谷歌最新发布的Gemini模型,无疑是人工智能领域的一颗重磅炸弹。它不仅对标GPT-4,更在多项关键性能指标上实现了超越,预示着AI技术发展的新方向。Gemini模型家族包含Ultra、Pro和Nano三个版本,分别应对不同的应用场景,这种差异化的设计思路,体现了谷歌对AI技术普惠化的深刻理解。
Gemini模型的架构与创新
Gemini模型的核心架构依然是Transformer的Decoder部分,但谷歌对其进行了深度优化和改进。Transformer架构在处理序列数据方面具有天然优势,而Decoder部分则专注于生成任务,这使得Gemini在文本生成、图像生成等领域拥有卓越的表现。模型最大支持32K上下文,这意味着它可以处理更长的文本序列,捕捉更复杂的依赖关系,从而生成更连贯、更具逻辑性的内容。
Gemini模型的输入非常灵活,可以是文字、音频和视觉信息的任意组合。这种多模态输入能力,使得Gemini可以处理更复杂的现实世界场景。例如,它可以根据一张图片生成一段描述,或者根据一段音频生成一段文字摘要。
在视觉编码方面,Gemini借鉴了Flamingo、CoCa和PaLI等模型的成功经验,并在此基础上进行了创新。与这些模型不同的是,Gemini从一开始就具备多模态能力,并且可以直接输出图像。视频理解方面,Gemini将视频编码为大型上下文窗口中的帧序列,从而捕捉视频中的时序信息。
Gemini还可以直接从通用语音模型(USM)特征中获取16kHz的音频信号。这使得模型能够捕捉到音频中细微的差别,例如语音的情感、语调等,而这些信息在将音频简单地映射到文本输入时往往会丢失。

Gemini模型的训练与部署
Gemini模型的训练使用了谷歌自家的TPU资源。TPU是谷歌专门为深度学习设计的加速器,具有强大的计算能力和高效的内存带宽。Gemini的训练数据集包含了来自网络文档、书籍、代码以及图像、音频和视频数据。
tokenizer使用的是SentencePiece tokenizer。研究人员发现,在整个训练语料库的大量样本上训练标记化器可以提高推断词汇量,从而提高模型性能。例如,Gemini模型可以有效地标记非拉丁文脚本,这有利于提高模型质量以及训练和推理速度。用于训练最大模型的token数量是按照霍夫曼等人(2022)的方法确定的。对于较小的模型,则使用更多的token进行训练,以提高给定推理预算下的性能,这与 Touvron 等人(2023a)所提倡的方法类似。
为了保证数据质量,研究人员使用了启发式规则和基于模型的分类器对所有数据集进行质量过滤,并进行了安全过滤,以去除有害内容。他们还从训练语料库中过滤评估集。最终的数据混合物和权重是通过对较小模型的消减确定的。研究人员进行了阶段性训练,以便在训练过程中改变混合物的组成,在训练接近尾声时增加领域相关数据的权重。他们发现,数据质量对高性能模型至关重要,并认为在寻找预训练的最佳数据集分布方面仍存在许多有趣的问题。

Gemini模型的性能评估
Gemini模型是原生的多模态模型,因为它们是跨文本、图像、音频和视频进行联合训练的。这种联合训练是否能产生一个在每个领域都有强大能力的模型,是一个悬而未决的问题。评估结果表明,情况确实如此:在广泛的文本、图像、音频和视频基准测试中,Gemini 树立了新的技术典范。
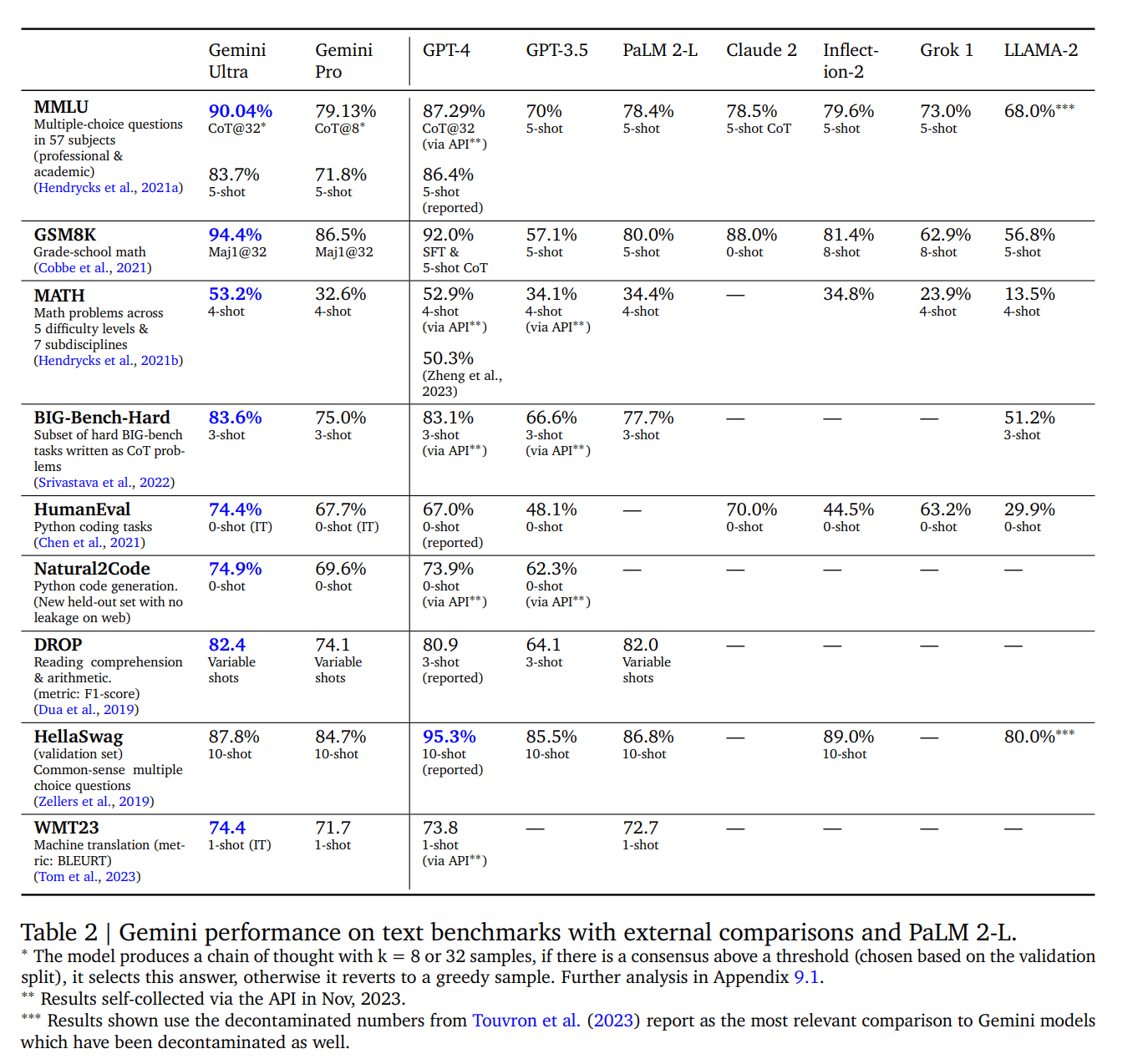
在一系列基于文本的学术基准测试中,研究人员将 Gemini Pro 和 Ultra 与一套外部 LLM 和他们之前的最佳模型 PaLM 2 进行了比较,测试内容包括推理、阅读理解、STEM 和编码。结果表明,Gemini Pro 的性能优于 GPT-3.5 等推理优化模型,并可与现有的几种能力最强的模型相媲美,而 Gemini Ultra 则优于目前所有的模型。
研究人员发现,当 Gemini Ultra 与考虑到模型不确定性的思维链提示方法(Wei 等人,2022 年)结合使用时,其准确率最高。该模型会产生一个包含 k 个样本(例如 8 个或 32 个)的思维链。如果存在高于预设阈值的共识(根据验证分割选择),它就会选择这个答案,否则就会返回到基于最大似然选择的贪婪样本,而不进行思维链。
Gemini Nano:边缘计算的福音
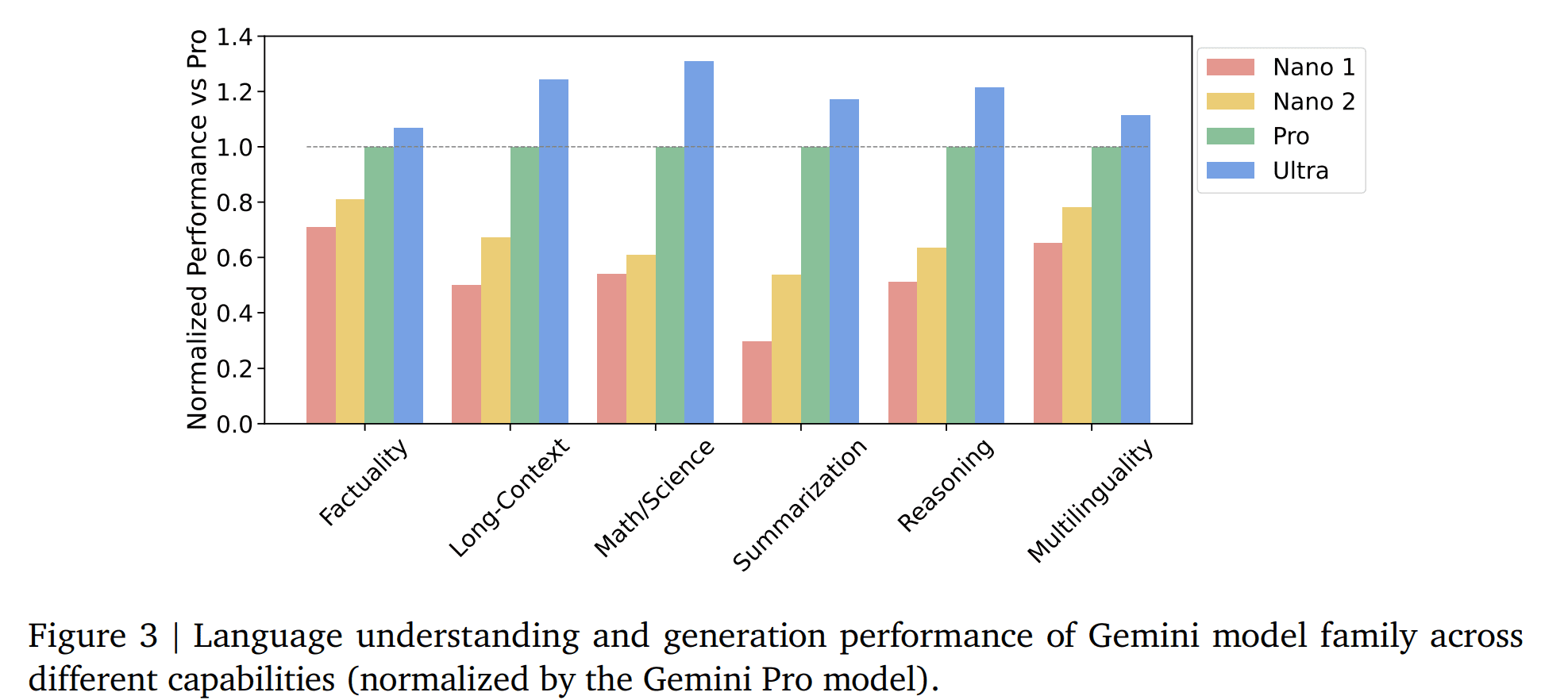
Gemini Nano是Gemini家族中最小的成员,拥有1.8B或3.25B的参数。它可以运行在边缘计算设备上,例如手机、平板电脑等。这意味着用户可以在本地设备上使用Gemini模型,而无需将数据发送到云端,从而提高了隐私性和响应速度。

Gemini模型的多语言能力
Gemini模型在多语言处理方面也表现出色。它可以进行多语言翻译、多语言数学计算和多语言总结。

Gemini模型的长文本处理能力
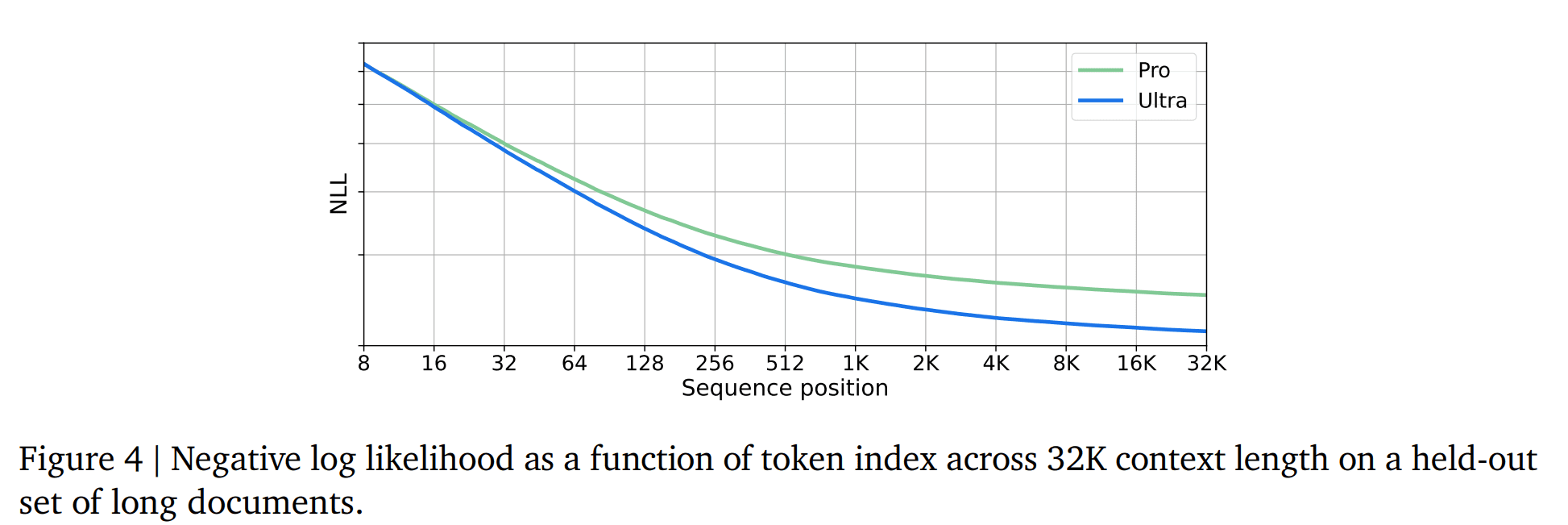
Gemini模型是在32768个token的情况下进行训练的,这意味着它可以处理较长的文本序列。
Gemini模型的人类偏好评估
研究人员还对Gemini模型进行了人类偏好评估,结果表明,Gemini模型的输出更符合人类的偏好。

Gemini模型的多模态能力
Gemini模型天生就是多模态的。它具有独特的能力,能将其跨模态能力(如从表格、图表或图形中提取信息和空间布局)与语言模型的强大推理能力(如其在数学和编码方面的一流性能)无缝结合起来。这些模型在辨别输入中的细粒度细节、聚合跨时空的上下文以及将这些能力应用于与时间相关的视频帧和/或音频输入序列方面也表现出色。
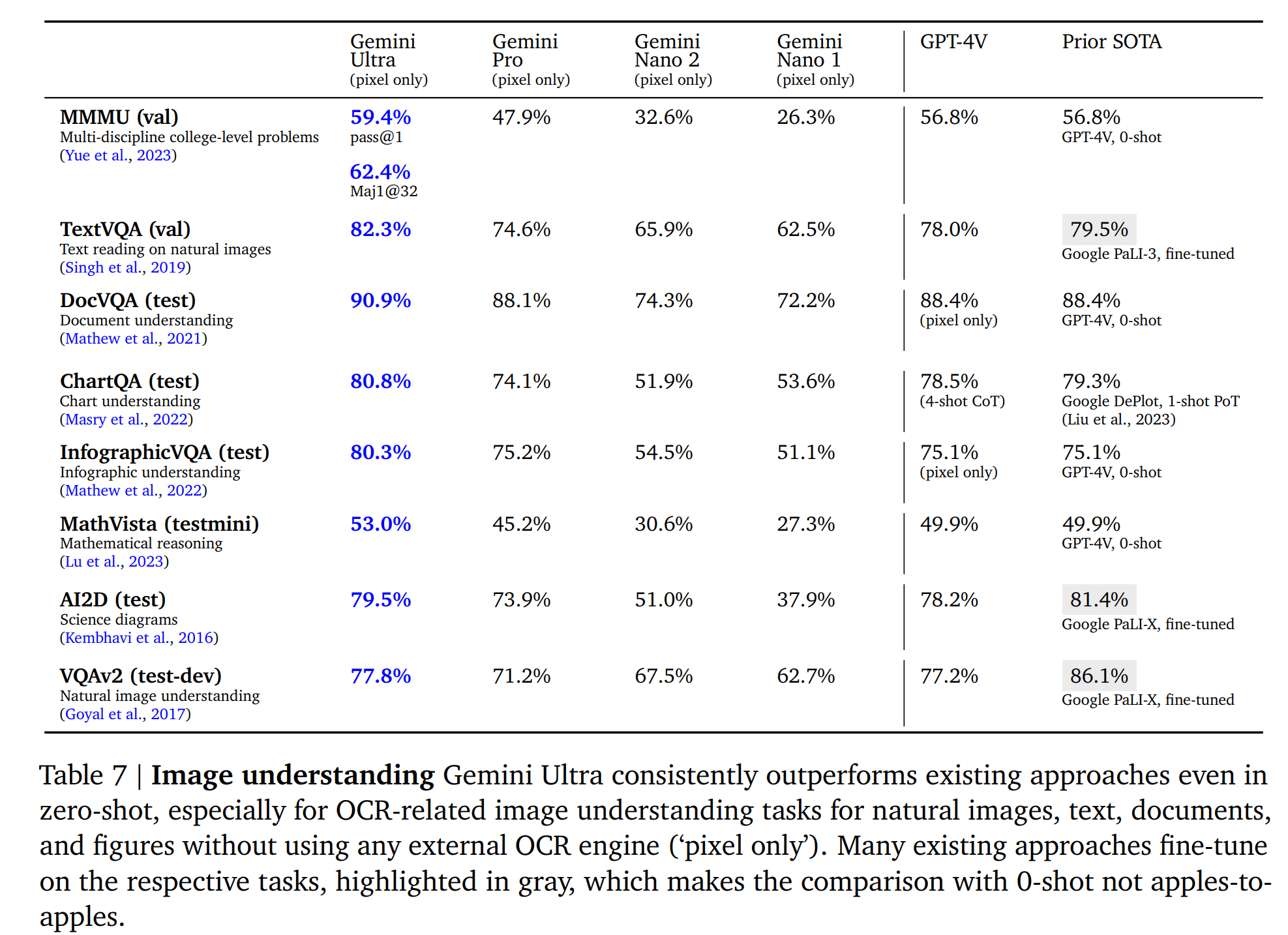
Gemini模型的图像理解能力
Gemini模型在图像理解方面表现出色。它可以识别图像中的物体、场景和关系,并生成相应的描述。
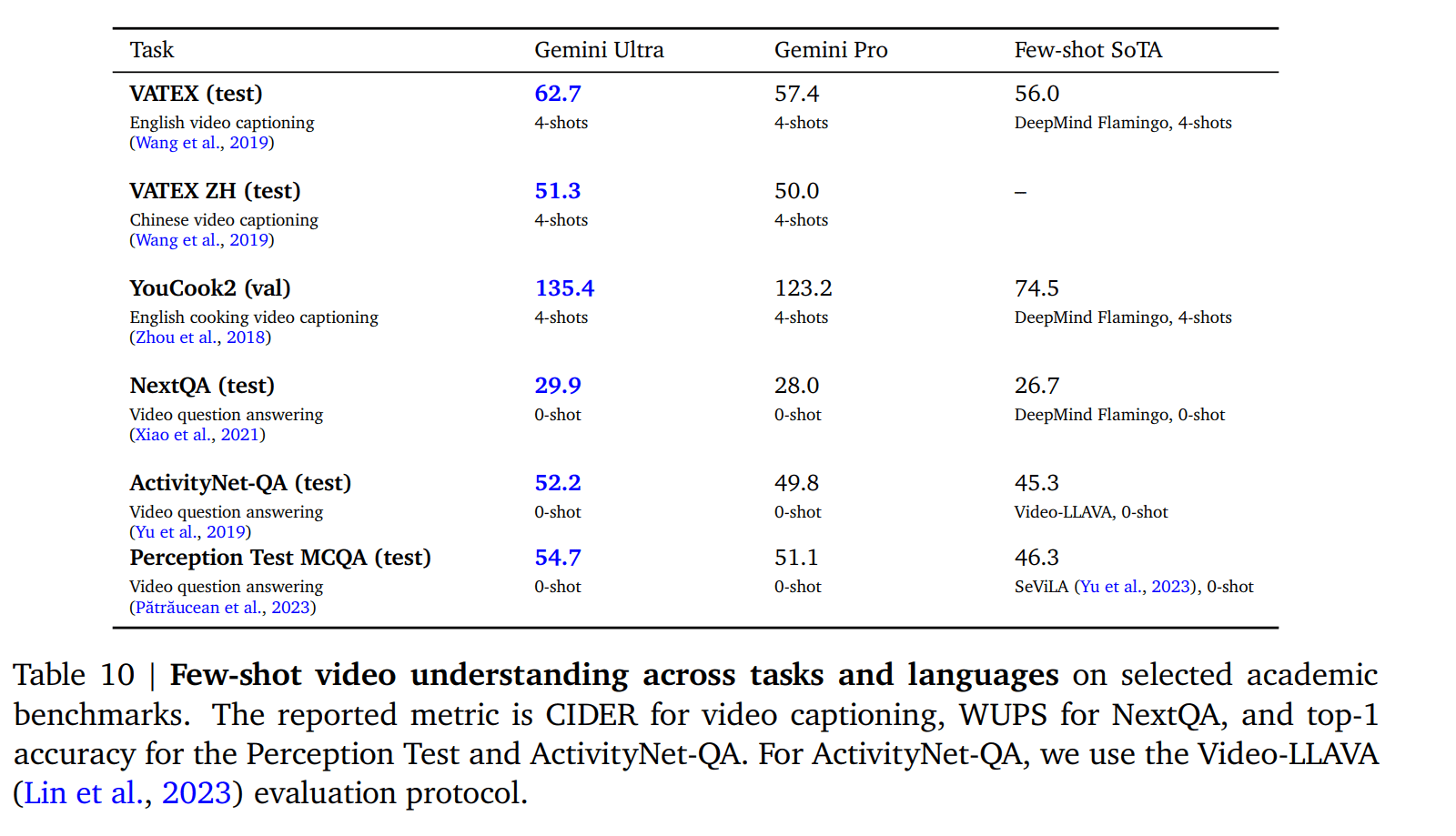
Gemini模型的视频理解能力
Gemini模型在视频理解方面也表现出色。它可以识别视频中的动作、事件和场景,并生成相应的描述。为了实现视频理解,研究人员从每个视频片段中抽取 16 个间隔相等的帧,并将其输入 Gemini 模型。

Gemini模型的图像生成能力
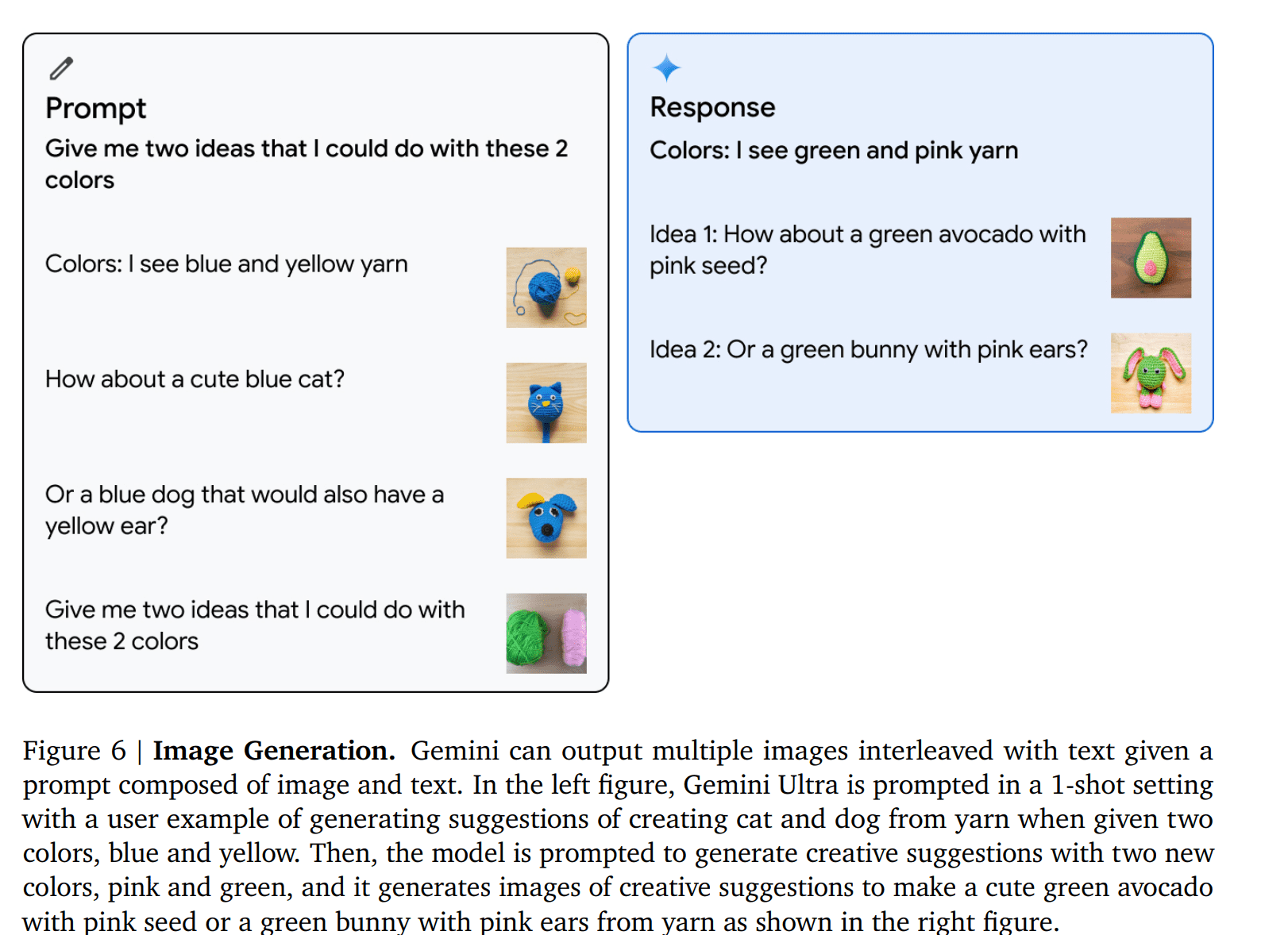
Gemini模型还可以生成图像。它可以根据文本描述生成图像,也可以根据现有图像生成新的图像。
Gemini模型的音频理解能力
Gemini模型在音频理解方面也表现出色。它可以识别音频中的语音、音乐和环境声音,并生成相应的描述。
Gemini模型的多模态组合能力
Gemini模型可以将多种模态的信息组合起来,从而实现更复杂的任务。例如,它可以根据一张图片和一段文字生成一段新的文本,或者根据一段音频和一段视频生成一段新的视频。

负责任的部署
谷歌非常重视Gemini模型的安全性和可靠性。他们采取了一系列措施来确保Gemini模型的部署是负责任的。
这些措施包括:影响评估、模型策略、评估和缓解措施。缓解措施包括:数据过滤、指令调整和事实性检查。
总结与展望
Gemini模型是谷歌在人工智能领域的一次重大突破。它不仅在多项性能指标上超越了现有模型,而且还具备强大的多模态能力。Gemini模型的发布,预示着人工智能技术将迎来新的发展机遇。Gemini模型的广泛应用,将为教育、日常问题解决、多语言交流、信息总结、提取和创造力等领域带来新的方法。我们有理由相信,在不久的将来,Gemini模型将成为我们生活中不可或缺的一部分。