在人工智能领域,大型语言模型(LLMs)如T5、BLOOM、GPT-3等正以前所未有的速度发展。其中,ChatGPT以其逼真的人类交互能力尤为引人注目。然而,ChatGPT主要基于语言模型训练,在处理图像生成任务方面存在局限性。另一方面,视觉基础模型(VFMs)如BLIP、Visual Transformer和Stable Diffusion在图像理解和生成方面表现出色。但这些先进的语言和图像模型通常只能接收特定模态的输入和输出,且图像模型在输入输出格式上较为固定,缺乏语言模型的灵活性。因此,构建一个类似于ChatGPT的系统来实现图像的理解和生成成为一个挑战。本文将深入探讨Visual ChatGPT,一个旨在弥合ChatGPT与VFMs之间差距的创新系统。
Visual ChatGPT并非从头开始训练多模态ChatGPT,而是巧妙地结合了ChatGPT和多种VFMs。为了实现这一目标,作者构建了一个提示管理器(Prompt Manager),旨在指导ChatGPT有效地利用这些VFMs,并通过迭代反馈不断优化结果。该提示管理器具备以下关键功能:
- 直观的VFM能力提示: 向ChatGPT清晰地传达各个VFMs的功能及其输入输出格式。
- 视觉信息转换: 将PNG图像、深度图像、掩码矩阵等视觉信息转化为语言形式,以便ChatGPT理解。
- VFM优先级和冲突处理: 管理不同VFMs的优先级,解决潜在的冲突,确保协同工作。
Visual ChatGPT通过以下三个步骤实现图像模型和语言模型的交互:
- 多模态输入: 同时接收语言和图像作为输入。
- 复杂视觉任务处理: 能够处理需要多个人工智能模型和多个步骤协作的复杂视觉问题或视觉编辑指令。
- 反馈与纠错: 接收反馈意见,纠正错误,将视觉模型信息注入到ChatGPT中,并考虑多个输入/输出模型和视觉反馈模型。
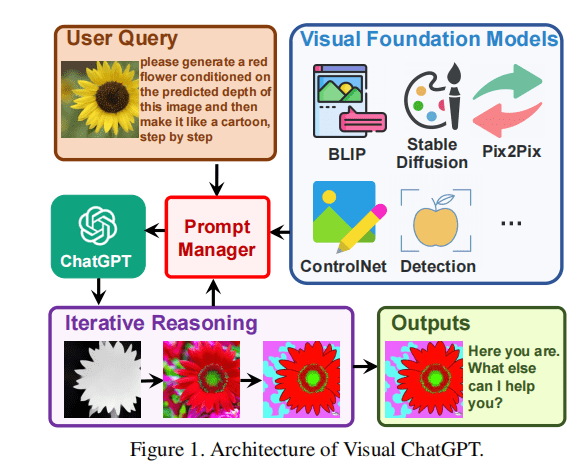
例如,用户上传一张黄色花的图片,并输入指令:“请根据预测的图像深度,生成一朵红色的花,然后逐步变成卡通的样子”。提示管理器会协助Visual ChatGPT启动相关VFMs的执行链。首先,使用深度估计模型检测深度信息;然后,利用深度图像模型生成一朵红花的深度信息;最后,使用风格迁移模型将风格转换为卡通。整个转换过程会被记录,并在获得“卡通”的提示后结束。
本文的主要贡献在于:
- Visual ChatGPT的提出: 开创了ChatGPT与VFMs结合的先河,使ChatGPT能够处理更复杂的视觉问题。
- 提示管理器的设计: 构建了一个包含22个不同VFMs的提示管理器,并定义了它们之间的内部相关性,从而实现更好的互动和结合。
- 视觉理解和生成能力验证: 验证了Visual ChatGPT在视觉理解和生成方面的能力。
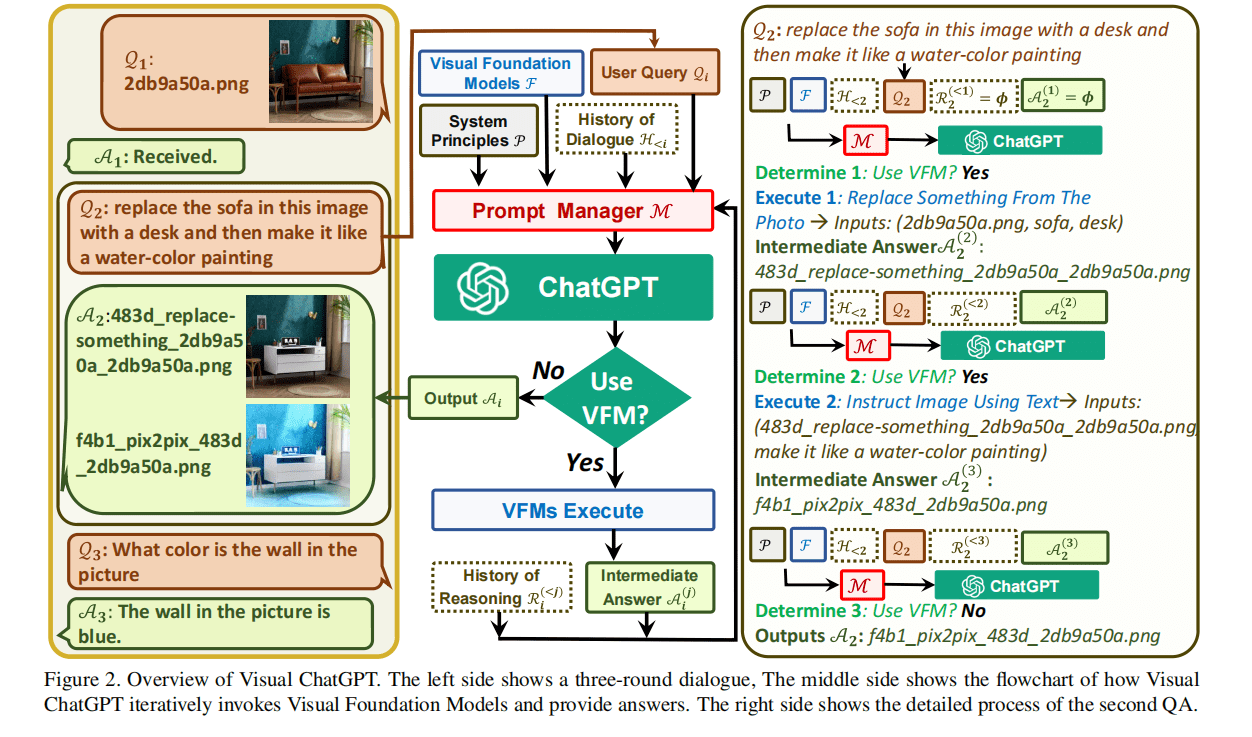
在Visual ChatGPT系统中,假设一个有N个question-answer pairs的对话系统为S = { (Q1, A1), (Q2, A2), ..., (QN, AN) }。为了从第i轮对话中得到响应Ai,需要使用一系列的VFM和这些模型的中间输出Ai(j)。j表示第j个VFM (F) 的输出。也就是说在时域Prompt Manager M 协调时,Ai(j)的形式需要不断修改来满足每个F的输入。最后,如果表示为最终响应,则系统输出Ai(j),不再执行VFM。
Visual ChatGPT的表达形式如下:
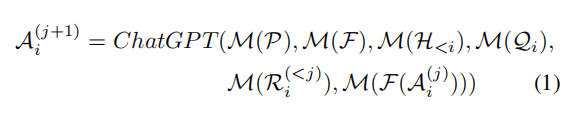
- 系统规则P: 为Visual ChatGPT提供了基础规则,需要对图像文件名敏感,能够使用VFM来处理图像。
- 视觉基础模型F: Visual ChatGPT能够很好地组合不同的VFM(F = { f1, f2, ..., fN }),每个基础模型fi 都是具有显式输入和输出的确定函数。
- 对话历史H < i: 定义第i轮对话的历史为前面 “问题-回答” pairs 的串联形式,即 { (Q1, A1), (Q2, A2), ..., (Qi, Ai) }。此外,还有一个最大长度阈值来截断历史信息,来满足ChatGPT模型的输入长度。
- 用户查询Qi: Visual ChatGPT的用户查询包括语言查询和视觉查询。
- 推理历史Ri < j: 为了解决复杂的问题,Visual ChatGPT需要多个VFM的合作,对第i轮对话,Ri < j是调用第j个VFM之前的所有推理历史。
- 中间答案A(j): 复杂查询问题中,Visual ChatGPT会调用多个不同的VFM来逐步获得中间答案,也就会产生多个中间答案。
- 提示管理器M: 提示管理器会将所有视觉信号转换为语言以便于ChatGPT的理解。
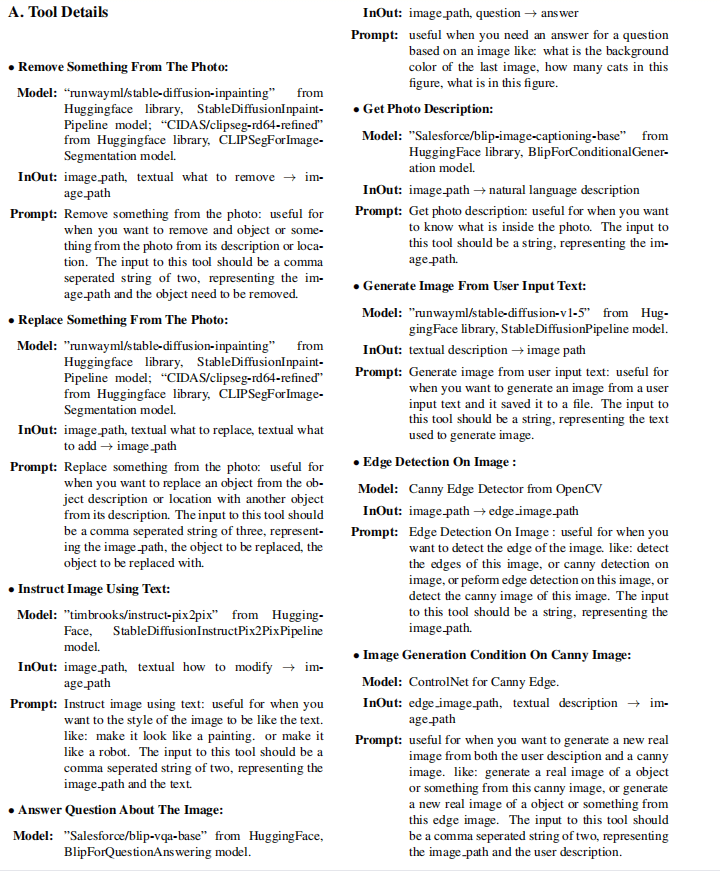
Visual ChatGPT包含22个基础视觉模型,这些模型涵盖了图像理解、生成和编辑等多个方面,为系统提供了强大的视觉处理能力。
对系统规则的提示管理 M(P)
Visual ChatGPT是一个能够调动多个不同VFMs来理解视觉信息并生成对应回答的系统。因此,需要很多准则来指导管理器将信息转换为ChatGPT能理解的信息。
提示管理器具有以下关键作用:
- Visual ChatGPT的作用: 协助完成一系列文本和视觉相关的任务,如视觉问答、图像生成和编辑等。
- VFMs的易用性: Visual ChatGPT可以访问VFM的列表来解决各种VL任务。决定使用哪个基础模型完全由ChatGPT模型本身决定,因此很容易支持新的VFM和VL任务。
- 文件名敏感性: Visual ChatGPT根据文件名访问图像文件,所以,使用精确的文件名很重要,可以避免歧义,因为一轮对话可能包含多个图像及其不同的更新版本和文件名的滥用将导致混乱。因此,Visual ChatGPT需要使用严格的文件名,以确保它检索和操作正确的图像文件。
- 链式思想: 如图1所示,要处理一个看似简单的命令,可能需要多个VFM,例如,查询 “根据预测的图像深度生成一朵红花,然后使其像卡通一样” 需要深度估计、深度到图像和风格转移VFM。为了通过将查询分解为子问题来解决更具挑战性的查询,在Visual ChatGPT中引入了CoT,以帮助决定、利用和分派多个VFM。
- 推理格式严格: Visual ChatGPT必须遵循严格的推理格式。因此,需要用复杂的正则表达式匹配算法来解析中间推理结果,并为ChatGPT模型构造合理的输入格式,以帮助它确定下一次执行,例如,触发一个新的VFM或返回最终的响应。
- 可靠性: 作为一种语言模型,Visual ChatGPT可能会伪造虚假的图像文件名或事实,从而使系统不可靠。为了处理这些问题,Visual ChatGPT忠实于视觉基础模型的输出,而不是制作图像内容或文件名。此外,多个VFM的协作可以提高系统的可靠性,因此构建的提示将指导ChatGPT优先利用VFM,而不是基于对话历史生成结果。
基础模型的提示管理 M(F)
Visual ChatGPT中有多个VFM来处理各种VL任务。这些不同的VFM有相似之处,例如:
- 替换图像中的目标可以被视为生成一个新的图像。
- Image-to-Text(I2T)任务和图像问题回答(VQA)任务可以理解为根据输入的图像来产生对应的响应。
如图3所示,提示管理器明确定义了以下各个子提示符,以帮助Visual ChatGPT准确地理解和处理VL任务:
- Name: 名称提示符为每个VFM提供了全局函数的抽象,例如,回答关于图像的问题,它不仅能够帮助Visual ChatGPT 以简洁的方式理解VFM的目的,而且也是VFM的入口。
- Usage: 使用提示符描述了应该使用VFM的特定场景。例如,Pix2Pix模型[35] 适合于更改图像的样式。提供这些信息有助于Visual ChatGPT对特定任务使用哪个VFM做出决定。
- Inputs/Outputs: 输入和输出提示反应了每个VFM所需的输入和输出的格式,因为格式可能变化很大,对Visual ChatGPT能否正确执行VFM有很重要的指导作用。
- Example(可选): 示例提示符是可选的,但它有助于Visual ChatGPT更好地理解如何在特定的输入模板下使用特定的VFM并处理更复杂的查询。
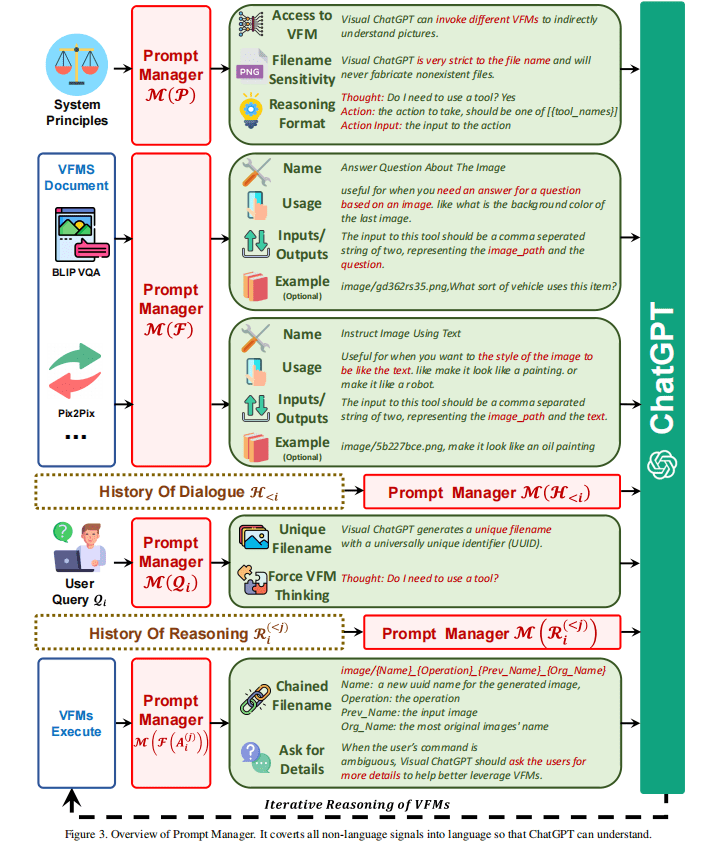
用户提问的提示管理 M(Qi)
Visual ChatGPT能够支持多种的查询,包括语言和图像的,简单的和复杂的,Prompt通过如下两个方面来处理用户的查询:
- Generate Unique Filename
Visual ChatGPT可以处理两种与图像相关的查询:一种涉及新上传的图像,另一种涉及对现有图像的引用。
对于新上传的图像,Visual ChatGPT生成一个具有普遍唯一标识符(UUID)的唯一文件名,并添加一个表示相对目录的前缀字符串 “image”,例如,“image/{uuid}.png”。
虽然新上传的图像不会被输入ChatGPT,但会生成一个虚假的对话历史,其中有一个问题说明图像的文件名,还有一个答案表明图像已经收到。这段虚假的对话历史有助于之后的对话。
对于涉及引用现有图像的查询,Visual ChatGPT会忽略文件名检查。这种方法已经被证明是有益的,因为ChatGPT能够理解用户查询的模糊匹配,如UUID名称。
- Force VFM Thinking
为了确保Visual ChatGPT的成功触发VFM ,在(Qi)中添加了一个后缀提示:“由于Visual ChatGPT 是一种文本语言模型,Visual ChatGPT必须使用工具来观察图像,而不是想象。这些思想和观察只在Visual ChatGPT中可见,Visual ChatGPT应该记住在人类的最终反应中重复重要的信息。也会反复思考:我需要使用一个工具吗?”。
这个提示有两个目的:
- 它提示Visual ChatGPT使用基础模型,而不是仅仅依赖于它的想象力;
- 它鼓励Visual ChatGPT提供由基础模型生成的特定输出,而不是像 “你在这里” 这样的通用响应。
基础模型输出的提示管理 M(F(Ai(j)))
对于来自不同VFM F(Ai(j)) 的中间输出,Visual ChatGPT能够隐式地总结并将它们提供给ChatGPT进行后续交互,即调用其他VFM进行进一步的操作,直到达到结束条件或反馈给用户。内部的步骤可以总结如下:
- Genarete Chained Filename:
由于Visual ChatGPT的中间输出将成为下一轮隐式对话的输入,故应该使这些输出更合乎逻辑,以帮助LLMs更好地理解推理过程。
具体来说就是从视觉基础模型生成的图像被保存在路径 “image/” 文件夹下。
之后,image的命名为 :“{Name} {Operation} {Prev Name} {Org Name}”
例如 “image/ui3c_edge-of_o0ec_nji9dcgf.png” 表示输入o0ec的一个名为ui3c的canny edge image,且该图像的元素名称为nji9dcgf。
这样的命名规则可以让ChatGPT了解是如何生成的这个图像
- Call for More VFMs:
Visual ChatGPT的一个核心是可以自动调用更多的VFMs来完成用户的命令。也就是ChatGPT会不断询问自己,它是否需要VFM来解决当前的问题,在每一阶段结束时扩展一个VFMs的后缀。
- Ask for More Details:
当用户的命令模棱两可时,Visual ChatGPT应该向用户询问更多的细节,以帮助更好地利用VFM。这种设计是为了安全考虑,因为LLMs不允许毫无根据地任意篡改或推测用户的意图(特别是当输入信息不足时)。
为了验证Visual ChatGPT的性能,作者进行了一系列实验。实验设置如下:使用ChatGPT(OpenAI“文本-数据-003”版本)实现LLM,并用LangChain指导LLM。从HuggingFace Transformers, Maskformer 和 ControlNet来收集基础模型。所有22个VFM全部部署需要4个Nvidia V100 GPU,但用户可以部署更少的基础模型,以灵活地节省GPU资源。聊天历史记录的最大长度为2000,多余的令牌被截断以满足ChatGPT的输入长度。
图4展示了Visual ChatGPT的16轮多模态对话,体现了其在复杂视觉任务中的应用能力。

图5展示了Prompt Manager相关案例研究,通过删除不同的部分来比较模型的性能,分析了不同提示管理策略对系统性能的影响。
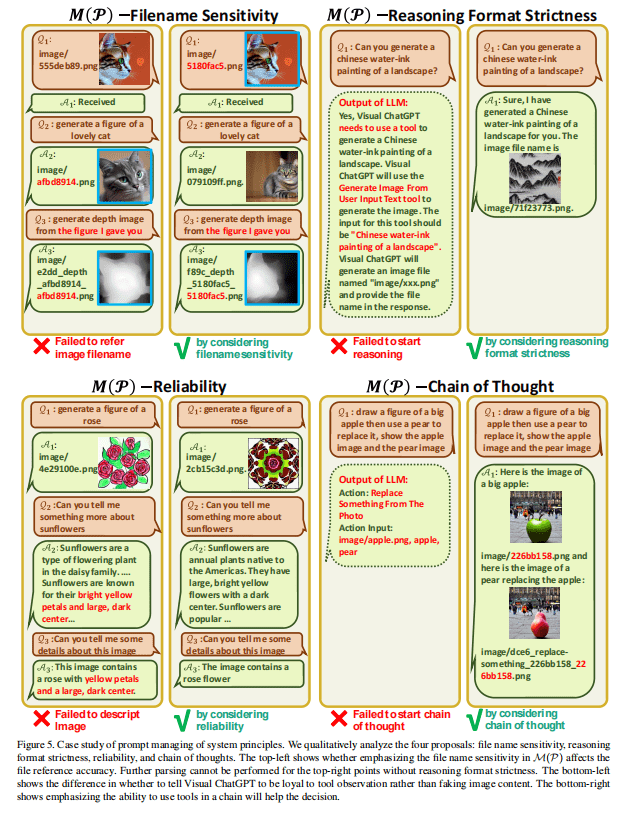
Prompt managing of foundation models案例分析
VFM的名称至关重要,名称需要有明确的定义。当名称缺失或不明确时,Visual ChatGPT会多次猜测,直到它找到一个现有的VFM,或遇到一个错误,如图6的左上部分所示。
VFM的使用应该清楚地描述应该使用模型以避免错误响应的特定场景。右上角显示了样式转换对替换对象的处理不当。
应准确提示输入和输出格式,以避免参数错误,如左下角所示。
虽然右下角删除了示例提示,但ChatGPT也可以总结对话历史和人类意图来使用正确的VFM,如右下角所示。

用户查询的提示管理器案例分析:图7上半部分分析了用户查询的提示管理器案例,输入的图像需要有唯一的命名,以避免被覆盖。
模型输出的提示管理案例分析:如图7下半部分所示,左下角的图片比较了删除和保留链式命名规则的性能。使用链式命名规则,Visual ChatGPT可以识别文件类型,触发正确的VFM,并得出文件依赖关系命名规则。
链式命名规则确实有助于Visual ChatGPT的理解。
右下角的图片给出了一个当项目推断不明确时要求更多细节的例子,这也表明了系统的安全性。

尽管Visual ChatGPT取得了显著进展,但仍然存在一些局限性:
- 强依赖性: 严重依赖于ChatGPT和VFMs的性能。
- 提示工程: 需要大量的提示工程,耗时且需要专业的语言和图像知识。
- 实时能力: 实时处理能力有限。
- Token限制: Token长度限制可能会限制可使用的语言模型的数量。
- 安全风险: 能够方便地使用基础模型(包括远程模型)可能导致敏感数据泄露。
Visual ChatGPT作为首次将ChatGPT和多种计算机视觉基础模型结合的案例,通过设计一系列提示,逐步将视觉信息注入ChatGPT中,实现了对视觉输入的理解和生成。然而,该系统也存在一些限制,例如耗时较长、依赖于基础模型以及执行结果与人类期望的一致性问题。未来的研究可以集中在解决这些局限性,进一步提升Visual ChatGPT的性能和实用性。