人工智能领域在2025年迎来了前所未有的技术爆发,从Google向公众开放内部AI知识到Sora推出革命性的'角色客串'功能,一系列重大突破正在重塑整个行业格局。本文将深入剖析这些创新技术,揭示它们如何推动AI视频创作、多模态模型和3D生成等领域的边界,为读者呈现一幅完整的AI技术发展蓝图。
Google Skills:AI知识民主化的里程碑
Google推出的'Google Skills'平台堪称AI教育领域的革命性举措,这一平台首次系统性开放了Google内部AI知识,包括DeepMind、Google Cloud、Gemini AI模型开发团队和Google Education的精华内容。这一举措不仅打破了AI知识壁垒,更为全球学习者提供了零门槛的学习体验。
Google Skills平台的核心优势在于其独特的实践教学模式。平台提供700多个实操实验室,学员可以在真实的云环境中编写代码并获得实时反馈。这种'边学边做'的模式极大提升了学习效率,使理论知识能够迅速转化为实践能力。更值得关注的是,完成课程后学员可获得官方认证,并与150多家企业建立直接就业通道,这为AI人才培养提供了完整的闭环。
这一平台的推出,标志着AI教育从理论走向实践的重要转变。它不仅降低了AI技术的学习门槛,更为行业培养了大量具备实战能力的人才,有望缓解当前AI领域人才短缺的困境。对于发展中国家而言,Google Skills平台更是弥合AI技能鸿沟的重要工具,有助于实现AI技术的全球普及。
LiblibAI:1.3亿美元融资背后的多模态野心
LiblibAI完成1.3亿美元B轮融资,创下国内AI应用领域最大单笔融资记录,这一事件背后反映了市场对多模态AI技术的高度认可。作为国内最大的AI应用平台,LiblibAI凭借其多模态模型和创作社区的领先地位,迅速成长为AI应用领域的领军企业。
LiblibAI的核心竞争力在于其全面的多模态能力整合。平台不仅提供图像生成功能,还涵盖了视频创作、3D建模和LoRA训练等多种能力,构建了完整的AI工作流程。这种'一站式'服务极大提升了创作者的效率,降低了技术门槛,使更多非专业人士能够利用AI技术进行创作。
融资完成后,LiblibAI计划加速全球化布局,构建全球创作者共创的多模态内容生态。这一战略表明,LiblibAI不再满足于国内市场,而是瞄准了全球AI应用领域的主导地位。随着全球化进程的推进,LiblibAI有望成为连接东西方AI创作社区的重要桥梁,促进全球AI技术的交流与融合。
Sora路线图更新:角色客串功能开启AI视频创作新纪元
OpenAI的Sora在2025年迎来了路线图的重大更新,其中'角色客串'功能的推出堪称AI视频生成领域的革命性突破。这一功能允许宠物和毛绒玩具等非传统角色参与视频创作,极大地拓展了AI视频创作的边界。
'角色客串'功能的核心在于其先进的角色识别与追踪技术。Sora能够准确识别并锁定特定角色,即使在复杂场景中也能保持角色的连贯性和一致性。这一技术突破解决了AI视频生成中长期存在的角色变形、失真等问题,使生成的视频更加自然流畅。
除了角色客串功能,Sora还宣布即将推出Android版本,这将进一步拓宽其用户基础。同时,社交体验的强化也是本次更新的重点,新增的私人频道与社区联动功能,使用户能够更方便地分享作品、交流经验,形成活跃的创作社区。
Sora的这些更新,标志着AI视频生成技术从'可用'向'精工'的关键跃迁。随着技术的不断成熟,AI视频生成有望从专业领域走向大众市场,成为内容创作的主流工具之一。
昆仑万维SkyReels:AI视频创作的平民化革命
昆仑万维的SkyReels AI视频产品即将推出全新版本,预计在11月初正式上线。作为昆仑万维'All in AGI与AIGC'战略的重要组成部分,SkyReels致力于推动AI视频创作的平民化,实现专业视频创作的高效与普及。
SkyReels的技术亮点在于其强大的模型能力。SkyReels-V1模型实现了33种微表情与400余种动作姿态的精准驱动,达到开源领域SOTA水平。而SkyReels-A3音频驱动模型则支持任意时长的全模态音频驱动数字人创作,极大提升了创作的灵活性和表现力。
SkyReels的推出,反映了昆仑万维在AI视频领域的战略布局。通过降低技术门槛,SkyReels使更多创作者能够利用AI技术进行专业级视频创作,这不仅提升了创作效率,也为视频内容带来了新的可能性。随着版本的不断迭代,SkyReels有望成为AI视频创作领域的重要工具,推动整个行业的发展。
阿里'C计划':夸克对话助手抢占C端AI入口
阿里巴巴推出的'C计划'首款产品——夸克对话助手,标志着阿里在消费者应用生态上的重要布局。夸克对话助手采用Qwen最新闭源模型,集成问答、搜索、拍照搜题等多种功能,实现了搜索与对话体验的深度融合。
夸克对话助手的核心优势在于其独特的搜索与对话融合体验。凭借拍照搜题和信息查找的优势,夸克能够为用户提供更加精准、高效的服务。这种'搜索+对话'的双模态交互模式,不仅提升了用户体验,也为AI应用开辟了新的可能性。
阿里集团将'C计划'资源优先级提升至最高,目标抢占C端AI入口。这一战略表明,阿里看到了AI在消费者应用领域的巨大潜力,希望通过夸克对话助手构建起完整的AI应用生态。随着'C计划'的深入推进,阿里有望在C端AI市场占据重要地位,与其他科技巨头形成竞争格局。
豆包Seedance1.0pro:AI视频创作的可控性突破
豆包视频生成模型Seedance1.0pro的首尾帧能力上线,标志着AI视频创作在可控性和一致性方面取得重要进展。该模型具备复杂场景主体一致性、大幅运动的物理合理性以及视频节奏智能推理等技术优势,能够提升生成视频的主角跟随效果,实现精准叙事引导。
Seedance1.0pro的技术突破在于其对'叙事主体'的结构化认知。通过增强对核心角色的特征锁定,模型能够在复杂场景中保持角色的连贯性和一致性。在大幅运动场景中,模型能精准捕捉人体运动轨迹,保持动作连贯合理,解决了AI视频生成中长期存在的动作不自然问题。
此外,Seedance1.0pro的深度语义理解能力让视频整体节奏自然流畅,符合物理逻辑。这种对视频内容的深度理解,使生成的视频更具沉浸感和表现力,为AI视频创作带来了新的可能性。随着技术的不断迭代,Seedance1.0pro有望成为AI视频生成领域的重要工具,推动整个行业的发展。
Vidu Q2:从'可用'到'精工'的AI视频生成跃迁
Vidu Q2参考生视频大模型API的全面开放,标志着AI视频生成技术从'可用'迈向'精工'的关键跃迁。该模型在广告、商品展示等领域展现出独特价值,能够精准还原产品细节并注入情感表现力,提升品牌好感与用户转化。
Vidu Q2的技术亮点在于其在视频真实感上的突破。通过细微表情生成技术,Vidu Q2为数字角色注入真实情感,使生成的视频更加自然生动。新增的视频延长功能支持高达5分钟视频生成,并新增音效选择,为企业客户提供了更多可能。
此外,Vidu Q2还提供节日特效模板,如万圣节模板合集,让用户轻松制作富有创意的动态视频。这些功能不仅提升了用户体验,也为企业客户提供了更多创意可能。随着API的全面开放,Vidu Q2有望成为AI视频生成领域的重要工具,推动整个行业的发展。
Hailuo2.3:超越Veo的新一代AI视频模型
MiniMax推出的Hailuo2.3被认为是AI视频生成领域的一次重大飞跃,作为旗舰视频生成模型的最新版本,Hailuo2.3在真实感、精准度与风格多样性方面实现了显著突破。
Hailuo2.3的技术优势主要体现在三个方面:首先,在动作捕捉和面部表情方面表现出更高的保真度,能够精准捕捉细微的表情变化和动作细节;其次,新版本强化了超逼真角色动画与微表情捕捉能力,使生成的角色更加生动自然;最后,提升了运动稳定性与物理一致性,消除了闪烁与动作不连贯问题。
这些技术突破使Hailuo2.3在AI视频生成领域树立了新的标杆,被认为是超越Veo的新一代AI视频模型。随着技术的不断迭代,Hailuo2.3有望成为AI视频生成领域的重要工具,推动整个行业的发展。
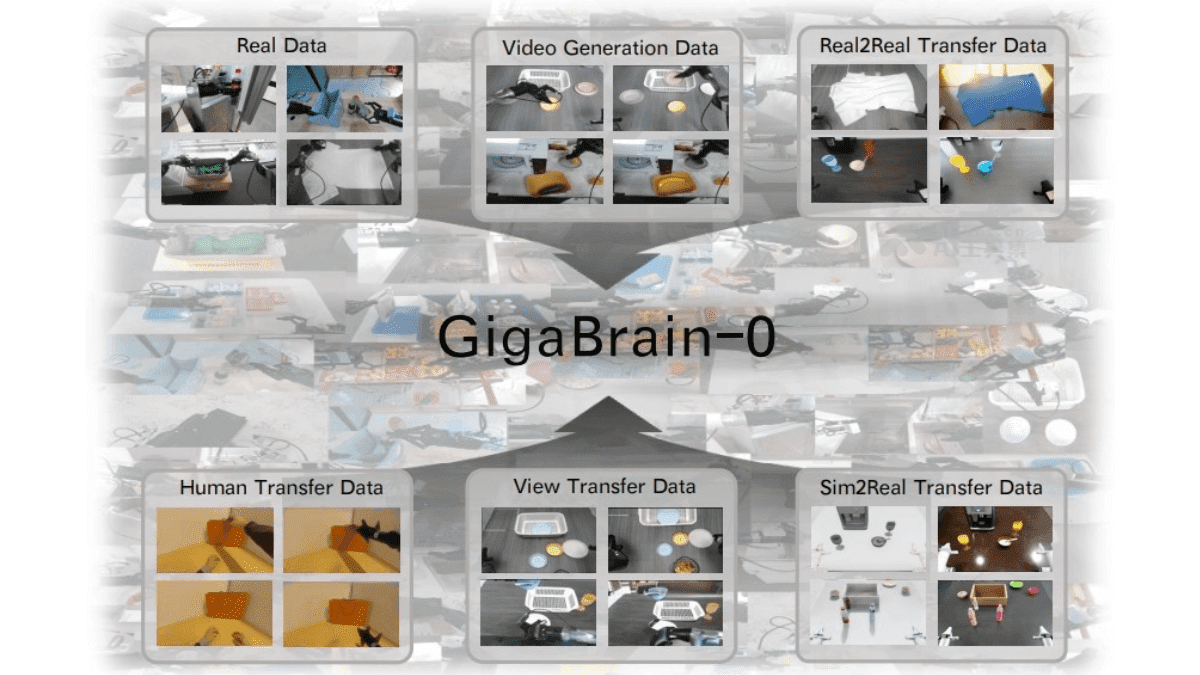
字节跳动Seed3D1.0:从图像到3D模型的革命性突破
字节跳动Seed团队推出的Seed3D1.0是一款创新性的3D生成大模型,能够从单张图像端到端地生成高质量仿真级3D模型,包括精细几何、真实纹理和PBR材质。该模型在多项评估中展现出显著优势,尤其在几何生成和纹理贴图生成方面表现优异。
Seed3D1.0的技术突破在于其独特的生成方法。该模型采用基于Diffusion Transformer架构,实现从单张图像到仿真级3D模型的快速生成。在几何生成方面,Seed3D1.0能够精确构建结构细节并保证物理完整性;在纹理贴图生成方面,该模型能够生成高度逼真的纹理,使3D模型更加真实自然。
此外,Seed3D1.0还支持构建完整的3D场景,并可无缝导入Isaac Sim等仿真引擎,为机器人训练提供多样化操作场景。这一功能为具身智能发展提供了强大的世界模拟器支持,有望推动AI在机器人领域的应用。随着技术的不断迭代,Seed3D1.0有望成为3D生成领域的重要工具,推动整个行业的发展。
AI技术趋势:从单一模态到多模态融合
纵观2025年的AI技术发展,我们可以清晰地看到从单一模态到多模态融合的趋势。无论是Google Skills的知识开放、LiblibAI的多模态整合,还是Sora的角色客串、Seed3D1.0的3D生成,都体现了AI技术在多模态融合方面的突破。
多模态融合的核心在于不同模态之间的协同与互补。文本、图像、视频、3D模型等不同模态的信息相互补充,形成更加完整、丰富的表达。这种融合不仅提升了AI技术的表现力,也为应用场景的拓展提供了可能。
未来,随着多模态技术的不断发展,我们可以预见AI将在更多领域发挥重要作用。从内容创作到产品设计,从教育培训到医疗健康,多模态AI技术将深刻改变人们的生活和工作方式。
AI技术发展的挑战与机遇
尽管AI技术在2025年取得了显著进展,但仍然面临诸多挑战。首先,技术门槛虽然有所降低,但对于普通用户而言,AI技术的理解和应用仍然存在困难;其次,AI生成内容的版权和伦理问题日益突出,需要建立相应的规范和标准;最后,AI技术的快速发展也带来了就业结构的变革,需要相应的教育和培训体系来应对。
然而,挑战与机遇并存。AI技术的民主化将激发更多创新和创造力,推动各行各业的数字化转型;多模态融合将带来更加丰富和自然的人机交互体验;AI技术的普及将为经济发展注入新动力。
结语:AI技术的未来展望
2025年的AI技术发展呈现出多元化、普及化和专业化的趋势。从Google Skills的知识开放到Sora的角色客串,从LiblibAI的多模态整合到Seed3D1.0的3D生成,AI技术正在不断突破边界,拓展应用场景。
未来,随着技术的不断进步和应用场景的拓展,AI将在更多领域发挥重要作用。从内容创作到产品设计,从教育培训到医疗健康,AI技术将深刻改变人们的生活和工作方式。同时,AI技术的民主化也将激发更多创新和创造力,推动各行各业的数字化转型。
面对AI技术的快速发展,我们需要保持开放和包容的态度,积极拥抱变革,同时也要关注技术带来的伦理和社会问题,确保AI技术的发展能够造福人类。只有这样,我们才能真正实现AI技术的价值,构建一个更加智能、美好的未来。