
在人工智能领域,Gemini的出现无疑为行业带来了新的活力。长期以来,OpenAI和微软等巨头占据着主导地位,而Gemini凭借其独特的多模态能力和更大的规模,正在迅速崛起。它不仅能够处理文本,还能无缝整合图像、音频和视频等多种数据类型,从而重新定义了人机交互的边界。谷歌此次在人工智能领域的强势回归,预示着一个由AI驱动的创新未来正在加速到来。
本文将深入探讨如何利用免费的Google API密钥,以及必要的开发工具,构建一个超越传统文本交互的智能聊天机器人。这不仅仅是一个简单的教程,更是一次对Gemini内在视觉和多模态方法的探索,它能够根据视觉输入理解图像并生成文本,为我们打开了人工智能应用的新视角。
什么是Gemini?
Gemini AI是由Google AI开发的一系列大型语言模型(LLMs),它以在多模态理解和处理方面的卓越能力而著称。与以往的LLM不同,Gemini不仅仅是一个文本处理工具,更是一个能够处理各种数据类型的强大人工智能平台。
Gemini 的核心特性
- 多模态能力:
Gemini最显著的特点是其多模态能力。传统的LLM主要集中于文本处理,而Gemini则可以无缝处理文本、图像、音频甚至代码。这意味着它可以理解和响应涉及不同数据组合的复杂提示。例如,我们可以向Gemini展示一张图片,并要求它描述图片中的内容,或者提供一段文本指令,让它根据这些指令生成一幅图像。

- 跨数据类型的推理能力:
Gemini能够理解和处理多种形式的数据,使其能够掌握涉及复杂概念和情境的推理。例如,我们可以向Gemini展示一个科学图表,并要求它解释其中的过程。这种多模态能力在处理复杂问题时非常有用。 - 三种不同尺寸的模型:
Gemini提供三种不同尺寸的模型,以满足不同的应用需求:- Ultra: 这是最强大、最有能力的模型,适用于处理科学推理或代码生成等高度复杂的任务。
- Pro: 这是一款全面的模型,适用于各种任务,可以在性能和效率之间实现平衡。
- Nano: 这是最轻量高效的模型,非常适合在设备上运行,特别是在计算资源有限的情况下。
- TPU加速:
Gemini利用谷歌定制设计的张量处理单元(TPU),与较早期的LLM模型相比,大大提高了处理速度。TPU是一种专门为机器学习工作负载设计的硬件加速器,可以显著提高模型的训练和推理速度。
如何获取 Gemini API 密钥
要访问Gemini API并开始使用其强大的功能,您需要在Google的MakerSuite上注册并获取免费的Google API密钥。MakerSuite是由Google提供的一个用户友好的平台,它提供了一个基于视觉的界面,方便用户与Gemini API进行交互。
在MakerSuite中,您可以通过直观的用户界面无缝地使用生成模型,并可以根据需要生成API密钥,以实现更强大的控制和自定义能力。
以下是生成Gemini API密钥的步骤:
- 访问ai.google.dev/gemini-api/…。请注意,注册可能与您的地区和年龄有关。
- 阅读并接受服务条款,然后单击“继续”按钮。
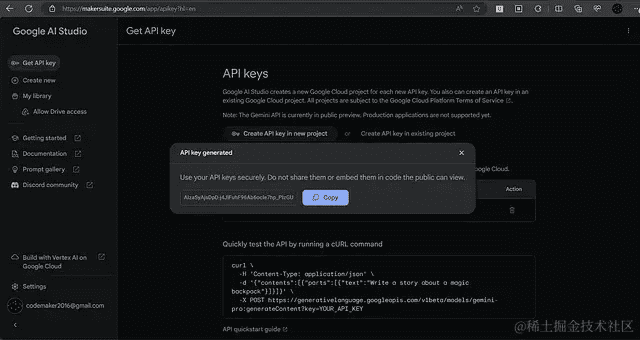
- 在侧边栏中,单击“获取 API 密钥”链接,然后单击“在新项目中创建 API 密钥”按钮以生成密钥。
- 复制生成的 API 密钥,并妥善保管。

搭建您的 Gemini 聊天机器人
拿到 API 密钥之后, 就可以开始搭建自己的聊天机器人了。以下是详细步骤,从环境配置到代码编写,让您轻松上手。
1. 环境配置
首先,确保您的系统满足以下要求:
- Python 3.9+:建议使用 Python 3.9 或更高版本,以获得最佳的兼容性和性能。
- pip:Python 的包管理器,用于安装所需的库。
接下来,使用 pip 安装 google-generativeai 库。在命令行或终端中运行以下命令:
pip install google-generativeai2. 初始化 Gemini 模型
在 Python 代码中,首先需要导入 google.generativeai 模块,并使用您的 API 密钥初始化 Gemini Pro 模型:
import google.generativeai as genai
GOOGLE_API_KEY = "YOUR_API_KEY"
genai.configure(api_key=GOOGLE_API_KEY)
model = genai.GenerativeModel('gemini-pro')请务必将 YOUR_API_KEY 替换为您实际的 API 密钥。
3. 创建聊天会话
为了保持对话的上下文,可以使用 model.start_chat() 方法创建一个聊天会话:
chat = model.start_chat(history=[])history 参数用于存储对话历史记录,以便模型能够理解上下文并生成更相关的回复。
4. 编写交互循环
接下来,编写一个交互循环,让用户可以输入消息并从 Gemini Pro 模型获得回复:
while True:
user_message = input("You: ")
if user_message.lower() == 'exit':
break
response = chat.send_message(user_message)
print("Gemini: {}".format(response.text))在这个循环中,程序会等待用户输入消息。如果用户输入 exit,循环将结束。否则,程序会将用户消息发送给 Gemini Pro 模型,并将模型的回复打印到屏幕上。
5. 添加视觉输入
Gemini 的多模态能力使其能够处理视觉输入。要添加视觉输入,可以使用 PIL 库加载图像,并将其传递给 chat.send_message() 方法:
from PIL import Image
image_path = 'path/to/your/image.jpg'
image = Image.open(image_path)
response = chat.send_message(parts=[image, "Describe this image."])
print(response.text)请确保将 path/to/your/image.jpg 替换为您实际的图像文件路径。在这个例子中,程序会将图像和文本提示“Describe this image.”一起发送给 Gemini Pro 模型,并打印模型的回复。
优化 Gemini 聊天机器人
以下是一些优化 Gemini 聊天机器人的技巧,以提高其性能和用户体验。
1. 上下文管理
Gemini 能够记住之前的对话内容,从而更好地理解用户的意图。可以通过维护一个对话历史记录列表来实现上下文管理。每次用户发送消息时,将消息和模型的回复添加到历史记录中。在下一次对话时,将历史记录传递给 model.start_chat() 方法。
但是,需要注意的是,过长的对话历史记录可能会影响模型的性能。因此,建议限制历史记录的长度,或者定期清理历史记录。
2. 错误处理
在使用 Gemini API 时,可能会遇到各种错误,例如 API 调用失败、网络连接错误等。为了提高程序的健壮性,需要添加适当的错误处理机制。可以使用 try...except 语句来捕获异常,并在发生错误时进行处理。
例如,可以添加以下代码来捕获 API 调用失败的异常:
try:
response = chat.send_message(user_message)
print("Gemini: {}".format(response.text))
except Exception as e:
print("Error: {}".format(e))3. 参数调优
Gemini API 提供了许多参数,可以用来控制模型的行为。例如,可以使用 temperature 参数来控制模型生成文本的随机性。较高的温度值会使模型生成更多样化的文本,而较低的温度值会使模型生成更保守的文本。
可以使用 top_p 参数来控制模型生成文本的多样性。较高的 top_p 值会使模型生成更多样化的文本,而较低的 top_p 值会使模型生成更保守的文本。
可以使用 max_output_tokens 参数来控制模型生成文本的最大长度。
可以根据实际需求调整这些参数,以获得最佳的性能。
4. Prompt工程
Prompt工程是设计有效的提示语,以引导语言模型生成所需输出的过程。一个好的提示语可以显著提高模型的性能。
以下是一些 Prompt工程的技巧:
- 明确指令: 确保您的指令清晰、明确,避免歧义。
- 提供上下文: 向模型提供足够的上下文信息,以便模型能够理解您的意图。
- 使用示例: 提供一些示例,以帮助模型理解您期望的输出格式。
- 迭代优化: 不断尝试不同的提示语,并根据模型的输出结果进行调整。
通过不断优化提示语,可以显著提高 Gemini 聊天机器人的性能。
5. 多模态 Prompt设计
对于多模态输入,Prompt的设计更为重要。需要考虑如何将图像、音频等信息与文本指令有效地结合起来。
以下是一些多模态 Prompt设计的技巧:
- 描述图像内容: 使用文本描述图像中的内容,以便模型能够理解图像的含义。
- 提出具体问题: 提出与图像内容相关的问题,以引导模型生成更相关的回复。
- 结合文本指令: 将文本指令与图像信息结合起来,以实现更复杂的功能。
通过巧妙地设计多模态 Prompt,可以充分发挥 Gemini 的多模态能力。
Gemini 的应用场景
Gemini 的多模态能力使其在许多领域都有广泛的应用前景。
1. 图像理解
Gemini 可以用于图像理解任务,例如图像描述、物体识别、场景理解等。例如,可以向 Gemini 展示一张图片,并要求它描述图片中的内容,或者识别图片中的物体。
2. 视频分析
Gemini 可以用于视频分析任务,例如视频描述、动作识别、事件检测等。例如,可以向 Gemini 展示一段视频,并要求它描述视频中的内容,或者识别视频中的动作。
3. 智能客服
Gemini 可以用于智能客服系统,通过理解用户的文本、语音或图像输入,提供个性化的服务。例如,用户可以通过语音向 Gemini 提出问题,Gemini 可以通过分析用户的语音和上下文,提供准确的答案。
4. 内容创作
Gemini 可以用于内容创作,例如文章生成、故事创作、代码生成等。例如,可以向 Gemini 提供一些关键词或主题,Gemini 可以根据这些信息生成一篇完整的文章。
5. 教育领域
Gemini 可以用于教育领域,例如智能辅导、作业批改、知识问答等。例如,学生可以通过向 Gemini 提出问题,Gemini 可以提供详细的解答和辅导。
总结
Gemini 作为新一代的多模态大型语言模型,具有强大的理解和生成能力。通过本文的介绍,相信您已经了解了如何使用 Gemini API 构建智能聊天机器人,并掌握了一些优化技巧。希望您能够充分发挥 Gemini 的潜力,创造出更多创新应用。








