深入剖析Qwen2模型架构与技术原理
Qwen2模型作为当前炙手可热的大语言模型之一,其背后蕴含的技术细节和设计理念吸引了众多研究者和开发者的目光。本文将以白皮书的形式,深入解读Qwen2模型的架构,剖析其核心组件的功能与实现,并结合PyTorch和Hugging Face Transformers库的实现代码,阐述其技术原理。
Qwen2模型总览
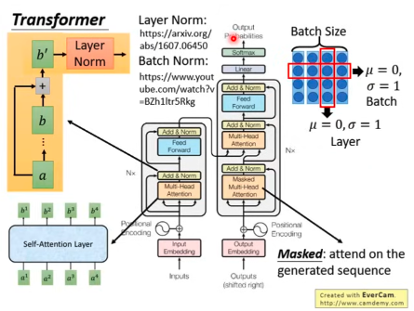
Qwen2模型架构由多个关键模块组成,包括文本编码器、解码器层、注意力机制、MLP模块和输出层。整体流程是,首先通过Tokenizer将文本输入编码为Input_ids,然后输入到Embedding层进行向量化表示。Embedding层的输出经过Hidden_states,传递给多个Layers层进行深度特征提取。每个Layer层都采用RMSNorm进行正则化处理,以提升模型的稳定性和泛化能力。Layers的输出最终进入Decoder Layer进行解码。
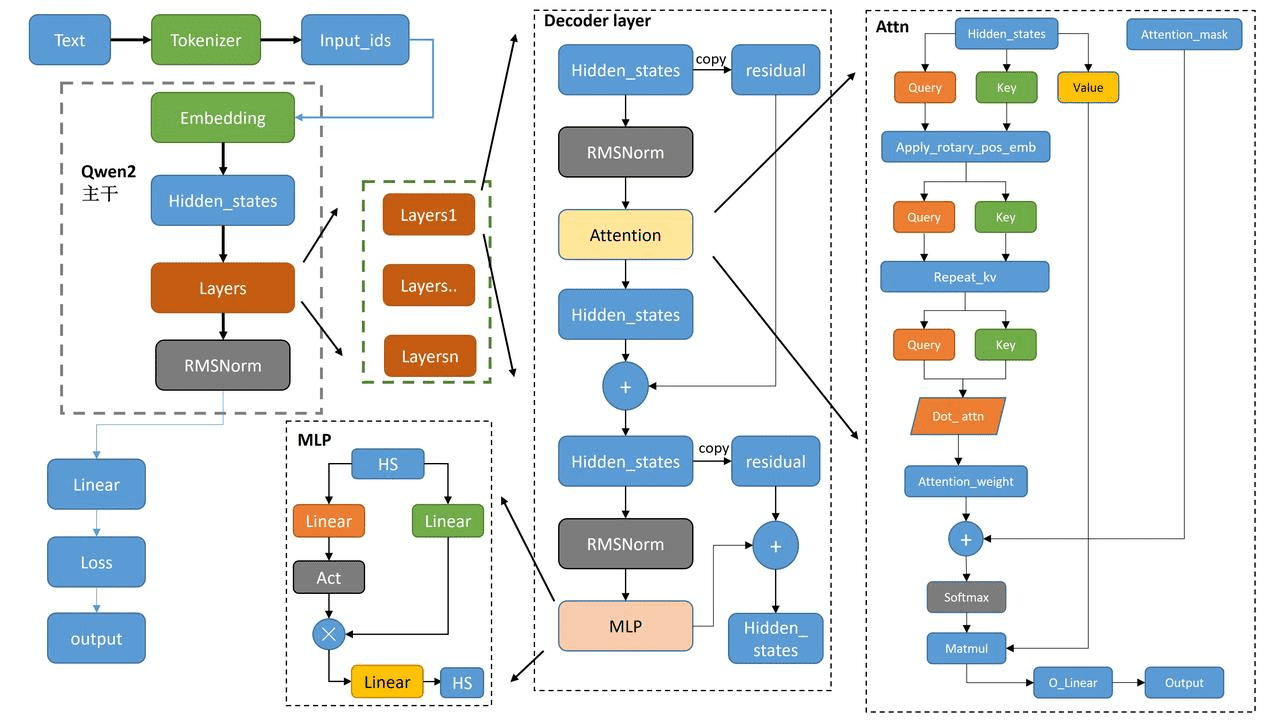
解码器层(Decoder Layer)
解码器层是Qwen2模型的核心组成部分,其主要功能是将编码器的输出进行解码,生成最终的文本输出。解码器层接收来自编码器的Hidden_states,首先经过RMSNorm正则化处理,然后传递给Attention模块。Attention模块是解码器层的关键,负责计算输入序列中不同位置之间的关联性,从而更好地理解文本的含义。
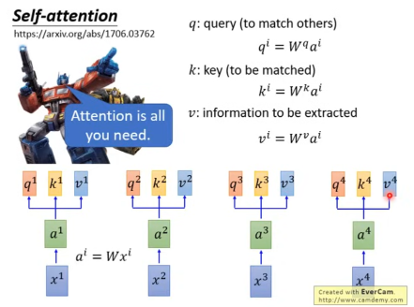
在Attention模块内部,输入被分为Query、Key和Value三个部分,用于注意力机制的计算。经过Attention后的输出再次经过RMSNorm处理,并通过MLP(多层感知器)进行进一步的特征提取。为了保证信息流动不会丢失,解码器层还采用了残差连接(Residual)机制,将每一层的输入与输出相加。
注意力机制(Attention Mechanism)
注意力机制是Qwen2模型能够有效处理长文本序列的关键。其核心思想是让模型在生成每个输出时,都能够关注到输入序列中与该输出最相关的部分。在Qwen2模型中,注意力机制的具体实现如下:
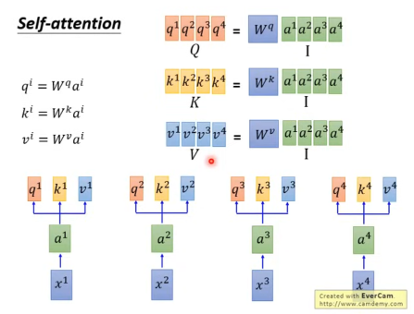
- Query、Key和Value的生成:Hidden_states分别经过线性变换,生成Query、Key和Value。
- 位置编码:为了让模型能够感知到输入序列中不同位置之间的关系,Qwen2模型采用了Rotary positional embedding进行位置编码。
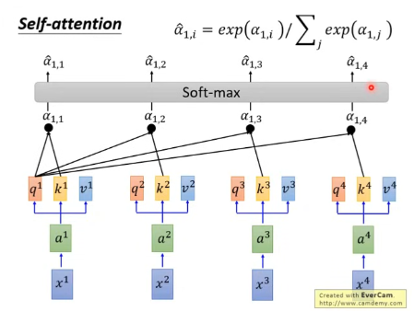
- 注意力权重计算:编码后的Query、Key和Value经过注意力计算,生成Attention_weight。具体的计算方式是将Query和Key进行点积,然后除以一个缩放因子,以避免梯度消失问题。
- Softmax归一化:Attention_weight通过Softmax归一化,得到每个位置的注意力权重。
- 加权求和:将归一化后的Attention_weight与Value相乘,得到最终的输出O_Linear。
MLP模块
MLP(多层感知器)模块是Qwen2模型中用于特征提取的重要组成部分。它由两层线性层(Linear)和一个激活函数(Act)组成。MLP模块的作用是将Attention模块的输出进行非线性变换,从而提取更高级别的特征。
输出层
Qwen2模型的输出层负责将解码器层的输出转换为最终的文本输出。具体来说,输出层通过一个线性层计算Loss,并生成最终的Output。Loss函数用于衡量模型的预测结果与真实结果之间的差距,模型通过不断优化Loss函数,来提高预测的准确性。
PyTorch实现代码解读
以下结合PyTorch和Hugging Face Transformers库的代码,进一步解读Qwen2模型的实现细节。
导入部分
首先,导入相关的PyTorch模块和Hugging Face Transformers库。
import torch
import torch.nn as nn
import torch.nn.functional as F
from transformers import PreTrainedModel, PretrainedConfig核心组件类
Qwen2RMSNorm:Qwen2版本的RMS正则化层。
class Qwen2RMSNorm(nn.Module): def __init__(self, hidden_size, eps=1e-6): super().__init__() self.weight = nn.Parameter(torch.ones(hidden_size)) self.eps = eps def forward(self, hidden_states): input_dtype = hidden_states.dtype variance = hidden_states.float().pow(2).mean(-1, keepdim=True) hidden_states = hidden_states * torch.rsqrt(variance + self.eps) return self.weight * hidden_states.to(input_dtype)Qwen2RotaryEmbedding:处理旋转位置嵌入的类。
class Qwen2RotaryEmbedding(nn.Module): def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None): super().__init__() self.dim = dim self.max_position_embeddings = max_position_embeddings self.base = base inv_freq = 1.0 / (self.base ** (torch.arange(0, dim, 2).float() / dim)) self.register_buffer("inv_freq", inv_freq) self._set_cos_sin_cache(max_position_embeddings, device=device, dtype=torch.get_default_dtype()) def _set_cos_sin_cache(self, max_position_embeddings, device, dtype): self.max_position_embeddings = max_position_embeddings t = torch.arange(self.max_position_embeddings, device=device, dtype=self.inv_freq.dtype) freqs = torch.outer(t, self.inv_freq) emb = torch.cat((freqs, freqs), dim=-1) self.register_buffer("cos_cached", emb.cos().to(dtype), persistent=False) self.register_buffer("sin_cached", emb.sin().to(dtype), persistent=False) def forward(self, x, seq_len=None): if seq_len > self.max_position_embeddings: self._set_cos_sin_cache(seq_len, device=x.device, dtype=x.dtype) return ( self.cos_cached[:seq_len].to(dtype=x.dtype), self.sin_cached[:seq_len].to(dtype=x.dtype), )Qwen2MLP:多层感知器(MLP)。
class Qwen2MLP(nn.Module): def __init__(self, config): super().__init__() self.gate_proj = nn.Linear(config.hidden_size, config.intermediate_size, bias=False) self.down_proj = nn.Linear(config.intermediate_size, config.hidden_size, bias=False) self.up_proj = nn.Linear(config.hidden_size, config.intermediate_size, bias=False) self.act_fn = ACT2FN[config.hidden_act] def forward(self, x): gate = self.gate_proj(x) up = self.up_proj(x) intermediate = self.act_fn(gate) * up x = self.down_proj(intermediate) return xQwen2Attention:注意力机制的实现。
class Qwen2Attention(nn.Module): def __init__(self, config, layer_idx=None): super().__init__() self.config = config self.layer_idx = layer_idx self.hidden_size = config.hidden_size self.num_heads = config.num_attention_heads self.head_dim = self.hidden_size // self.num_heads self.attention_dropout = config.attention_dropout self.max_position_embeddings = config.max_position_embeddings self.rope_theta = config.rope_theta if (self.head_dim * self.num_heads) != self.hidden_size: raise ValueError( f"hidden_size must be divisible by num_heads (got `hidden_size`: {self.hidden_size} and `num_heads`: {self.num_heads})." ) self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=config.attention_bias) self.k_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=config.attention_bias) self.v_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=config.attention_bias) self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=config.attention_bias) self.rotary_emb = Qwen2RotaryEmbedding( self.head_dim, max_position_embeddings=self.max_position_embeddings, base=self.rope_theta ) self.dropout = nn.Dropout(config.attention_dropout) def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int): return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous() def forward( self, hidden_states: torch.Tensor, attention_mask: Optional[torch.Tensor] = None, position_ids: Optional[torch.LongTensor] = None, past_key_value: Optional[Tuple[torch.Tensor]] = None, output_attentions: bool = False, use_cache: bool = False, ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]: bsz, seq_len, _ = hidden_states.size() if self.config.pretraining_tp > 1: key_value_slicing = (slice(None, self.num_heads // self.config.pretraining_tp),) + (slice(None),) query_states = self.q_proj(hidden_states).split(self.head_dim, dim=2)[key_value_slicing].contiguous() key_states = self.k_proj(hidden_states).split(self.head_dim, dim=2)[key_value_slicing].contiguous() value_states = self.v_proj(hidden_states).split(self.head_dim, dim=2)[key_value_slicing].contiguous() else: query_states = self.q_proj(hidden_states).view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2) key_states = self.k_proj(hidden_states).view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2) value_states = self.v_proj(hidden_states).view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2) kv_seq_len = key_states.shape[-2] if past_key_value is not None: kv_seq_len += past_key_value[0].shape[-2] cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len) query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids) # [bsz, nh, t, hd] if past_key_value is not None: # reuse k, v, self_attention key_states = torch.cat([past_key_value[0], key_states], dim=2) value_states = torch.cat([past_key_value[1], value_states], dim=2) past_key_value = (key_states, value_states) if use_cache else None attn_weights = torch.matmul(query_states, key_states.transpose(-1, -2)) / math.sqrt(self.head_dim) if attention_mask is not None: attn_weights = attn_weights + attention_mask # upcast to fp32 if the weights are in fp16. Please see https://github.com/huggingface/transformers/pull/17437 attn_weights = torch.nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype) attn_weights = self.dropout(attn_weights) attn_output = torch.matmul(attn_weights, value_states) attn_output = attn_output.transpose(1, 2).contiguous() attn_output = attn_output.reshape(bsz, seq_len, self.hidden_size) if self.config.pretraining_tp > 1: attn_output = attn_output.split(self.hidden_size // self.config.pretraining_tp, dim=2).contiguous() attn_output = self.o_proj(attn_output) if not output_attentions: attn_weights = None return attn_output, attn_weights, past_key_valueQwen2DecoderLayer:Qwen2解码器层。
class Qwen2DecoderLayer(nn.Module): def __init__(self, config, layer_idx): super().__init__() self.hidden_size = config.hidden_size self.self_attn = Qwen2Attention(config, layer_idx) self.mlp = Qwen2MLP(config) self.input_layernorm = Qwen2RMSNorm(config.hidden_size, eps=config.rms_norm_eps) self.post_attention_layernorm = Qwen2RMSNorm(config.hidden_size, eps=config.rms_norm_eps) def forward( self, hidden_states: torch.Tensor, attention_mask: Optional[torch.Tensor] = None, position_ids: Optional[torch.LongTensor] = None, past_key_value: Optional[Tuple[torch.Tensor]] = None, output_attentions: bool = False, use_cache: bool = False, ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]: residual = hidden_states hidden_states = self.input_layernorm(hidden_states) # Self Attention hidden_states, attn_weights, present_key_value = self.self_attn( hidden_states=hidden_states, attention_mask=attention_mask, position_ids=position_ids, past_key_value=past_key_value, output_attentions=output_attentions, use_cache=use_cache, ) hidden_states = residual + hidden_states residual = hidden_states hidden_states = self.post_attention_layernorm(hidden_states) hidden_states = self.mlp(hidden_states) hidden_states = residual + hidden_states outputs = (hidden_states,) if output_attentions: outputs += (attn_weights,) if use_cache: outputs += (present_key_value,) return outputs # (hidden_states, attention, present_key_value)
Qwen2Model类
Qwen2Model是基础Qwen2模型,由多个解码器层组成。
class Qwen2Model(Qwen2PreTrainedModel):
def __init__(self, config: Qwen2Config):
super().__init__(config)
self.padding_idx = config.pad_token_id
self.vocab_size = config.vocab_size
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
self.layers = nn.ModuleList(
[Qwen2DecoderLayer(config, layer_idx) for layer_idx in range(config.num_hidden_layers)]
)
self._attn_implementation = config._attn_implementation
self.norm = Qwen2RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
self.gradient_checkpointing = False
self.post_init()Qwen2Model的__init__函数主要完成以下几个步骤:
- 调用父类的构造函数并传递配置。
- 获取填充token的索引。
- 设置词汇表大小。
- 初始化嵌入层,输入为词汇表大小,输出为隐藏层大小,忽略填充token。
- 初始化解码器层列表,包含num_hidden_layers个Qwen2DecoderLayer。
- 设置注意力机制的实现方式。
- 初始化RMS正则化层,用于正则化隐藏状态。
- 是否启用梯度检查点,以节省内存,默认关闭。
- 调用后续的初始化过程,通常是权重初始化。
总结
本文深入剖析了Qwen2模型的架构和技术原理,并结合PyTorch和Hugging Face Transformers库的实现代码,阐述了其核心组件的功能与实现。Qwen2模型作为一种先进的大语言模型,其技术细节和设计理念对于研究者和开发者都具有重要的参考价值。通过深入理解Qwen2模型的架构和原理,可以更好地应用和优化该模型,从而在自然语言处理领域取得更大的突破。