言处理的研究范式,并为后续的模型发展提供了新的方向。
大规模预训练模型的涌现(近年来):随着计算资源和数据规模的进一步增加,大规模预训练模型如GPT-3、BERT-large等相继问世。这些模型拥有巨大的参数规模和强大的学习能力,成为当前人工智能领域的研究热点。它们在自然语言处理、图像识别、语音识别等领域的应用逐渐拓展,并涉及到更多的应用场景和行业。
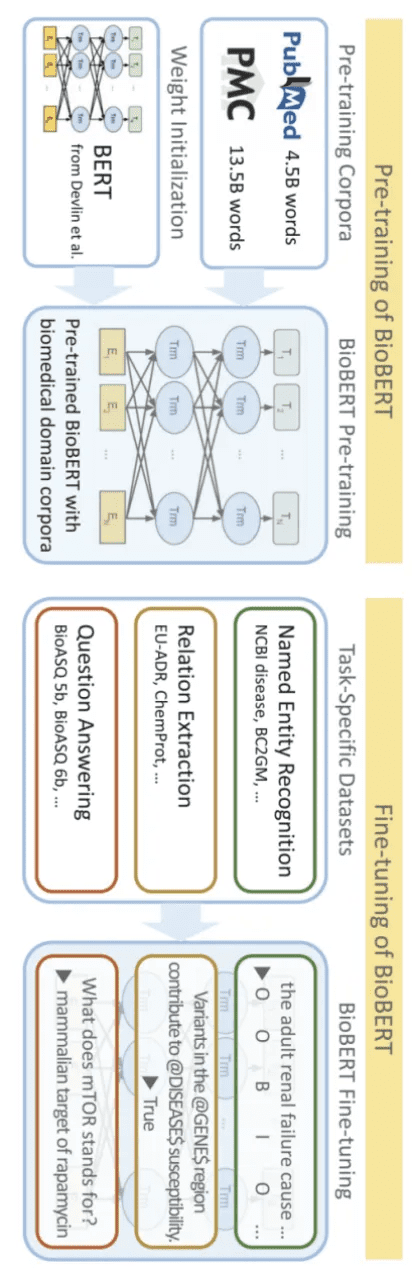
AI大模型的使用方法
使用AI大模型通常包括以下几个步骤:
数据准备:准备大规模的训练数据,包括文本、图像、语音等。数据的质量和数量对模型的性能至关重要。
模型选择:选择适合特定任务的AI大模型,如GPT模型用于自然语言生成任务,BERT模型用于文本分类任务等。选择合适的模型是成功应用AI大模型的关键。
模型训练:使用准备好的数据对选定的AI大模型进行训练,调整模型参数以最大程度地适应特定任务的需求。模型训练需要大量的计算资源和时间。
模型评估:评估训练后的模型在测试数据集上的性能,包括准确率、召回率、F1值等指标。模型评估可以帮助我们了解模型的优缺点,并进行相应的改进。
模型部署:将训练好的模型部署到实际应用中,供用户使用。模型部署需要考虑模型的性能、安全性、可扩展性等因素。
AI大模型的主要内容
AI大模型的核心在于其庞大的参数规模和复杂的神经网络结构,以及通过大规模数据的预训练来获得通用的语言或知识表示。这些特点使得AI大模型能够在各种任务中展现出色的性能,并且具有较高的通用性和灵活性。
庞大的参数规模:AI大模型通常由数百万到数十亿个参数组成,这些参数用于存储模型学习到的信息和知识。参数的规模越大,模型就能够表示更多、更复杂的信息,从而在各种任务中获得更好的性能。
复杂的神经网络结构:AI大模型通常采用深度神经网络结构,如Transformer架构等。这些网络结构通过多层次的非线性变换和激活函数,能够提取数据中的高阶特征,并建立起特征之间的复杂关系。这种复杂的网络结构使得AI大模型能够学习到更深层次、更抽象的表示,从而实现更复杂的任务处理。
大规模数据的预训练:AI大模型通过大规模数据的预训练来获得通用的语言或知识表示。在预训练阶段,模型通过大规模的文本、图像或者其他类型的数据进行无监督学习,从而学习到通用的语言或知识表示。这些表示能够捕捉数据中的各种模式和规律,从而为后续的任务处理提供了基础。通过预训练,模型可以获得丰富的语言或知识表示,使得其在各种任务上都能取得较好的性能。
AI大模型的应用前景
AI大模型相比传统模型有更好的性能、更高的通用性、更快的部署速度和更加广泛的应用范围,使其具有广阔的应用前景。以下是AI大模型的一些主要应用领域:
自然语言处理:AI大模型在自然语言处理领域的应用最为广泛,包括文本生成、文本分类、语义理解、机器翻译和信息检索等。例如,GPT模型可以用于生成各种类型的文本,如文章、诗歌、代码等;BERT模型可以用于文本分类、情感分析等任务。
图像识别:AI大模型可以用于图像识别、目标检测、图像生成等任务。例如,ResNet模型可以用于图像分类;YOLO模型可以用于目标检测;GAN模型可以用于图像生成。
语音识别:AI大模型可以用于语音识别、语音合成、语音翻译等任务。例如,DeepSpeech模型可以用于语音识别;Tacotron模型可以用于语音合成。
内容创作:基于视觉语言模型的内容创作得到广泛应用。ChatGPT4.0的问世补全了文字和图片内容,利用多模态模型更强大的推理能力可以实现大型内容创作。AI大模型可以辅助人们进行各种类型的创作,如写作、绘画、音乐等。
人机交互:借助AI大模型的语言理解能力,人机交互体验有望获得革命性进步。机器可以更全面地理解人类的指令与需求,并对模拟的内容提供辅助。AI大模型可以使人机交互更加自然、高效。
智能住行:利用AI大模型建立家居设备和汽车电脑的中枢管理,强大的语言模型改善语音交互的质量,提高家居和汽车的智能型和自主性,协助处理日常事务、制定规划控制等。AI大模型可以使我们的生活更加便捷、舒适。
“数字生命”:AI大数据有望实现智能体全方位、全场景的终身学习,具备快速学习、反馈现实和探索世界的能力,有望对多模态数据体进行感知与学习,应用现实。AI大模型有望创造出具有自主意识和情感的“数字生命”。
如何系统学习AI大模型
学习大型人工智能模型,如GPT-3、BERT或任何其他先进的神经网络模型,需要系统的方法和持续的努力。下面的学习路线能帮助你快速梳理知识,形成自己的体系。
L1级别:AI大模型时代的华丽登场
L2级别:AI大模型API应用开发工程
L3级别:大模型应用架构进阶实践
L4级别:大模型微调与私有化部署
一般掌握到第四个级别,市场上大多数岗位都是可以胜任,但要还不是天花板,天花板级别要求更加严格,对于算法和实战是非常苛刻的。建议普通人掌握到L4级别即可。
总结与展望
AI大模型作为人工智能领域的重要发展方向,具有巨大的潜力和广阔的应用前景。随着技术的不断进步和应用场景的不断拓展,AI大模型将在未来发挥越来越重要的作用,为人类社会带来更多的创新和进步。然而,我们也应该清醒地认识到,AI大模型的发展仍然面临着一些挑战,例如计算资源的需求、数据隐私的保护、算法的鲁棒性等。只有克服这些挑战,才能更好地发挥AI大模型的潜力,实现人工智能的真正价值。
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。让我们共同期待AI大模型在未来能够为我们带来更多的惊喜和改变!








