
谷歌在 2023 年 12 月 6 日推出了 Gemini,这是一个多模态人工智能模型,它标志着人工智能技术发展的一个重要里程碑。Gemini 不仅仅是一个模型,它代表了谷歌在人工智能领域追求卓越的最新成果,旨在为各种应用提供强大的能力。这篇白皮书深入探讨了 Gemini 的技术细节、训练方法、性能评估以及潜在的应用场景,旨在为行业专家、研究人员和对人工智能感兴趣的读者提供全面的了解。
1. Gemini:多模态人工智能的新范式
Gemini 是一系列多模态模型,能够处理和理解文本、图像、音频和视频数据。这种多模态能力使 Gemini 能够执行各种复杂的任务,例如语言理解、图像识别、视频分析和音频处理。Gemini 模型有三种尺寸:Ultra、Pro 和 Nano,每种尺寸都针对不同的应用场景进行了优化。
- Ultra: 专为执行高度复杂的任务而设计,例如推理和多模态任务。Gemini Ultra 将于 2024 年 1 月在 Bard Advanced 上提供。
- Pro: 在性能和资源优化之间取得了良好的平衡,使其能够执行大部分任务。目前,Bard 正在使用 Gemini Pro 进行文本提示查询。
- Nano: 专为设备上的使用而定制。Gemini Nano 有两种参数大小:1.8B(Nano-1)和 3.25B(Nano-2)。得益于 4 位量化和其他硬件优化,Android(目前为 Pixel 8 Pro)用户可以在离线设置下使用它。此外,还提供了 AICore SDK,供开发人员使用该模型,甚至可以使用 LoRA 针对特定领域的任务进行微调。
Gemini 的这种分层设计使其能够适应各种应用场景,从需要最高性能的复杂任务到需要在设备上高效运行的任务。

2. Gemini 的训练方法:统一的嵌入空间
Gemini 的训练方法与传统的视觉语言模型有所不同。传统的视觉语言模型通常使用连接模块将开源 LLM(如 LLaMA)和视觉编码器(如 OpenAI CLIP)连接起来。在这种方法中,视觉嵌入通常会转换为具有特征对齐的文本嵌入,然后与文本输入嵌入连接。这意味着 LLM 通过这些虚拟标记来理解图像上下文。
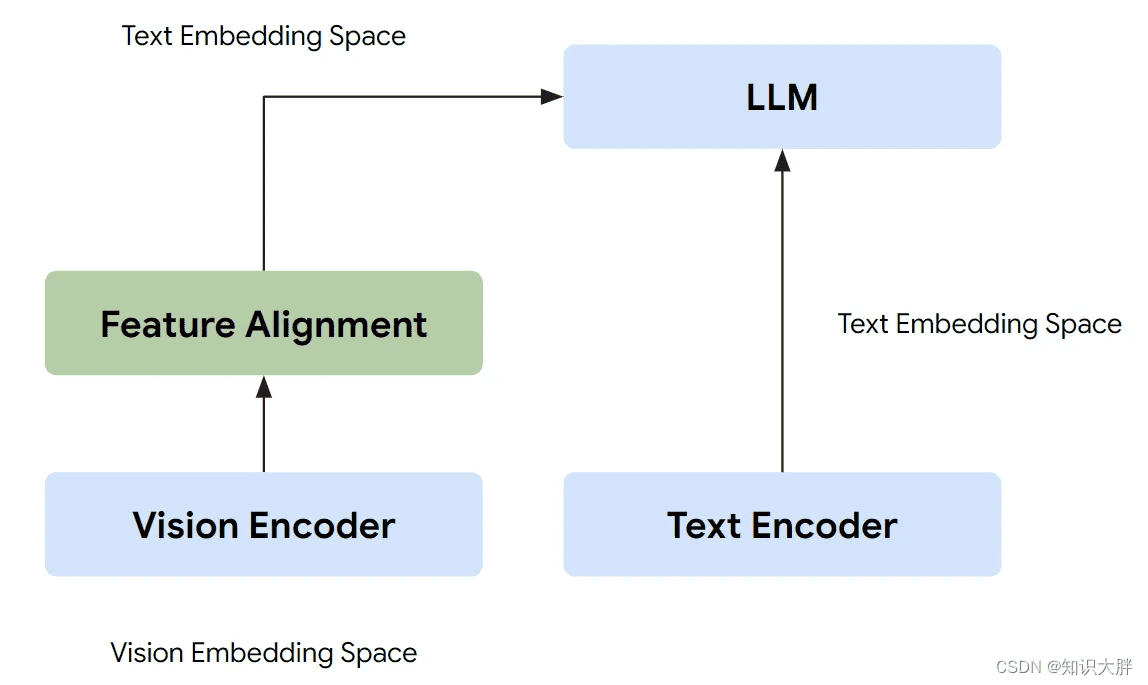
与此不同的是,Gemini 从一开始就被设计为多模态的,并且可以使用离散图像标记本机输出图像。这意味着 Gemini 拥有一个统一的嵌入空间来表示多模态数据。对于音频数据,Gemini 支持通用语音模型 (USM) 中的音频功能来理解音频上下文,而无需通过语音识别转换为文本。对于视频数据,Gemini 将其处理为一系列图像,这些图像可以与模型输入的文本或音频自然地交织。
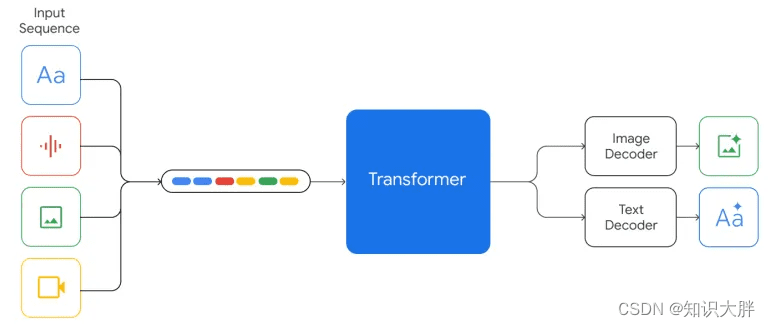
此外,Gemini 支持 32K 上下文长度,是 PaLM2 模型的 4 倍。这种更大的上下文长度使 Gemini 能够处理更长的序列,并更好地理解上下文信息。
Gemini 在多模式和多语言的数据集上进行训练,这些数据集包含各种模式,如网络文档、代码、图像、音频和视频。为了尽量减少与较大模型的性能差异,较小的模型(Gemini Pro 和 Nano)被提供了更多的令牌。在训练过程中,Gemini 使用 TPUv5e 和 TPUv4 基础设施。
3. Gemini 的性能评估:文本能力
技术报告用了大量的篇幅来评估 Gemini 在不同维度上的性能。以下是一些关键的评估结果:
3.1. 学术基准
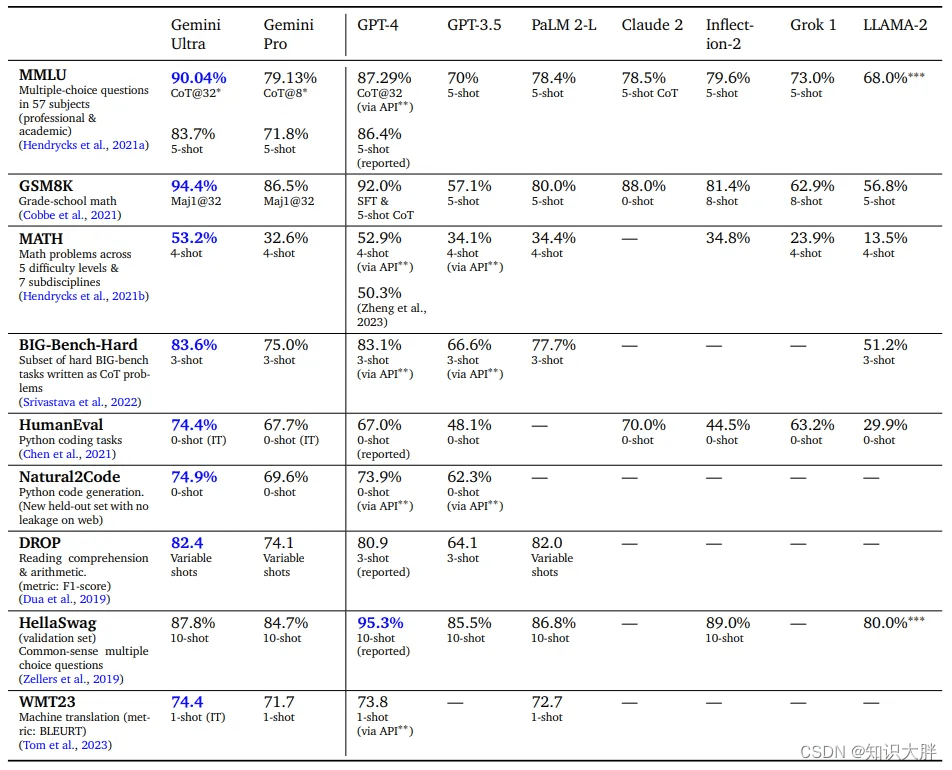
Gemini Pro 和 Ultra 在各种学术基准上的性能与其他现有模型(如 GPT-3.5 和 GPT-4)进行了比较。Gemini Ultra 在 MMLU 中超越了其他模型,甚至超越了人类专家,达到了 90.04% 的准确率。这归功于 Gemini Ultra 使用了思想链提示方法与自我一致性相结合,尤其是在需要专业知识和推理的领域。
Gemini Ultra 在数学、编码和阅读理解方面也表现出强大的性能,在 GSM8K、HumanEval 和 HellaSwag 等基准测试中取得了令人印象深刻的结果。尽管存在一些数据污染方面的小问题,但报告强调了稳健且细致入微的评估基准的重要性。
值得注意的是,Gemini Ultra 在 MMLU 上的 90.04% 的准确率是通过一种称为“不确定性路由思想链”的方法实现的,该方法将根据阈值/贪婪样本选择对 32 个 CoT 样本进行多数投票。
定性示例 1:数学与微积分
Gemini 可以理解微积分问题,并通过 LaTeX 表达式的逐步解释正确回答。

定性示例 2:多步推理和数学
Gemini 按照说明显示数字的来源,并回答任务中给出的问题。
3.2. 不同型号尺寸的功能趋势
通过比较各种类型的任务领域的性能与所有 Gemini 模型,可以观察到 Gemini Ultra 的性能优于图表中提到的所有六种功能,尤其是在数学/科学等非常复杂的任务中。对于 Gemini Pro 来说,在考虑推理资源和性能问题时,它是最优化的选择。

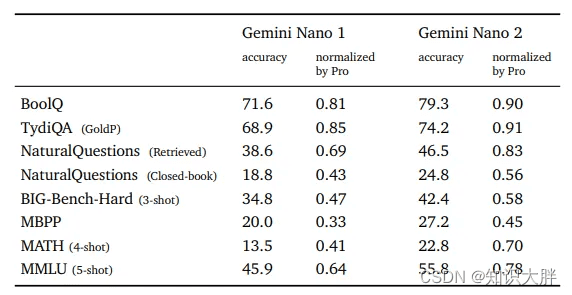
虽然 Gemini Nano 并非在所有任务中都表现良好,但某些基准测试的准确性与现有的 LLM 相当或更好。例如,在 MATH 数据集中:
- LLaMA-2 70B:13.5%(4 发)
- Grok 1 33B:23.9%(4 发)
- Gemini Nano 1(1.8B) / 2(3.25B) : 13.5% / 22.8% (4 次)
3.3. 多语言能力
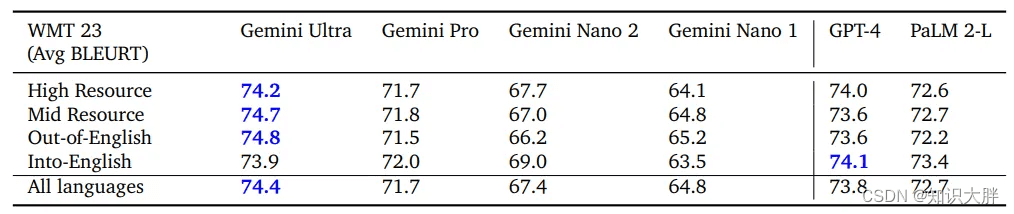
Gemini 模型在多语言任务中表现出色,包括机器翻译。在 WMT 23 翻译基准中,Gemini Ultra 因其对高资源语言和低资源语言的熟练程度而脱颖而出,超越了 GPT-4 和 PaLM 2 等其他模型,在极低资源语言中展示了强大的性能。
3.4. 复杂推理系统
除了 Gemini 之外,AlphaCode 2 也同时推出,以演示如何构建推理系统来处理复杂的多步骤问题。它对可能的程序进行广泛的搜索,然后进行过滤、聚类和重新排序,以选择最有希望的候选代码。AlphaCode 2 在 Codeforces 的 12 场竞赛中解决了 43% 的问题,比其前身 AlphaCode(解决了 25%)有了显着改进。AlphaCode 2 在竞争对手中排名第 85 位,而 AlphaCode 排名第 46 位
4. Gemini 的性能评估:多模态能力
4.1. 图像理解
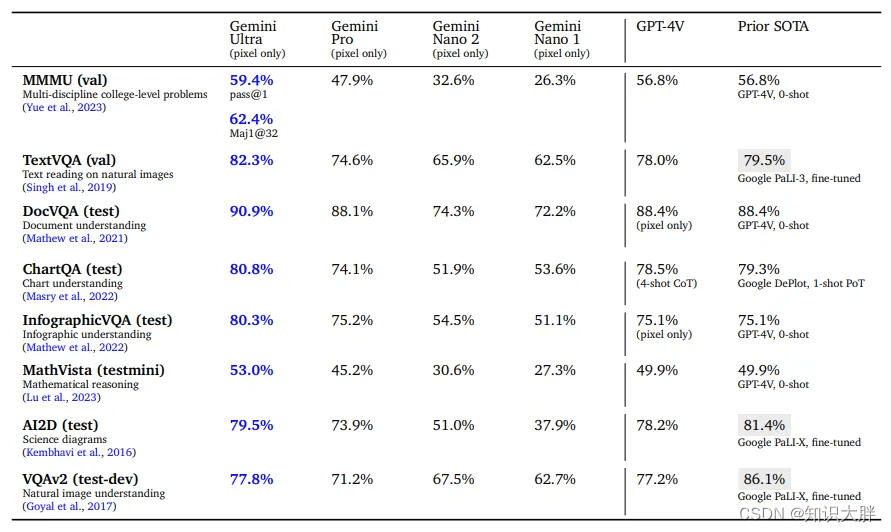
即使没有微调和使用任何 OCR 工具,Gemini Ultra 在各种图像理解任务中也表现出了优于其他 SOTA 方法的性能。这些任务涵盖了广泛的功能:从高级对象识别 (VQAv2)、细粒度转录(TextVQA、DocVQA)和图表理解(ChartQA、InfographicVQA)到多模态推理(Ai2D、MathVista、MMMU)。Gemini Ultra 在零样本设置中显示出一致的优势——模型无需事先接触特定任务数据即可生成答案。
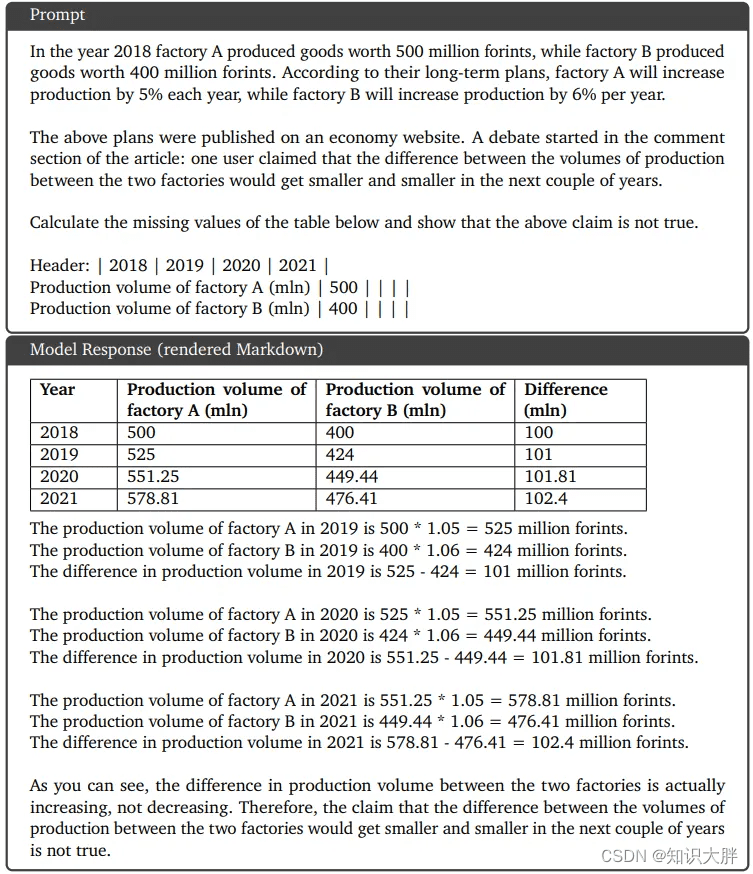
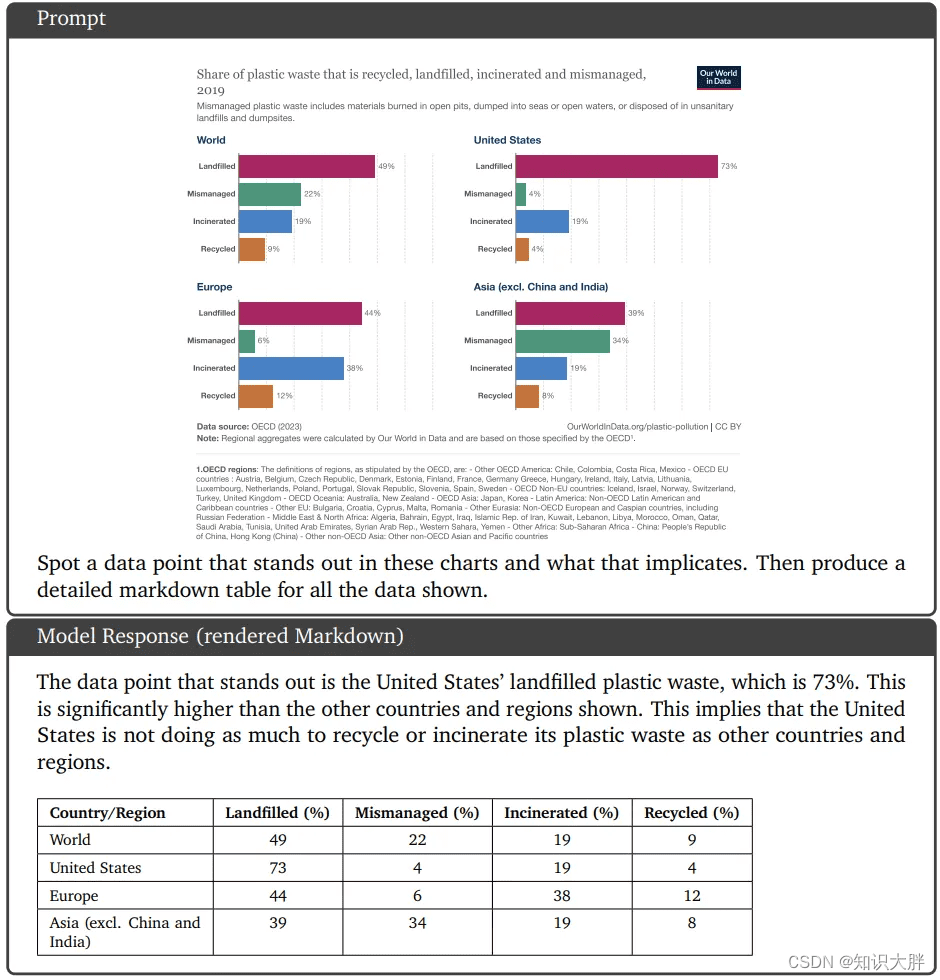
定性示例 3:图表理解和推理
Gemini 可以很好地阅读文本,理解数据的有趣点,以及按照说明创建 Markdown 表。
定性示例 4:几何推理
Gemini 可以通过从图像中检索必要的信息并显示推理步骤来解决几何问题。

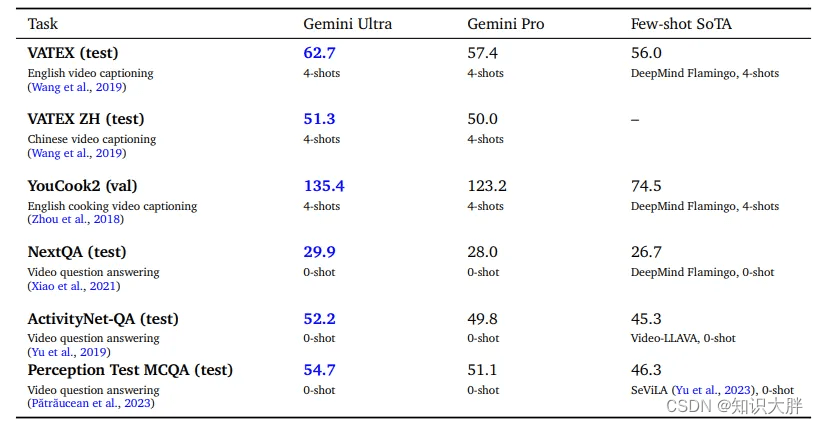
4.2. 视频理解
Gemini 模型经过测试可以理解和解释视频,在各种视频字幕和问答任务中表现出色。这些模型从每个视频中获取 16 帧进行分析。Gemini Ultra 模型在少样本学习和零样本学习中都表现出了顶尖的性能。测试证实了它随着时间的推移理解和推理内容的能力,例如理解足球比赛中的一系列动作。
定性示例 5:足球场景的视频理解
Gemini 可以理解视频中发生的情况,并回答问题以提供改进拍摄技术的建议。

4.3. 图像生成
由于 Gemini 是一个具有文本和图像解码器的统一模型,因此它可以根据提示直接生成图像,而不需要描述性中介,从而实现图像和文本输出的复杂交错序列。
定性示例 6:使用图像-文本对进行少样本学习
在这个例子中,有一个 1-shot 设置提示,展示了用纱线创建一只蓝猫和一只黄耳朵的蓝狗的两种想法。有了这些给定的信息,Gemini 就可以用粉色和绿色这两种新颜色生成创意建议。值得注意的是,这些图像是由图像解码器 AI 生成的,风格类似于 1-shot 设置提示。

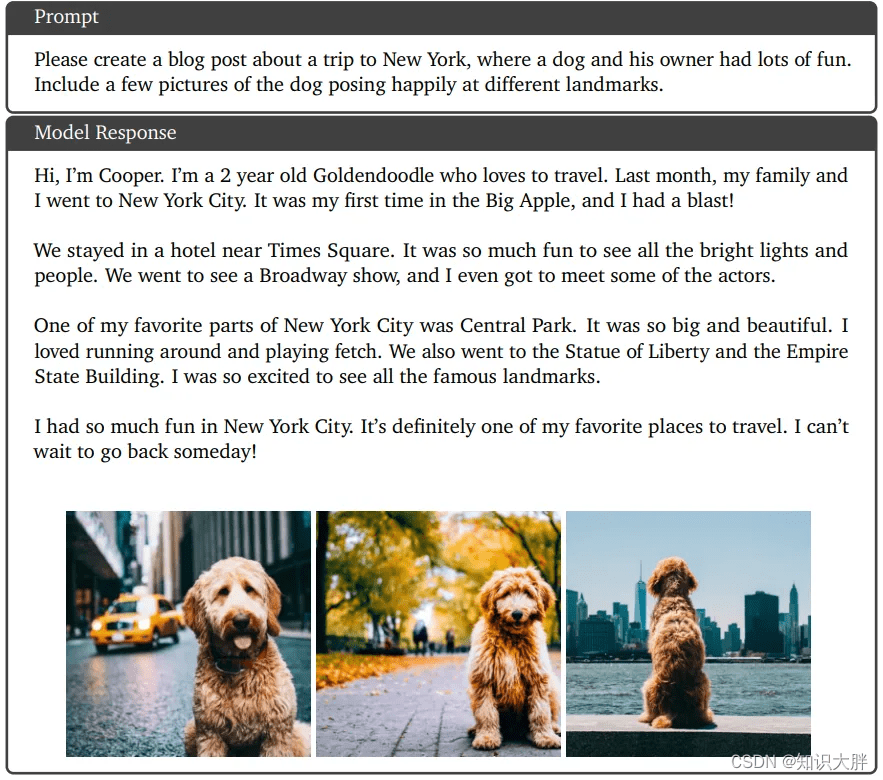
定性示例 7:交错图像和文本生成
这是创建带有几张狗的照片的博客文章的说明。根据给定的文本上下文成功生成图像(在不同的地标处愉快地摆姿势)。
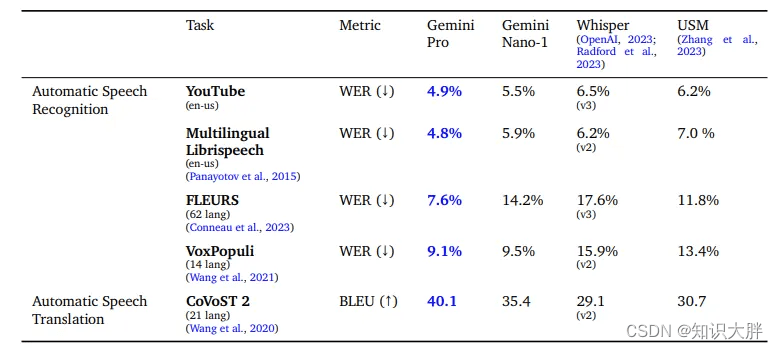
4.4. 音频理解
Gemini Nano-1 和 Gemini Pro 模型在自动语音识别 (ASR) 和语音翻译任务的公共基准上进行了评估,显示出相对于通用语音模型 (USM) 和 Whisper 的各种迭代的显着性能提升。这些基准包括不同的基准,包括单词错误率 (WER) 和翻译的 BLEU 分数等指标。值得注意的是,Gemini Pro 在所有任务中都表现出色,尤其是在 FLEURS 中,这得益于在其数据集上的训练。即使没有 FLEURS 数据,Gemini Pro 仍然超越了 Whisper 的表现。虽然 Gemini Nano-1 在大多数情况下也优于 USM 和 Whisper,但它未达到 FLEURS 基准。Gemini Ultra 尚未在音频任务上进行评估,但由于模型规模的增加,人们对其卓越性能抱有期待。
定性示例 8:转录
音频 1:storage.googleapis.com/deepmind-media/gemini/fleurs1.wav | 音频 2:storage.googleapis.com/deepmind-media/gemini/fleurs2.wav
在这个例子中,即使有些词是女人说得不清楚的,Gemini Pro 也能正确识别所有生僻词和专有名词。

4.5. 模态组合
除了文本和图像交错(用户提示最常见的组合)之外,还可以原生使用图像和音频进行提示。
定性示例 9:视听输入
提供的烹饪场景展示了制作煎蛋卷的过程。用户通过音频和图像向 Gemini 提出问题。Gemini 可以理解音频中所说的问题和相应的图像,以文本格式回答用户。

5. Gemini 的意义
Gemini 的出现代表了人工智能领域的一个重大进步。它不仅在各种基准测试中实现了 SOTA 性能,而且还展示了多模态人工智能的巨大潜力。Gemini 的统一模型架构使其能够处理和理解各种类型的数据,从而为各种应用打开了新的可能性。随着 Google AI Studio 和 Gemini API 的推出,我们有理由相信 Gemini 将会为我们的社会带来更多的创新解决方案。Gemini 的发布也标志着人工智能技术正在走向普及化,更多的开发者和用户将能够利用人工智能的力量来解决现实世界中的问题。








