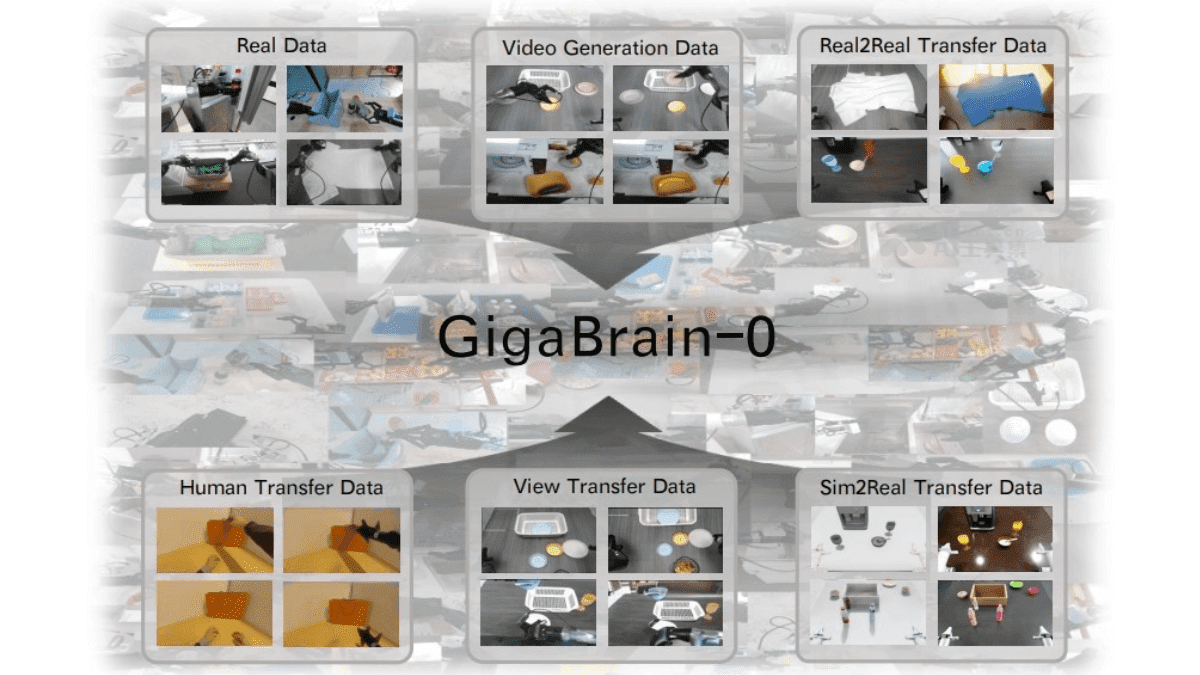
2025年,AI领域迎来关键转折点。AI智能体正式"破圈",从实验室精密算法走向千行百业生产一线,这一年被业界公认为"AI智能体元年"。随着AI应用井喷式增长,算力需求的底层逻辑正在悄然改变:从过去聚焦模型训练的"厚积",到现在转向AI推理的"薄发",推理环节正成为驱动算力增长的核心引擎。
对于企业而言,AI大模型的价值不再停留在"能做什么",而是"能做好什么、能低成本做好什么"。如何在推理环节实现"降本、提质、增效"的三重突破,打通商业落地的"最后一公里",成为所有从业者共同的考题。在这个关键节点,华为全联接大会2025期间的昇腾AI产业峰会带来了新答案。
AI大模型落地难,大EP适配MoE推理带来"最优解"
在全球AI大模型产业化进程中,推理环节作为技术价值转化的核心,直接决定着AI红利能否真正落地。如果说模型训练是"练兵千日",那推理就是"用兵一时"。尤其在DeepSeek推动MoE(混合专家)模型成为主流后,这一环节的重要性愈发凸显,同时也暴露出传统部署模式与新技术路线的适配矛盾。
MoE模型推理面临的挑战
MoE模型在带来性能提升的同时,也给推理部署带来了新的挑战:
- 单机部署瓶颈:专家权重的高占用率让内存不堪重负,直接限制了并发处理能力。
- 混合部署失衡:采用PD混合部署时,容易出现资源分配不均,造成算力浪费和整体性能衰减。
- 专家热点不均:MoE模型的动态路由机制常导致部分专家承担过量任务陷入瓶颈,其余专家却处于闲置状态,形成算力资源的结构性浪费。
这些架构层面的问题,最终转化为企业可感知的实操痛点,集中表现为"推不动、推得慢、推得贵":
- 硬件资源无法有效支撑长文本处理、多轮对话等复杂推理需求
- 输出结果的首Token时延居高不下,严重影响用户交互体验
- 单位时间内有效处理的Token数量不足,导致每Token成本高企
大EP架构的创新解决方案
面对MoE模型带来的推理瓶颈,昇腾在业界率先探索出以大EP架构创新为核心,结合超节点硬件及昇腾基础加速软件的"一体化破局