
大型语言模型(LLM)的出现,无疑是人工智能领域近年来最引人注目的进展之一。这些模型展现出卓越的语言理解和生成能力,为各行各业带来了前所未有的机遇。它们能够执行多种多样的任务,极大地扩展了人机交互的可能性,同时也为我们打开了一个通往智能应用的新世界。
LLM的常见应用场景:
1. 内容创作的强大助手:
- 突破写作瓶颈: LLM可以作为您的得力助手,助您摆脱写作困境。它不仅能提供丰富的主题构思,还能优化段落结构,润色语句表达,从而显著提高写作效率和文章质量。想象一下,当你面对一篇需要深度分析的报告时,LLM可以快速生成多个版本供你参考,极大地节省了你的时间和精力。
- 文章生成的无限可能: LLM能够根据您的特定需求,创作出各种类型的文章,包括但不限于新闻报道、引人入胜的故事、优美的诗歌等。更令人惊叹的是,它甚至可以模仿特定作家的写作风格,使得生成的文章更具个性化和专业性。比如,你可以让LLM模仿海明威的简洁风格来撰写一篇短篇小说。
- 营销文案的智能生成: LLM能够帮助您生成极具吸引力的广告语、详尽的产品描述以及引人注目的社交媒体内容,从而有效提高营销效果。一个好的营销文案往往能够迅速抓住用户的眼球,而LLM则能在这个方面提供强大的支持。比如,它可以根据产品特点,快速生成多个版本的广告语,并进行A/B测试,选出最佳方案。
2. 翻译与语言学习的桥梁:
- 实时翻译,打破语言壁垒: LLM能够提供实时翻译服务,轻松实现不同语言之间的文本转换,从而打破语言障碍,促进跨文化交流。无论您是出国旅行还是与国际友人交流,LLM都能成为您的得力助手。想象一下,当你参加一个国际会议时,LLM可以实时翻译演讲内容,让你轻松理解。
- 个性化语言学习伙伴: LLM能够提供定制化的语言学习体验,包括练习对话、精准翻译、深入语法讲解和丰富词汇拓展等,从而全方位助力您掌握新语言。比如,你可以通过LLM模拟真实的对话场景,提高口语表达能力。
3. 代码开发的效率引擎:
- 代码自动生成: LLM能够根据您的自然语言描述,智能生成相应的代码,从而简化编程流程,显著提高开发效率。这对于程序员来说,无疑是一个巨大的福音。比如,你可以简单描述一个功能需求,LLM就能自动生成相应的代码框架。
- 智能代码调试: LLM能够快速识别代码中的错误,并提供详细的修复建议,从而加速调试过程,确保代码质量。这对于新手程序员来说,尤其具有帮助。比如,当你遇到一个难以解决的bug时,LLM可以帮助你快速定位问题所在。
Gemini:Google AI 的杰出代表
Gemini是由Google AI倾力打造的一款大型语言模型(LLM)。它不仅是一个强大的AI系统,更能够以媲美人类的水平理解和生成文本、代码以及各种其他形式的内容。Gemini的出现,标志着人工智能技术又向前迈进了一大步。
Gemini的主要特点:
- 多模态理解与生成: Gemini能够无缝处理和生成文本、代码、图像和音频等多种模态的数据,使其成为一个真正的通用AI系统。这意味着Gemini不仅可以理解文字,还能看懂图片、听懂声音,并根据这些信息生成各种内容。例如,你可以给Gemini一张图片,让它用文字描述图片的内容,或者根据一段文字描述,让它生成相应的图像。
- 高级推理与问题解决能力: Gemini具备卓越的推理能力,能够解决复杂的问题,并提供富有洞察力的解决方案。这使得Gemini在处理复杂任务时,能够像人类专家一样进行思考和判断。例如,你可以给Gemini一个复杂的数学问题,它不仅能给出答案,还能详细解释解题思路。
- 上下文感知能力: Gemini能够在对话过程中保持上下文的连贯性,确保其响应始终与语境相关。这意味着与Gemini的对话更加自然流畅,避免了传统AI对话中常见的“答非所问”的情况。
- 海量知识储备: Gemini经过海量数据集的训练,拥有庞大的知识库,能够回答各种各样的问题。无论您的问题是关于历史、科学、文化还是其他领域,Gemini都能提供准确而全面的答案。
- 代码生成与调试: Gemini能够使用各种编程语言生成代码,并提供代码调试方面的帮助,极大地提高了软件开发的效率。这对于程序员来说,是一个非常实用的工具。
- 翻译与摘要: Gemini能够将文本翻译成不同的语言,并生成简洁的摘要,方便用户快速获取信息。这对于跨语言交流和信息检索来说,非常有价值。
- 创意内容生成: Gemini能够创作故事、诗歌和其他形式的创意内容,为用户提供灵感和帮助。这使得Gemini不仅是一个工具,更是一个创意伙伴。
Gemini的工作原理:
Gemini是一个基于Transformer架构的深度学习模型。它通过监督和无监督学习技术,接受了海量文本、代码和其他数据的训练。这种训练使得Gemini能够学习数据中的模式和关系,从而执行各种任务。
Gemini的应用:
- 智能聊天机器人与对话式AI: Gemini可以用于创建引人入胜且信息丰富的聊天机器人,应用于客户服务、教育和娱乐等领域。例如,Gemini可以构建一个智能客服机器人,24小时在线解答用户的问题。
- 高效内容创作: Gemini能够生成文章、博客文章、社交媒体内容和其他形式的书面材料,极大地提高了内容创作的效率。例如,Gemini可以帮助营销人员快速生成各种广告文案。
- 助力软件开发: Gemini能够帮助开发人员进行代码生成、调试和文档编写,从而提高软件开发的效率和质量。例如,Gemini可以自动生成代码注释,提高代码的可读性。
- 精准翻译与本地化: Gemini能够将文本翻译成不同的语言,并将内容适应不同的文化,从而促进跨文化交流。例如,Gemini可以将一个英文网站自动翻译成中文,并根据中国用户的习惯进行优化。
- 深入研究与分析: Gemini能够分析数据、提取见解并生成报告,为研究人员和分析师提供强大的支持。例如,Gemini可以分析大量的市场数据,帮助企业制定更有效的营销策略。
Gemini与其他LLM的比较:
Gemini被认为是目前最先进的LLM之一。它在多模态能力、推理能力和知识库方面超越了以前的模型。这意味着Gemini能够处理更复杂的任务,并提供更准确、更全面的答案。
 局限性:
局限性:
- 偏见与公平: 像所有LLM一样,Gemini会根据其接受过训练的数据表现出偏见。这意味着Gemini可能会生成带有偏见或歧视性的内容。因此,在使用Gemini时,需要注意审查其生成的内容,确保其符合伦理道德标准。
- 缺乏常识: Gemini可能难以完成需要常识推理的任务。虽然Gemini拥有庞大的知识库,但它并不具备人类的常识。因此,在使用Gemini时,需要注意其局限性,避免过度依赖。
- 伦理问题: 生成假新闻或操纵信息等潜在的滥用可能性令人担忧。由于Gemini具有强大的文本生成能力,因此存在被用于生成虚假信息或进行网络攻击的风险。因此,需要加强对Gemini的监管,防止其被滥用。
2024年Google开发者大会,Gemini成为绝对焦点。
回归本源
接下来,我们将深入探讨Gemini在项目中的实际应用:
- Gemini在项目中的集成方法
- Gemini在处理文字、声音和视频方面的强大能力
- 在Android Studio (AS) 中使用Gemini功能的技巧以及代码优化策略
- Google AI Studio的使用指南
一、如何在项目中使用Gemini
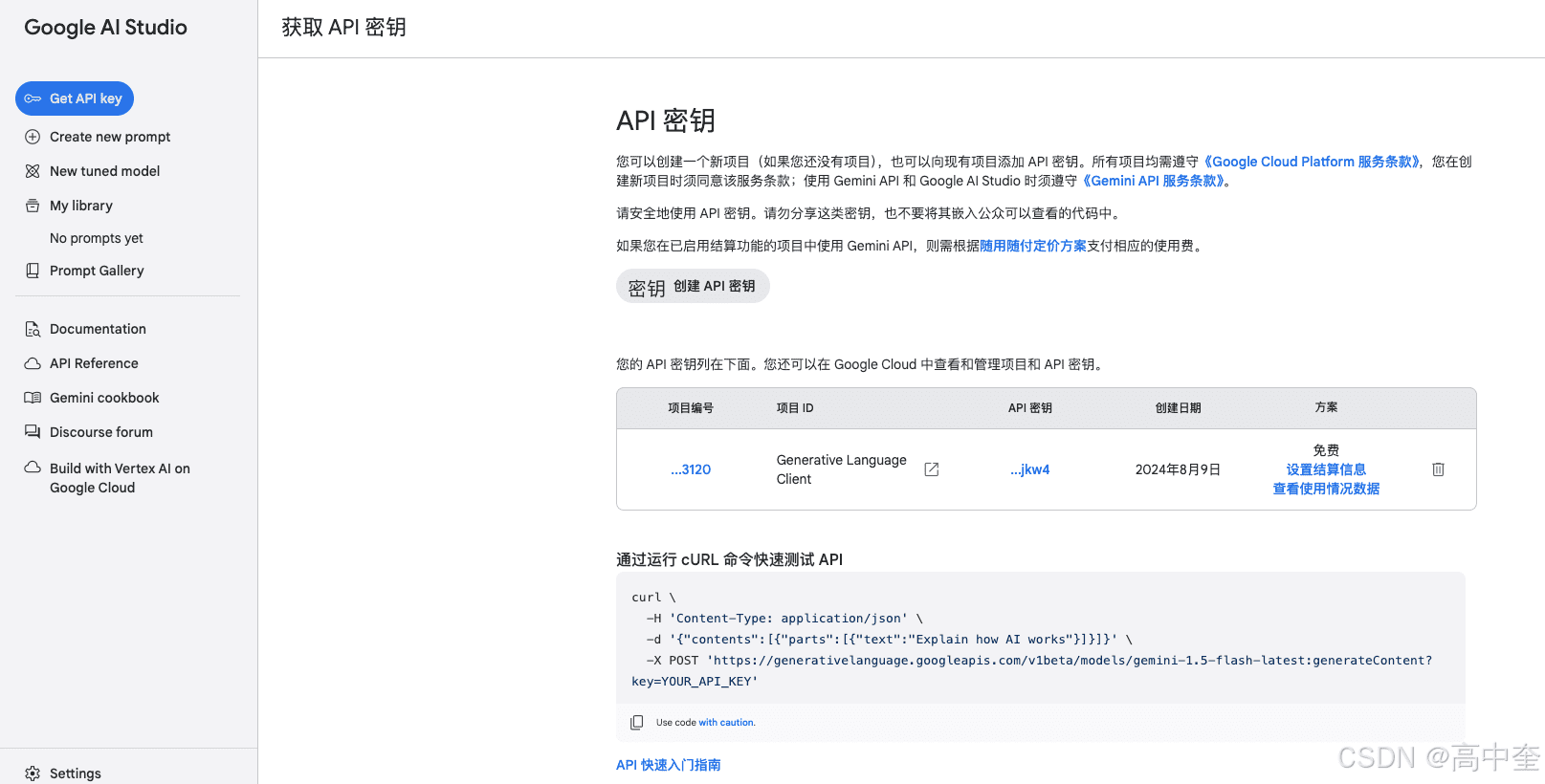
1、Gemini API_KEY申请流程
首先,您需要申请一个API_KEY,访问申请网站。
重要提示:您必须在Google Cloud中已存在项目,才能创建API_KEY。
请注意,API_KEY的免费使用次数是有限制的。
这意味着您每分钟最多可以发送15个请求,每天最多可以发送1500个请求。当然,付费用户可以享受更高的请求额度。
2、Gemini SDK 接入
引入Gemini SDK:官方教程
dependencies {
// add the dependency for the Google AI client SDK for Android
implementation("com.google.ai.client.generativeai:generativeai:0.7.0")
}初始化模型
在进行任何API调用之前,您需要先导入并初始化模型。Gemini 1.5 模型因其广泛的用途和相对较多的免费使用次数而备受青睐。
val generativeModel = GenerativeModel(
modelName = "gemini-1.5-flash",
// Access your API key as a Build Configuration variable (see "Set up your API key" above)
apiKey = BuildConfig.apiKey
)发出第一个请求
建议在协程中使用,以下是一个阻塞式请求的示例:
lifecycleScope.launch(Dispatchers.IO) {
val prompt = "请问中国有多个民族,以及中国有多大的面积"
val response = generativeModel.generateContent(prompt)
Log.d(TAG, "testGemini() called ${response.text}")
}在测试过程中,您可能会遇到请求失败的问题。请务必注意,目前Gemini仅在部分国家/地区开放。如果您的国家/地区不在可用国家/地区列表中,则请求将直接失败。
- 中国->台湾
- 中国->日本
二、 使用Gemini处理文字、声音、视频
1、文字的处理
根据纯文本输入生成文本
使用Gemini API生成文本的最简单方法是提供单个文本的输入,如下例所示:
lifecycleScope.launch(Dispatchers.IO) {
val generativeModel = GenerativeModel(
modelName = "gemini-1.5-flash",
// Access your API key as a Build Configuration variable (see "Set up your API key" above)
apiKey = API_KEY
)
val prompt = "写一个关于一个神奇背包的故事"
val response = generativeModel.generateContent(prompt)
Log.d(TAG, "testGemini() called ${response.text}")
}在此示例中,提示(”写一个关于一个神奇背包的故事“)没有添加任何输出示例、系统指定或者格式信息。对于某些应用场景单次或者少样本提示可能会生成更符合用户预期的输出。在某些情况下您可能还希望提供系统说明,以帮助模型了解任务或遵循具体的指南。
根据文本和图片输入生成文本
Gemini API 支持将文本与媒体文件相结合的多模态输入。以下示例展示了如何根据文本和图片输入生成文本:
lifecycleScope.launch(Dispatchers.IO) {
val inputContent = content {
image(
BitmapFactory.decodeResource(resources, R.mipmap.test))
text("这个图片中主要的色素是啥?")
}
val generativeModel = GenerativeModel("gemini-1.5-flash", API_KEY)
val response = generativeModel.generateContent(inputContent)
Log.d(TAG, "testImageByText() called ${response.text}")
}与纯文本提示一样,多模态提示可能涉及多种方法以及优化。此处只是使用了mipmap目录中的图片,不过你也可以使用SD卡中的图片。通过此方法即可: BitmapFactory.decodeFile()
生成文本流
默认情况下,模型会在填完整个文本后返回回答生成过程。你可以实现更快的互动,即不等待整个结果,而改用流式传输来处理部分结果。以下示例展示了如何使用generateContentStream 方法根据纯文本输入提示生成文本。
lifecycleScope.launch(Dispatchers.IO) {
val generativeModel = GenerativeModel("gemini-1.5-flash", API_KEY)
val prompt = "请写一篇200字的小短文"
val stream = generativeModel.generateContentStream(prompt)
stream.collect {
Log.d(TAG, "testFlowTest() ${it.text}")
}
}构建互动式聊天
您可以使用Gemini API为用户打造互动式聊天体验。通过使用该API的聊天功能,您可以收集多轮文件和回答,让用户能够追逐需求答案或者获取帮助解决多部分问题。此功能非常适合以下要求的应用:持续沟通,例如聊天机器人、互动式导师或者客服服务助理。
以下代码示例展示了基本的聊天实现:
lifecycleScope.launch(Dispatchers.IO) {
val generativeModel = GenerativeModel("gemini-1.5-flash", API_KEY)
val chat = generativeModel.startChat(
history = listOf(
content(role = "user")
{ text("我叫高中奎") },
content(role = "model") {
text("请问有什么可能帮助你的吗?")
})
)
var response = chat.sendMessage("请问我叫什么名字,以后回答的时候,请在回答问题的时候都要加上这个尊称")
Log.d(TAG, "testChatTest() called ${response.text}")
response = chat.sendMessage("中国有多大的面积?")
Log.d(TAG, "testChatTest() called ${response.text}")
}如果大家想构建互动式聊天流,请使用如下示例展示:
val generativeModel =
GenerativeModel(
modelName = "gemini-1.5-flash",
apiKey = API_KEY)
val chat =
generativeModel.startChat(
history =
listOf(
content(role = "user") { text("Hello, I have 2 dogs in my house.") },
content(role = "model") {
text("Great to meet you. What would you like to know?")
}))
chat.sendMessageStream("How many paws are in my house?").collect { chunk ->
Log.d(TAG, "testChatTest() called ${chunk.text}") }如果在想在聊天的过程中加入图片的使用,请使用如下示例展示:
val generativeModel =
GenerativeModel(
modelName = "gemini-1.5-flash",
apiKey = API_KEY)
val chat =
generativeModel.startChat(
history =
listOf(
content(role = "user") { text("Hello, I have 2 dogs in my house.") },
content(role = "model") {
text("Great to meet you. What would you like to know?")
}))
val image: Bitmap = BitmapFactory.decodeResource(context.resources, R.drawable.image)
val inputContent = content {
image(image)
text("This is a picture of them, what breed are they?")
}
chat.sendMessageStream(inputContent).collect { chunk ->
Log.d(TAG, "testChatTest() called ${chunk.text}")
}配置文本生成
您发送给模型的每个提示都包含参数,控制模型生成响应的方式。您可以使用generationConfig至配置这些参数如果您不配置参数,则模型使用默认选项,具体选项可能因模型而异。 以下示例展示了如何配置多个可用的选项。
lifecycleScope.launch(Dispatchers.IO) {
val generativeModel = GenerativeModel(
modelName = "gemini-1.5-pro",
apiKey = API_KEY, generationConfig = generationConfig {
responseMimeType = "application/json"
responseSchema = Schema(
name = "recipes",
description = "List of recipes",
type = FunctionType.ARRAY,
items = Schema(
name = "recipe",
description = "A recipe",
type = FunctionType.OBJECT,
properties = mapOf(
"recipeName" to Schema(
name = "recipeName",
description = "Name of the recipe",
type = FunctionType.STRING,
),),
required = listOf("recipeName")
),
)
})
val prompt = "List a few popular cookie recipes."
val response = generativeModel.generateContent(prompt)
Log.d(TAG, "testConfigTest() ${response.text}")
}大家可以根据自己的需求,细微调整模型的输出。具体的大家可以去官方了解
2、图片的处理
对于图片的处理,上文中已经使用了,在此就不做过多叙述了








