
谷歌发布了其最新的旗舰AI模型Gemini,旨在重新定义人工智能的能力边界。这款多模态模型系列,包含Ultra、Pro和Nano三种尺寸,能够处理文本、图像、音频和视频等多种数据形式。Gemini Ultra在多项基准测试中表现卓越,并在MMLU(大规模多任务语言理解)测试中首次达到了人类专家的水平,预示着AI在理解和推理方面取得了重大进展。
Gemini的设计理念是原生多模态,这与以往先开发纯文本模型再附加视觉和音频编码器的方法截然不同。这种设计使得Gemini能够自然地交错处理不同模式的信息,无论是输入还是输出。例如,用户可以混合输入文本、图像和视频,模型也能以同样的方式生成内容,从而实现更丰富、更自然的交互。
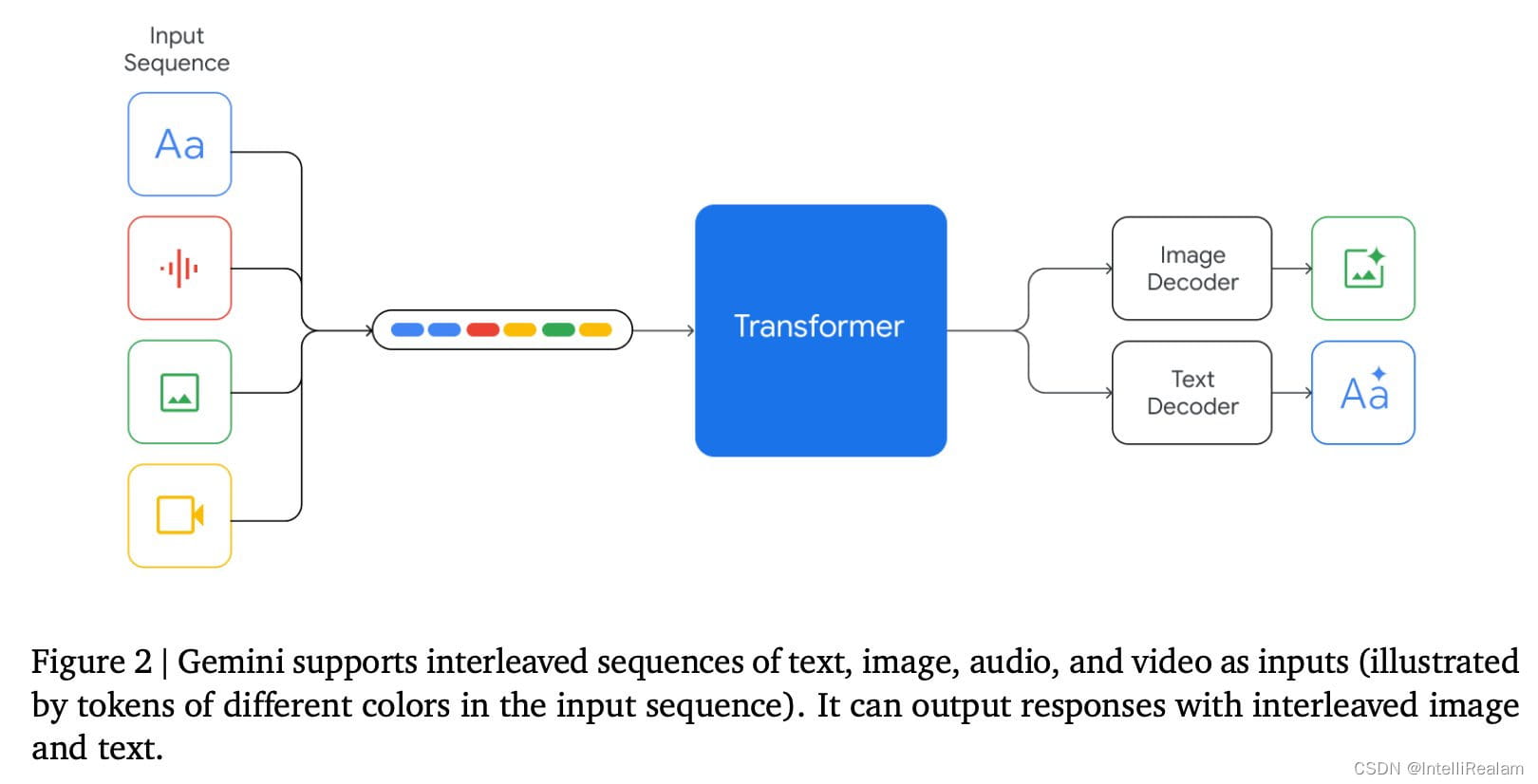
Gemini模型基于Transformer解码器构建,并通过架构和模型优化的改进,实现了大规模稳定训练和在Google张量处理单元上的优化推理。模型支持高达32k的上下文长度,并采用高效的注意力机制,例如多查询注意力。这种设计使得Gemini能够在处理长文本和复杂任务时保持高效和准确性。
Gemini的不同尺寸模型针对不同的应用场景进行了优化。Nano版本专为在移动设备等资源受限的环境中使用而设计,Pro版本则用于增强数据中心的性能和大规模可部署性,而Ultra版本则适用于高度复杂的任务。即使是最小的Nano版本,也展现出了强大的性能。

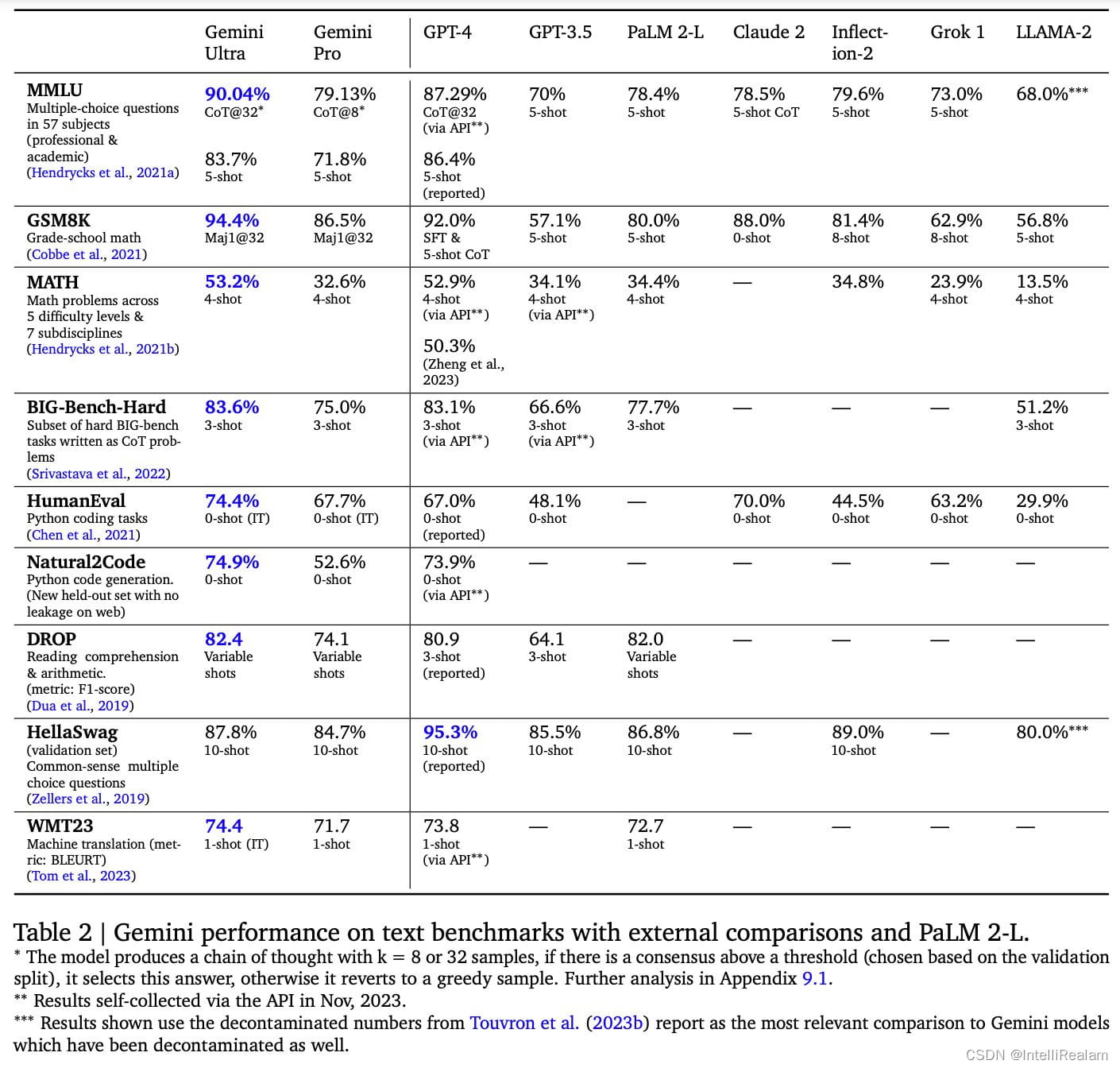
在文本、数学、编码和推理基准测试中,Gemini的表现超越了以往的模型。Gemini Ultra在MMLU测试中取得了超过90%的成绩,成为首个达到人类专家水平的模型。这表明Gemini在理解和解决复杂问题方面具有卓越的能力。
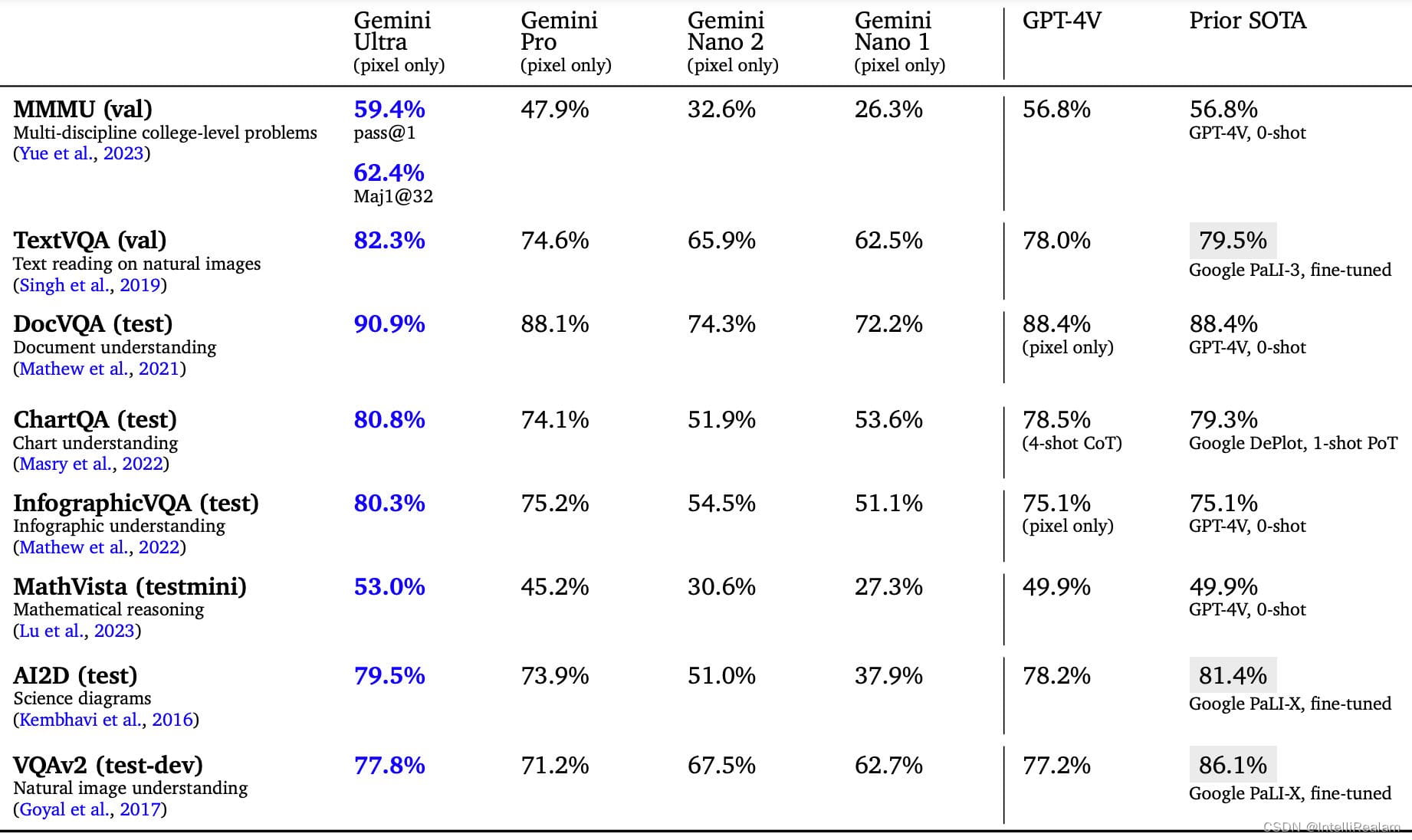
在图像理解方面,Gemini在所有测试基准中都表现出色,Ultra模型在每个基准测试中都创下了新的记录。这证明了Gemini在视觉信息处理方面的强大能力。
谷歌已将Gemini集成到其多项产品中。Gemini Pro模型现在为Bard提供支持,开发者可以通过Google AI Studio或Google Cloud Vertex AI上的API访问Gemini Pro。Android开发者可以在Pixel 8 Pro上使用Android Nano尺寸。此外,谷歌计划在完成对模型的进一步信任和安全检查后,推出由Gemini Ultra模型提供支持的Bard Advanced。
Gemini的发布标志着人工智能领域的一个重要里程碑。其多模态能力、卓越的性能以及广泛的应用前景,使其成为推动AI技术发展的重要力量。随着Gemini的不断完善和应用,我们有理由期待人工智能将在未来发挥更大的作用。
Gemini的技术架构与创新点
Gemini模型的技术架构是其强大能力的核心。该模型基于Transformer解码器,并通过多项创新技术进行了增强,使其能够处理各种复杂的任务。
- 原生多模态设计:Gemini从一开始就被设计为多模态模型,这意味着它可以同时处理文本、图像、音频和视频等多种数据形式。这种设计避免了传统模型需要将不同模态的数据转换为统一格式的局限性,使得Gemini能够更自然地理解和生成多模态内容。
- 大规模稳定训练:Gemini模型经过大规模的训练,这使得它能够学习到更复杂的模式和关系。谷歌采用了先进的训练技术,确保模型在训练过程中保持稳定,避免出现梯度消失或爆炸等问题。
- Google张量处理单元优化:Gemini模型在Google的张量处理单元(TPU)上进行了优化,这使得它能够更快地进行推理。TPU是一种专门为机器学习任务设计的硬件加速器,它可以显著提高模型的性能。
- 高效的注意力机制:Gemini模型采用了高效的注意力机制,例如多查询注意力。这些机制可以帮助模型更好地关注输入数据中的重要部分,从而提高模型的准确性和效率。
- 支持长上下文:Gemini模型支持高达32k的上下文长度,这意味着它可以处理更长的文本序列。这对于处理需要理解上下文信息的任务非常重要,例如阅读理解和文本摘要。
Gemini的应用场景与未来展望
Gemini模型具有广泛的应用前景,可以应用于各种领域,例如:
- 自然语言处理:Gemini可以用于文本生成、机器翻译、问答系统、文本摘要等任务。由于其强大的语言理解和生成能力,Gemini可以生成高质量的文本内容,并提供更准确和自然的翻译结果。
- 计算机视觉:Gemini可以用于图像识别、图像分类、目标检测、图像生成等任务。Gemini可以识别图像中的物体、场景和人物,并生成逼真的图像。
- 语音识别与合成:Gemini可以用于语音识别、语音合成、语音翻译等任务。Gemini可以将语音转换为文本,并将文本转换为语音,实现人机语音交互。
- 多模态应用:Gemini可以用于处理涉及多种模态数据的任务,例如视频理解、图像描述、多模态对话等。Gemini可以理解视频的内容,并生成对图像的描述,还可以进行多模态对话。
随着人工智能技术的不断发展,Gemini将在未来发挥更大的作用。我们可以期待Gemini在以下方面取得更多突破:
- 更强大的性能:随着模型规模的不断扩大和训练技术的不断改进,Gemini的性能将得到进一步提升。我们可以期待Gemini在各种基准测试中取得更好的成绩。
- 更广泛的应用:Gemini将被应用于更多的领域,例如医疗、教育、金融等。Gemini可以帮助医生诊断疾病,为学生提供个性化教育,并为金融机构提供风险评估。
- 更智能的交互:Gemini将能够与人类进行更智能的交互。我们可以期待Gemini能够理解人类的意图,并提供更个性化的服务。
Gemini对AI生态的影响
谷歌Gemini的发布,无疑将对整个AI生态产生深远的影响。它不仅代表了技术上的突破,更预示着AI应用的新纪元。
- 加速多模态AI的发展:Gemini的原生多模态设计理念,将鼓励更多的研究者和开发者关注多模态AI。未来,我们可以期待更多能够处理多种数据形式的AI模型出现。
- 推动AI硬件的创新:Gemini在TPU上的优化,将推动AI硬件的创新。未来,我们可以期待更多专门为AI任务设计的硬件加速器出现。
- 促进AI应用的普及:Gemini的广泛应用,将促进AI应用的普及。未来,我们可以期待AI技术渗透到我们生活的方方面面。
- 引发AI伦理的讨论:Gemini的强大能力,将引发对AI伦理的讨论。我们需要认真思考如何确保AI技术被用于积极的目的,并避免其被滥用。
Gemini的发布是人工智能领域的一个重要里程碑,它展示了人工智能在理解和生成多模态内容方面的巨大潜力。随着Gemini的不断发展和应用,我们有理由相信,人工智能将在未来发挥更大的作用,为人类带来更多的福祉。








