
在人工智能驱动的商业环境中,快速响应客户需求是保持竞争力的关键。大型语言模型(LLM),如GPT,为内容生成和对话交互提供了强大的能力。然而,GPT的响应速度可能成为商用场景中的瓶颈,导致用户体验下降。本文深入探讨了如何利用GPT的流式响应技术优化用户交互,提升商业应用的效率。
流式技术:实时交互的基石
流式技术将数据分解为小块,并按顺序传输,允许在数据完全传输之前就开始处理。这种方法广泛应用于视频流、语音识别和实时聊天等领域。在实时聊天应用中,流式技术至关重要,因为它能够实现即时反馈,避免用户长时间等待。
ChatGPT通过流式技术实现实时对话。用户输入的消息被拆分成小块,依次发送到服务器。服务器处理每个小块后,立即返回响应,这些响应也以小块的形式流式传输回客户端,实现近乎实时的用户体验。
当新用户连接到服务器时,ChatGPT会为该用户创建一个新的GPT模型实例。这个实例会根据用户的历史对话调整模型参数,以更好地适应用户的语言风格和习惯。当用户输入新消息时,服务器利用这个定制化的模型实例生成响应,并将响应分块进行流式传输。

流式技术的优势在于:
- 实时性:用户可以立即看到响应,无需等待完整内容生成。
- 可扩展性:能够处理大量消息,避免内存溢出和处理延迟。
- 个性化:能够适应不同用户的对话风格,提高对话质量。
GPT流式响应的实现细节
GPT提供了一个名为stream的参数,用于控制是否启用流式返回。启用后,GPT会通过结束符(stop)来指示流的结束。然而,在使用过程中,有时会遇到length字段返回,表示流数据因Token耗尽而提前结束,内容不完整。
在GPT-3(text-davinci-003)中,实际测试表明不存在结束符stop。因此,在流数据结束时,需要手动添加结束符,以确保客户端能够正确识别数据流的结束。
GPT的SDK提供了两个关键函数:create和acreate。在开发流服务时,应优先选择异步函数acreate,以充分利用异步处理的优势。
response = await openai.ChatCompletion.acreate(acreate函数返回一个异步迭代器,需要进行适当的处理才能使用:
async for tmp in response:流数据处理的挑战与优化
原始的流数据通常以字节为单位返回。在某些应用场景下,例如公众号接入,这种按字节返回的方式会严重影响用户体验。因此,需要对流数据进行优化,例如按标点符号断句,按短句返回,以提高可读性。

优化策略:短句分割
将原始的字节流数据处理成更易于理解的短句,可以显著提升用户体验。以下是按短句返回的示例:
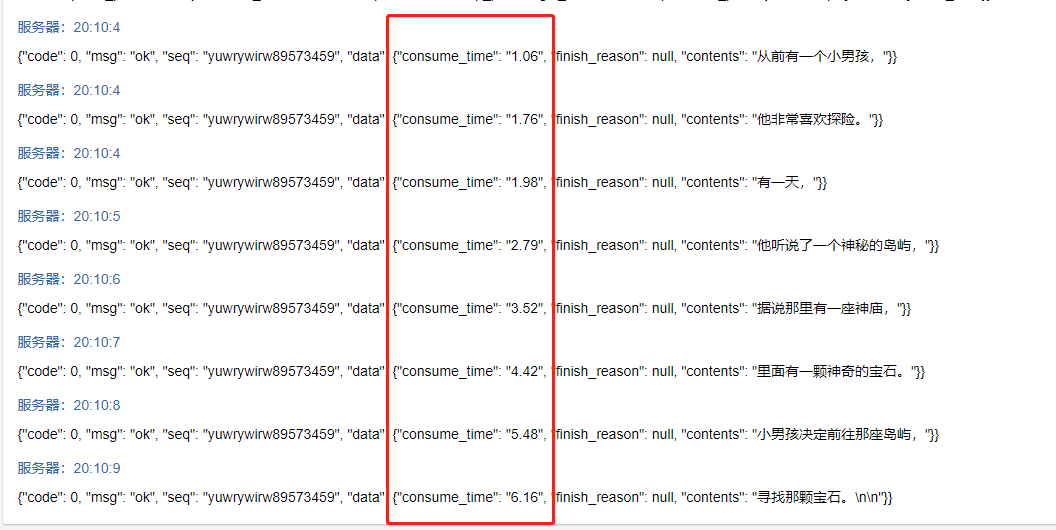
性能对比:GPT响应时间分析
为了更直观地了解流式响应带来的性能提升,我们以“讲个故事”为例,对比了不同方式下的GPT返回时间:
- 一句话返回:一个长文本返回耗时约20秒。
- 按字节返回:第一个数据返回耗时约0.6秒。
- 按短句返回:第一个短句返回耗时约1.1秒。
从上述数据可以看出,流式响应能够显著缩短首次响应时间,从而改善用户体验。按短句返回在首次响应时间上略慢于按字节返回,但其更高的可读性使其成为更佳的选择。
案例分析:电商客服机器人
假设一家电商公司使用GPT构建智能客服机器人。如果采用非流式响应,用户提出问题后需要等待较长时间才能获得答案,这会降低用户满意度。通过引入流式响应,客服机器人可以在用户输入问题的同时,逐步给出答案,让用户感受到更快的响应速度。
例如,用户询问“这款手机有哪些颜色?”,客服机器人可以先回复“这款手机有”,然后逐步给出颜色选项:“黑色”,“白色”,“蓝色”。这种逐步呈现答案的方式不仅缩短了用户的等待时间,还增强了交互的流畅性。
技术实现:Python示例代码
以下是使用Python和OpenAI SDK实现GPT流式响应的示例代码:
import openai
import asyncio
async def generate_response(prompt):
response = await openai.ChatCompletion.acreate(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt}],
stream=True
)
async for chunk in response:
content = chunk["choices"][0].get("delta", {}).get("content")
if content:
print(content, end="", flush=True)
print()
async def main():
prompt = "讲一个关于旅行的故事。"
await generate_response(prompt)
if __name__ == "__main__":
asyncio.run(main())这段代码展示了如何使用openai.ChatCompletion.acreate函数创建一个流式响应,并使用async for循环逐块读取响应内容。flush=True参数确保内容能够立即输出到控制台,从而实现实时显示效果。
结论与展望
GPT的流式响应技术为实时交互应用带来了显著的性能提升。通过优化流数据处理方式,例如按短句返回,可以进一步提升用户体验。随着人工智能技术的不断发展,我们可以期待GPT在实时通信、智能客服等领域发挥更大的作用。
未来,我们可以探索更智能的流数据处理策略,例如根据用户阅读速度动态调整返回速度,或者根据对话上下文调整内容生成策略。这些优化将进一步提升GPT在商业应用中的价值,为用户带来更流畅、更自然的交互体验。

通过深入了解GPT流式响应的原理和实现方式,并结合实际应用场景进行优化,我们可以充分发挥GPT的潜力,打造更智能、更高效的AI应用。流式响应不仅仅是一种技术手段,更是一种提升用户体验、增强商业价值的重要策略。








