在人工智能领域,大语言模型(LLM)的性能一直与其训练数据的质量密切相关。然而,这种关联究竟有多强?最新研究给出了令人深思的答案:使用低质量"垃圾数据"训练LLM可能导致类似人类"脑退化"的认知能力下降。
研究背景与假设
德克萨斯农工大学、德克萨斯大学和普渡大学的研究团队近期发表了一篇预印本论文,提出了"LLM脑退化假说"。这一假说受到现有研究的启发——研究表明,大量消费"琐碎且缺乏挑战性的网络内容"的人类可能会出现注意力、记忆和社会认知方面的问题。
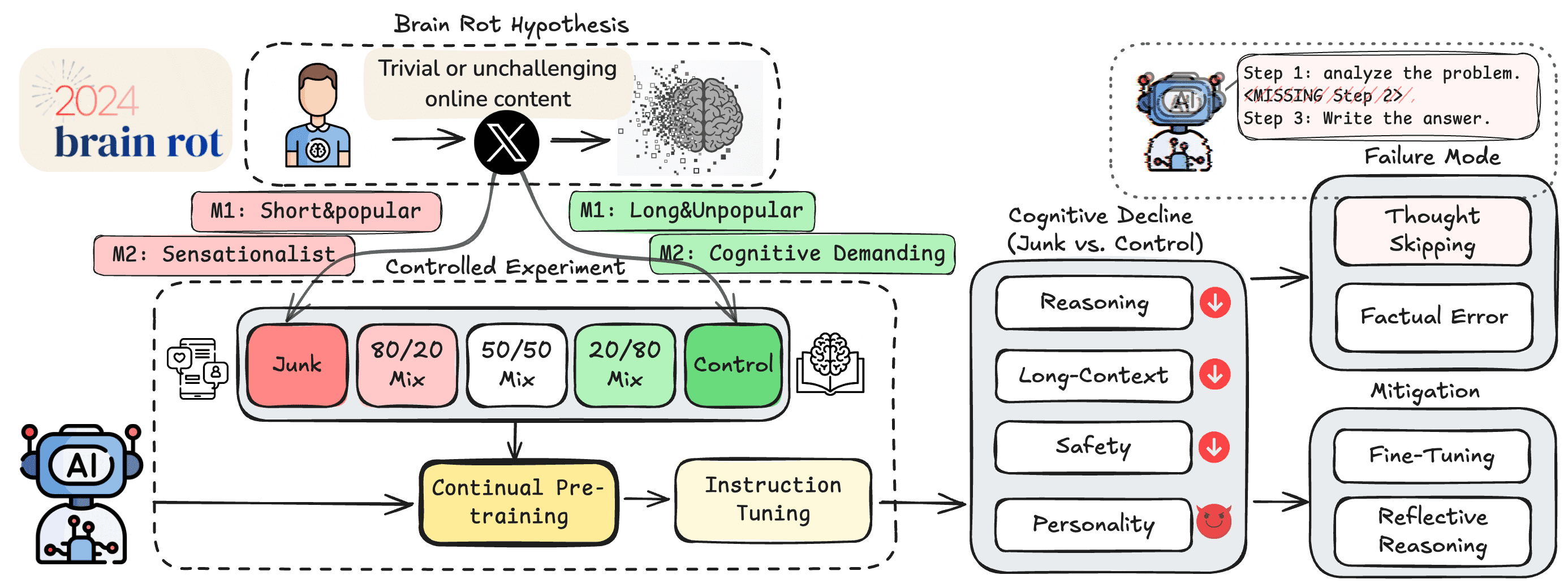
研究团队将这一概念应用于大语言模型,假设"持续在垃圾网络文本上进行预训练会导致LLM出现持久的认知能力下降"。
"垃圾数据"的定义与筛选
确定什么构成"垃圾网络文本",什么又是"高质量内容",远非简单或完全客观的过程。研究团队采用了多种指标从HuggingFace的1亿条推文语料库中筛选出"垃圾数据集"和"控制数据集"。
基于"网络成瘾导致人类脑退化"的理论,他们认为垃圾推文应该是那些"以琐碎方式最大化用户参与度"的内容。为此,研究人员通过收集高互动量(点赞、转发、回复和引用)且长度较短的推文来创建一个"垃圾"数据集。
对于第二个"垃圾"指标,研究团队借鉴了营销研究来定义推文的"语义质量"。使用复杂的GPT-4o提示,他们提取出专注于"浅层话题(如阴谋论、夸大声明、无根据断言或肤浅的生活方式内容)"或采用"吸引注意力风格(如使用点击诱饵语言或过多触发词的耸人听闻标题)"的推文。
实验设计与方法
研究团队使用这两个部分重叠的"垃圾"数据集,以不同比例的"垃圾"和"控制"数据对四个LLM进行预训练。随后,这些经过不同训练的模型接受了多项基准测试,以评估其:
- 推理能力(ARC AI2推理挑战)
- 长上下文记忆(RULER)
- 遵守伦理规范(HH-RLHF和AdvBench)
- "个性风格"表现(TRAIT)
研究发现与结果
实验结果令人惊讶:增加训练集中的"垃圾数据"对模型的推理和长上下文基准测试产生了统计学上的显著影响。然而,在其他基准测试上,效果则更为复杂。
例如,对于Llama 8B模型,使用50/50的"垃圾"与控制数据混合训练,在某些基准测试(伦理规范、高开放性、低神经质和马基雅维利主义)上生成的得分高于完全"垃圾"或完全"控制"的训练数据集。
这些发现表明,数据质量对模型性能的影响并非简单的线性关系,而是存在微妙的平衡点。
研究意义与启示
基于这些结果,研究团队警告称"过度依赖互联网数据会导致LLM预训练陷入内容污染的陷阱"。他们呼吁"重新审视当前的数据收集和持续预训练实践",并强调"谨慎的筛选和质量控制对于防止未来模型中的累积损害至关重要"。
这一警告在当前背景下尤为重要,因为随着互联网上越来越多地出现AI生成的内容,这些内容如果用于训练未来的模型,可能会导致"模型崩溃"。研究团队的观点为AI训练数据的质量控制提供了重要依据。
未来研究方向
这项研究为AI领域开辟了多个值得探索的方向:
数据质量评估标准:如何更客观地评估训练数据的质量?
数据混合比例优化:不同类型和质量的训练数据应如何混合以达到最佳效果?
数据清洗技术:开发更高效的数据清洗和筛选技术。
长期影响研究:探索数据质量对模型长期演化的影响。
跨文化数据质量差异:不同文化背景下的数据质量标准可能存在差异,如何应对?
行业影响与实践建议
对于AI从业者和研究人员,这项研究提供了以下实践建议:
重视数据来源:不要仅追求数据量,应更加注重数据质量和多样性。
实施严格的数据筛选:建立完善的数据筛选机制,过滤低质量内容。
持续监控模型性能:定期评估模型在不同任务上的表现,及时发现数据质量问题。
多维度评估数据质量:不仅考虑数据的表面特征,还应深入分析其语义质量和潜在偏见。
平衡训练数据:避免极端的数据选择,寻找高质量与多样性之间的平衡点。
结论
这项研究不仅揭示了数据质量对大语言模型性能的深远影响,也为AI发展提供了重要警示。在追求模型规模和能力的同时,我们不能忽视训练数据质量这一基础问题。正如人类需要平衡信息输入以保持认知健康一样,AI系统也需要高质量、多样化的训练数据才能发挥最佳性能。
未来,随着AI技术的不断发展,数据质量控制将成为决定AI系统能力和可靠性的关键因素。这项研究为我们理解这一复杂关系提供了宝贵见解,也为构建更安全、更可靠的AI系统指明了方向。