Qwen2,阿里巴巴旗下的通义千问系列大语言模型的最新力作,已正式发布。这份技术报告详细解读了Qwen2的技术细节,揭示了其在语言理解、生成、多语言支持、编码、数学和推理等方面的卓越性能。本文将深入探讨Qwen2的技术特点、训练方法以及评估结果,带您全面了解这款备受瞩目的大语言模型。
Qwen2系列:参数规模与模型架构
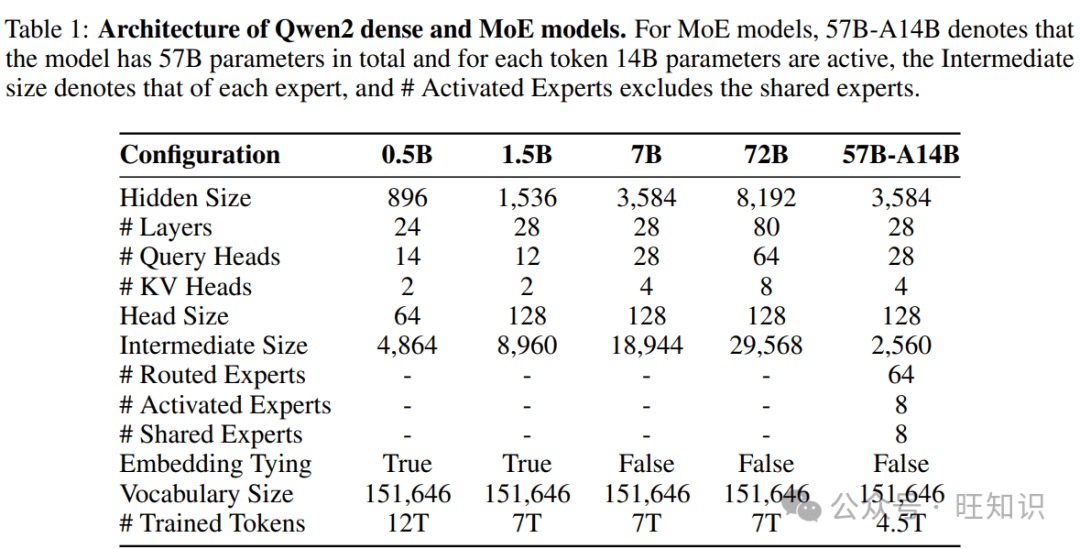
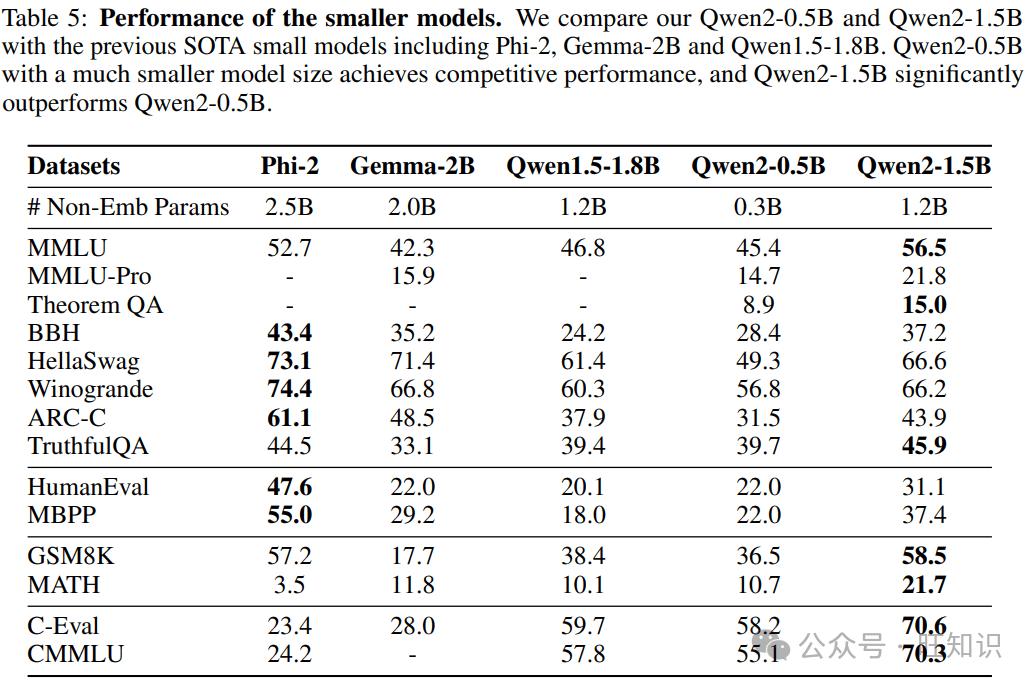
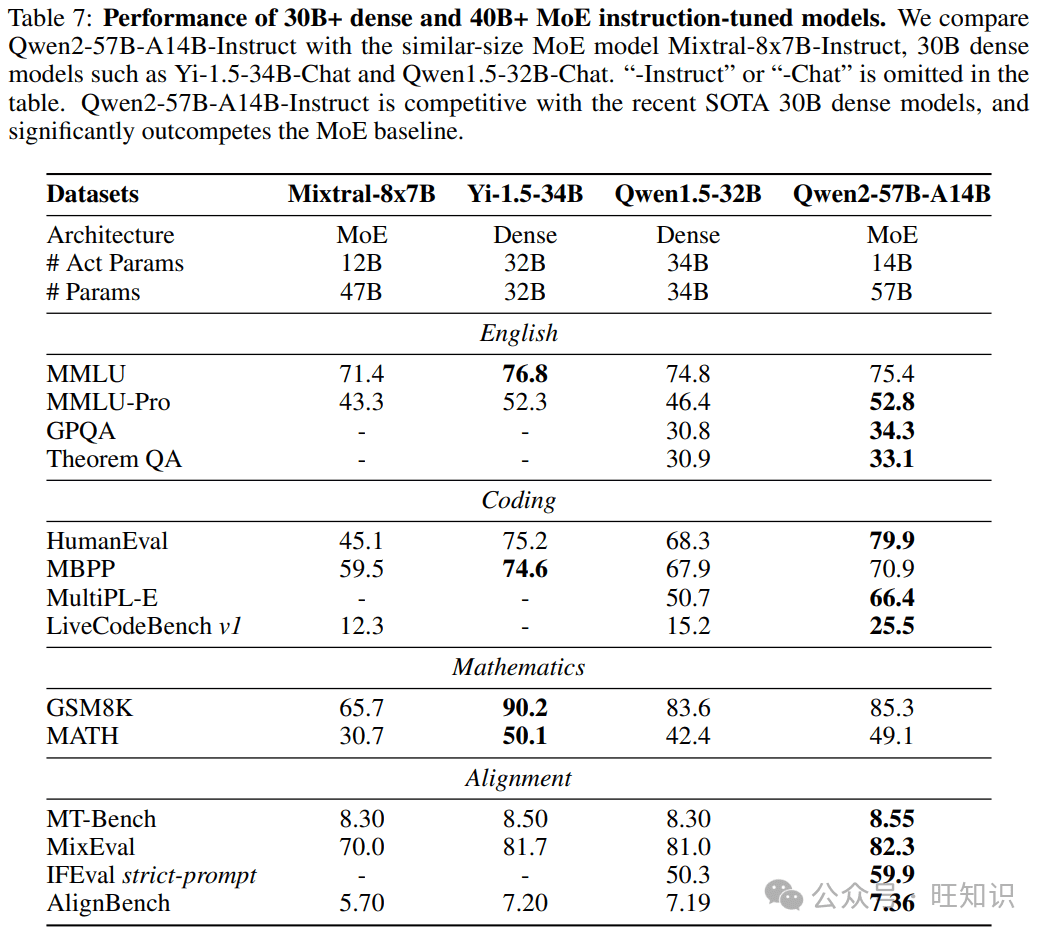
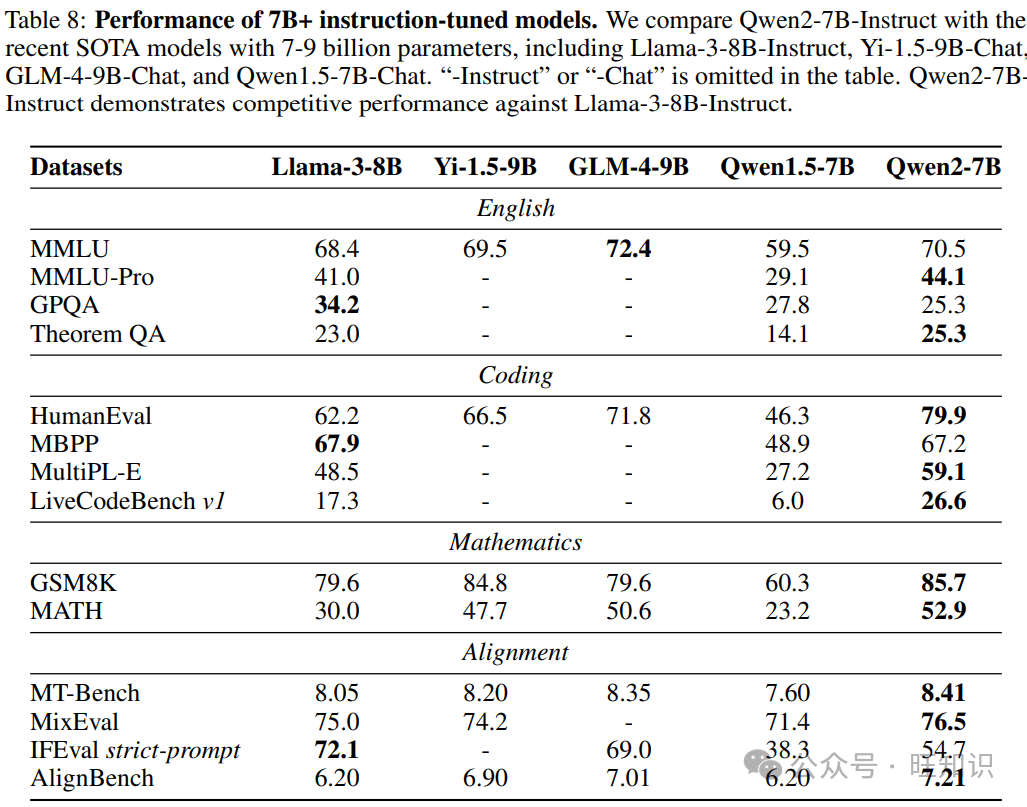
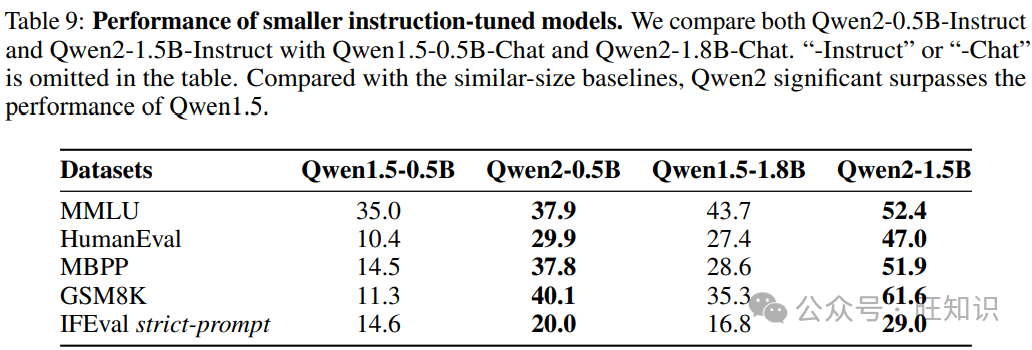
Qwen2系列模型涵盖了从0.5亿到720亿参数的不同规模,包括密集模型和混合专家模型(MoE)。这种多样化的模型规模设计,旨在满足不同应用场景的需求。小型模型如Qwen2-0.5B和Qwen2-1.5B,更易于在移动设备上部署,而大型模型则适用于GPU集群,提供强大的计算能力。

在模型架构方面,Qwen2采用了Transformer架构,并在此基础上进行了创新。主要改进包括:
- **分组查询注意力(GQA):**取代了传统的多头注意力(MHA),优化了KV缓存的使用,提高了推理效率。
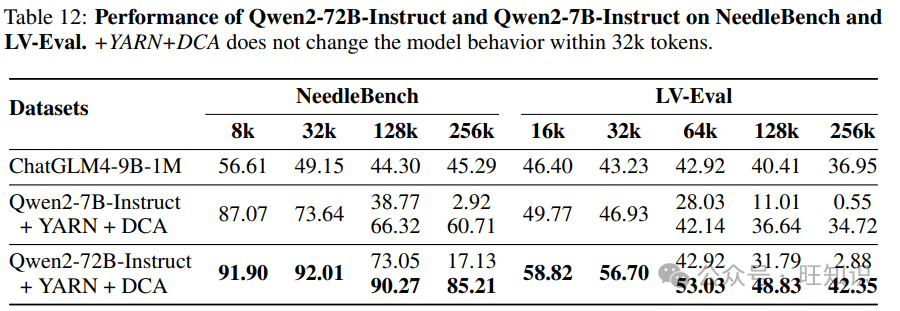
- **带有YARN的双块注意力(DCA):**扩展了上下文窗口,使模型能够处理更长的序列。DCA将长序列分割成多个块,并在块内和块间捕获token之间的关系。
预训练:数据质量与上下文长度
Qwen2的预训练使用了超过7万亿token的高质量数据集,涵盖了广泛的领域和语言。与之前的Qwen版本相比,Qwen2的数据集在以下几个方面进行了改进:
- **质量提升:**采用了更严格的过滤算法,包括启发式方法和基于模型的方法,以去除低质量数据。同时,使用Qwen模型生成高质量的预训练数据。
- **数据扩展:**增加了代码、数学和多语言数据的比例,增强了模型在这些领域的能力。支持约30种语言,包括英语、中文、西班牙语、法语、德语、阿拉伯语、俄语、韩语、日语、泰语和越南语。
- **分布改进:**通过实验优化了数据的混合比例,确保模型学习到更符合人类学习模式的分布。
为了进一步提升Qwen2的长上下文处理能力,预训练的最后阶段将上下文长度从4,096个token增加到32,768个token。同时,调整了RoPE的基础频率,并采用了YARN机制和双块注意力机制。
后训练:对齐与安全
后训练是Qwen2的重要组成部分,旨在提升模型在编码、数学、逻辑推理、指令遵循和多语言理解等方面的能力。同时,确保模型的生成与人类价值观对齐,使其有帮助、诚实且无害。
后训练主要包括两个阶段:
- **监督微调(SFT):**使用包含超过50万个示例的指令数据集进行微调,涵盖指令遵循、编码、数学、逻辑推理、角色扮演、多语言和安全等技能。
- **从人类反馈中学习强化学习(RLHF):**通过直接偏好优化(DPO)使模型与人类偏好对齐。
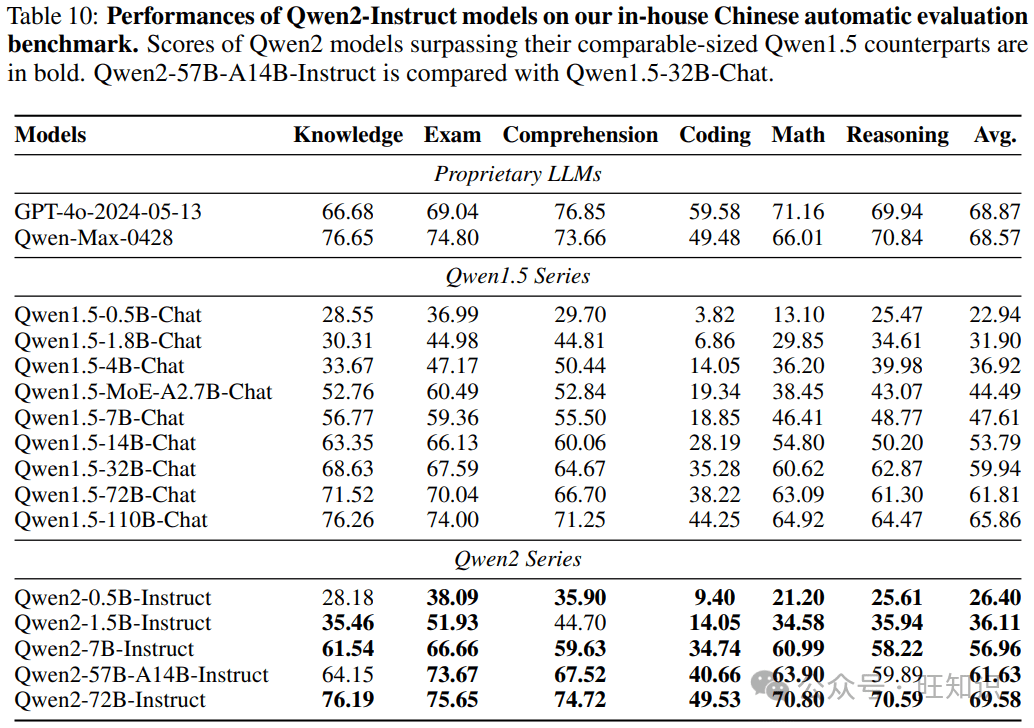
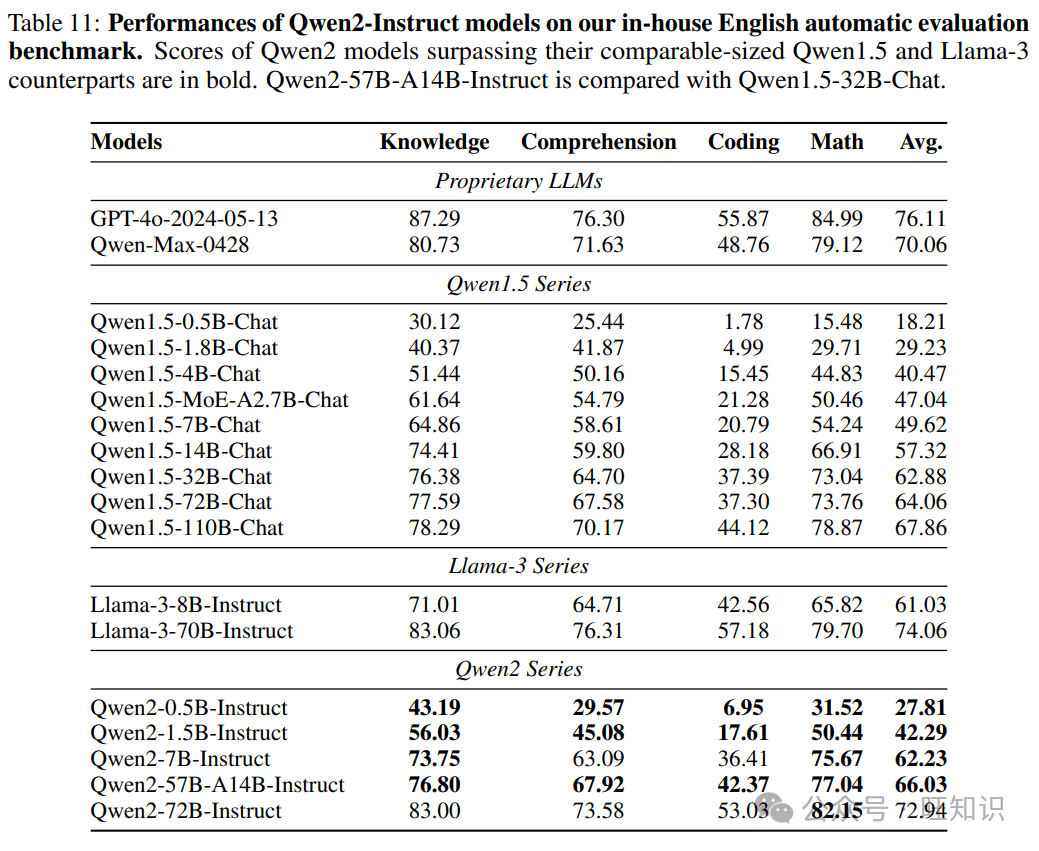
评估结果:性能超越与多语言能力
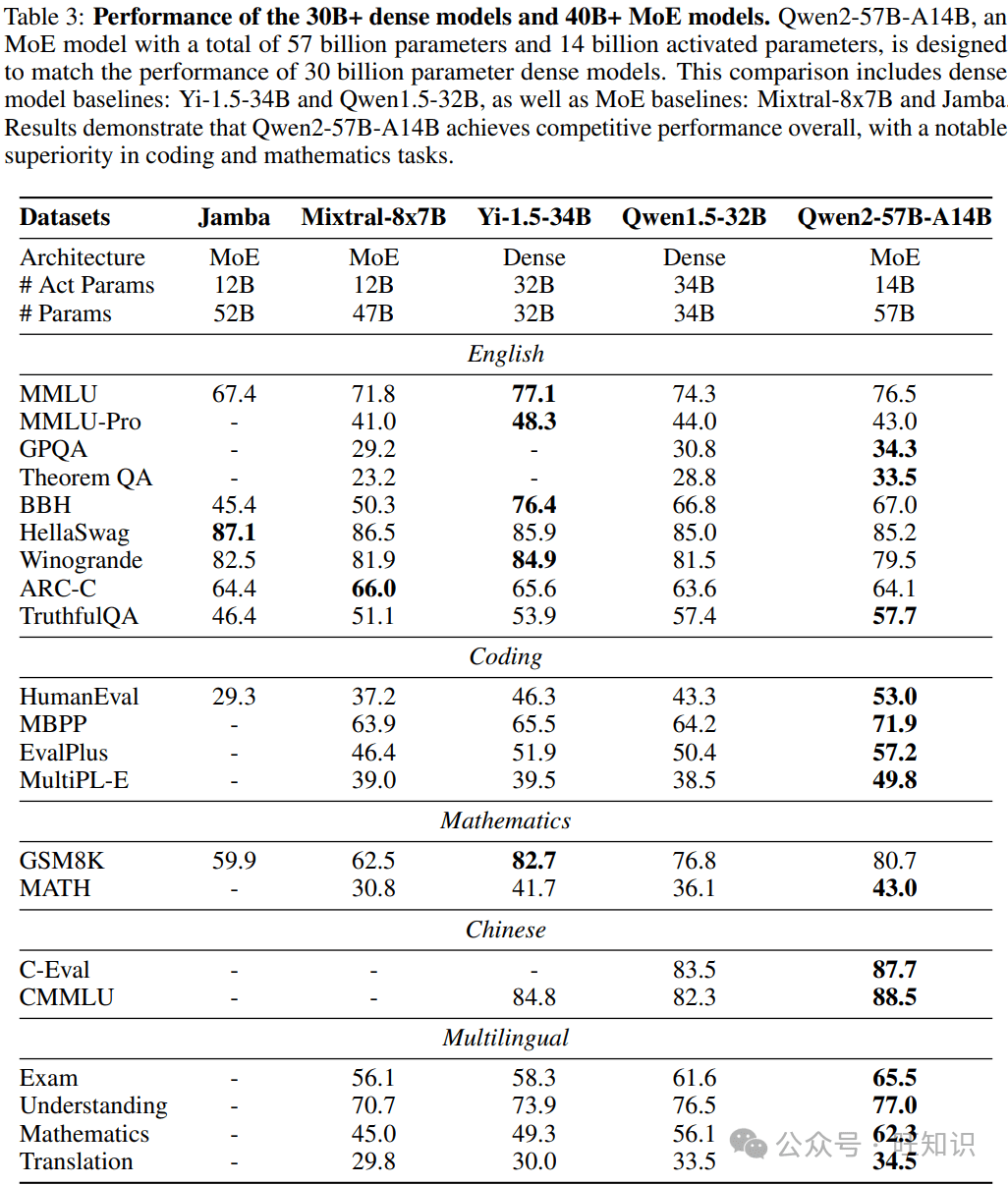
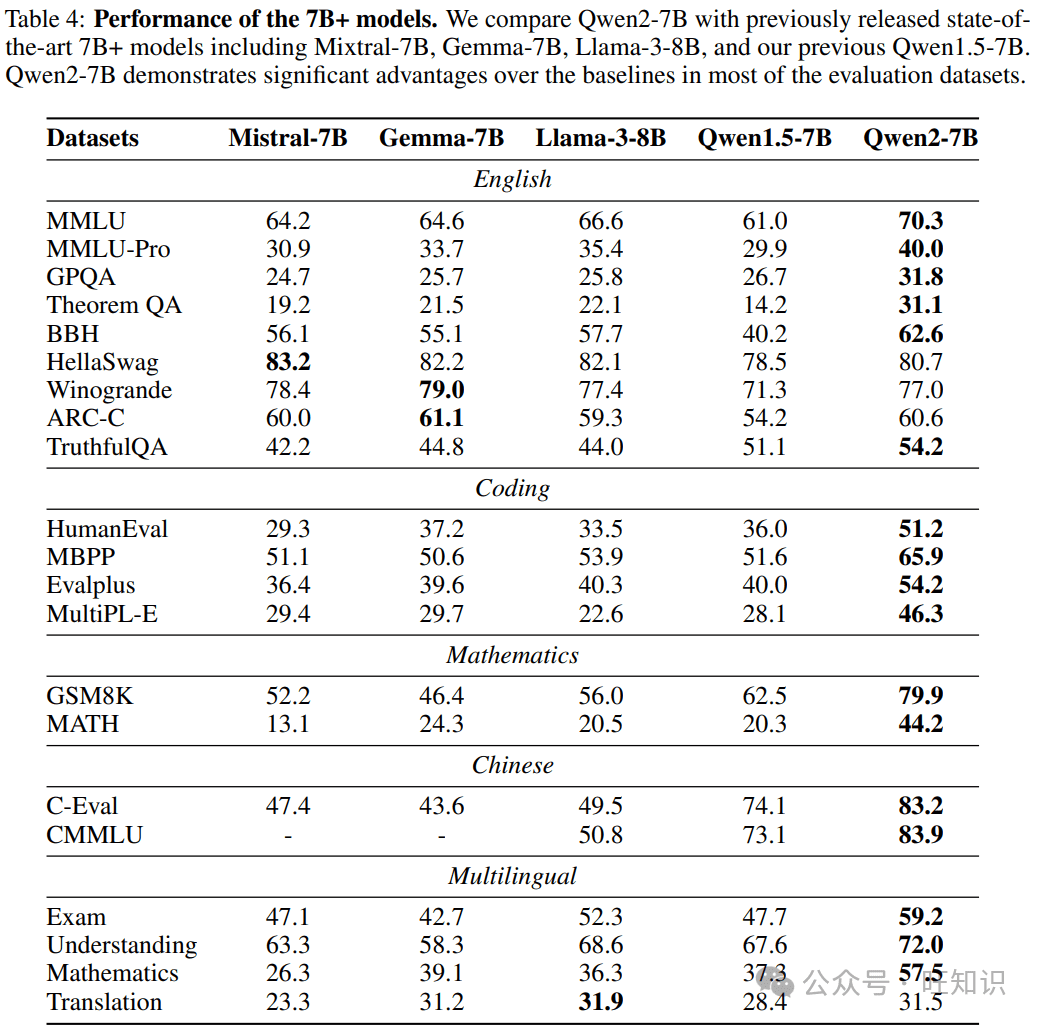
Qwen2在多个基准测试中展现出卓越的性能,超越了之前的开放权重模型,甚至可以与一些专有模型相媲美。
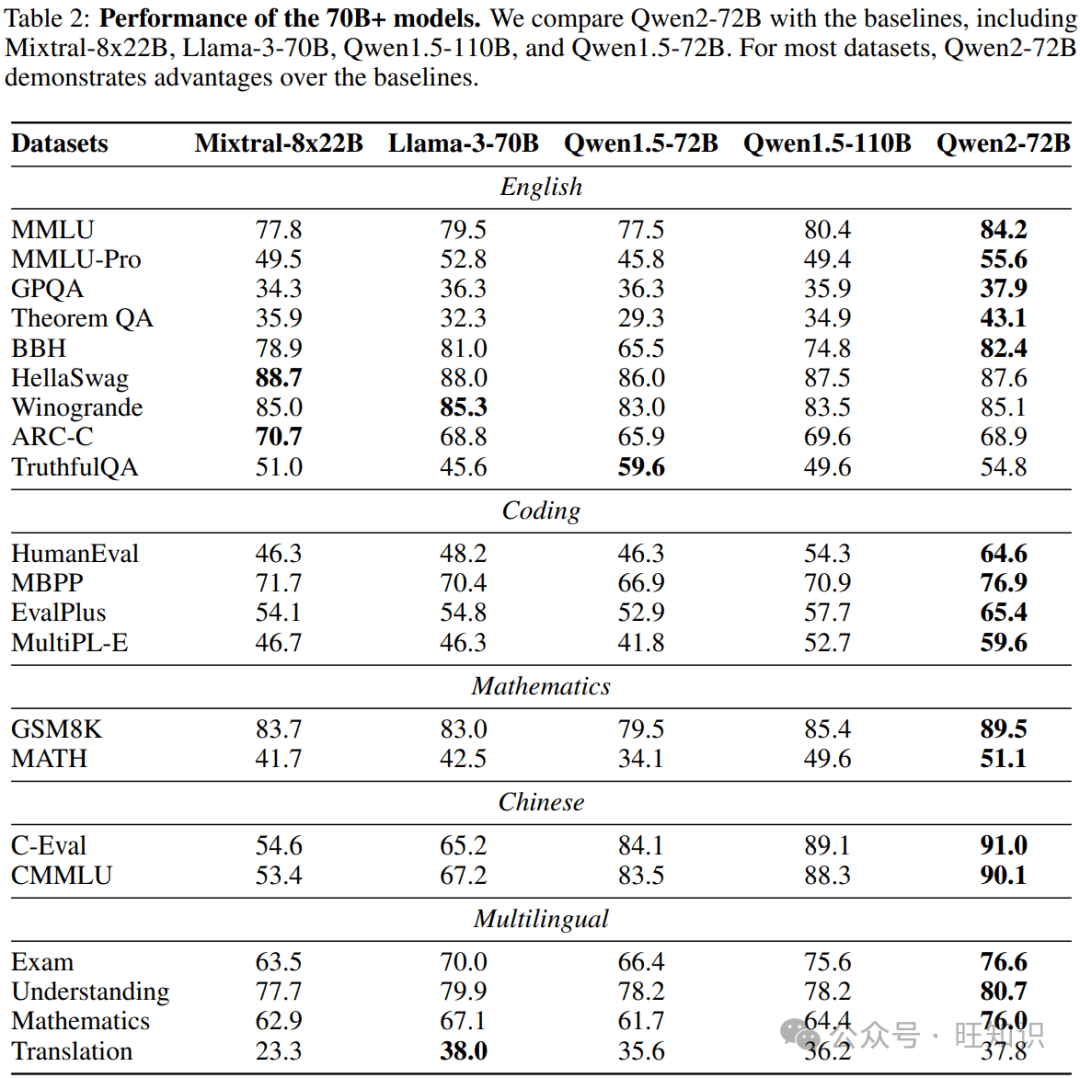
- **基础语言模型:**Qwen2-72B在MMLU上得分84.2,在GPQA上得分37.9,在HumanEval上得分64.6,在GSM8K上得分89.5,在BBH上得分82.4。
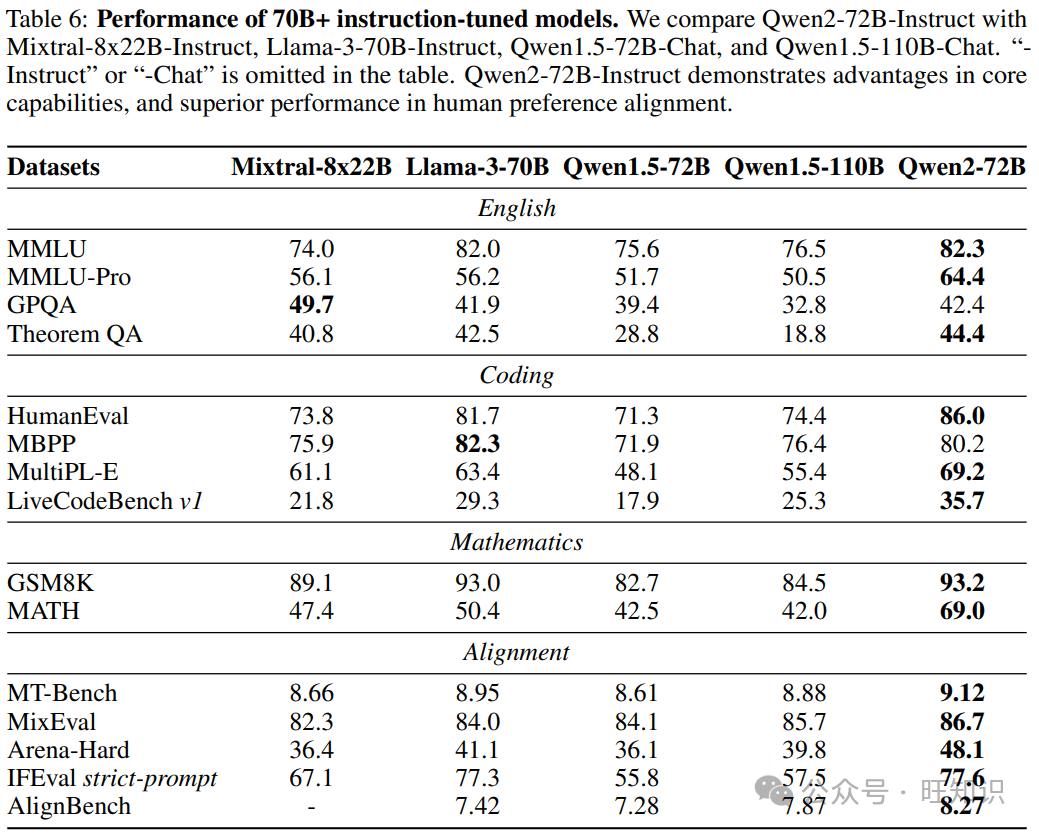
- **指令调优模型:**Qwen2-72B-Instruct在MT-Bench上得分9.1,在Arena-Hard上得分48.1,在LiveCodeBench上得分35.7。
Qwen2还展示了强大的多语言能力,精通约30种语言,涵盖英语、中文、西班牙语、法语、德语、阿拉伯语、俄语、韩语、日语、泰语、越南语等。
Qwen2-72B:性能巅峰
作为Qwen2系列的旗舰模型,Qwen2-72B在各项基准测试中都表现出色,证明了其在理解、推理和生成方面的卓越能力。
- **MMLU:**84.2分,体现了Qwen2-72B在多学科知识理解方面的强大实力。
- **GPQA:**37.9分,表明Qwen2-72B在处理需要专业知识的问题时具有较高的准确性。
- **HumanEval:**64.6分,展示了Qwen2-72B在代码生成方面的能力。
- **GSM8K:**89.5分,突显了Qwen2-72B在解决复杂数学问题方面的能力。
- **BBH:**82.4分,证明了Qwen2-72B在处理复杂推理任务方面的能力。
Qwen2-72B-Instruct:指令遵循的典范
Qwen2-72B-Instruct是经过指令调优的版本,能够更好地理解和执行人类指令。其在MT-Bench、Arena-Hard和LiveCodeBench等基准测试中的优异表现,证明了其在对话、推理和编码等方面的能力。
- **MT-Bench:**9.1分,表明Qwen2-72B-Instruct在多轮对话中具有优秀的表现。
- **Arena-Hard:**48.1分,展示了Qwen2-72B-Instruct在处理复杂和具有挑战性的问题时的能力。
- **LiveCodeBench:**35.7分,突显了Qwen2-72B-Instruct在实际编码场景中的应用潜力。
多语言能力的全面提升
Qwen2的多语言能力是其重要特点之一。通过在预训练阶段增加多语言数据的比例,Qwen2能够更好地理解和生成多种语言的文本。这使得Qwen2在跨语言任务中具有更强的竞争力。
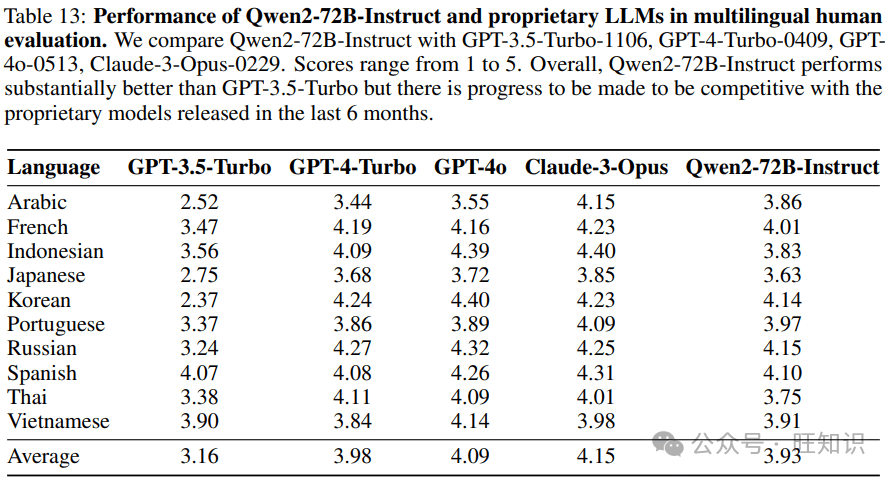
为了验证Qwen2的多语言能力,研究团队进行了全面的人类评估。评估结果表明,Qwen2在多种语言上的表现均优于之前的版本,甚至可以与一些专有模型相媲美。
安全与责任:构建可信赖的AI
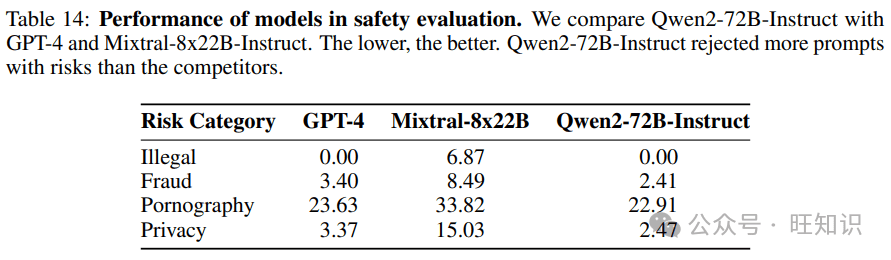
在追求性能提升的同时,Qwen2团队也高度重视安全与责任。他们实施了多语言安全评估,测试了模型在关于非法行为、欺诈、色情内容和隐私等主题方面的安全性能。评估结果表明,Qwen2在安全性方面表现良好,但仍有改进空间。
Qwen2团队致力于构建安全、负责任的大语言模型,以减轻人工智能技术滥用的风险。他们将继续改进模型的安全性能,并积极参与到AI伦理的讨论中。
开放与共享:推动AI生态发展
为了促进社区创新和可访问性,Qwen2模型权重已在Hugging Face和ModelScope上公开提供。同时,GitHub上还提供了包括示例代码在内的补充材料。这些开放资源将有助于研究人员和开发人员更好地利用Qwen2,推动AI技术的进步。
通过开放Qwen2,阿里巴巴希望与社区共同合作,构建更加繁荣的AI生态,共同推动人工智能技术的发展和应用。
结论与展望
Qwen2是阿里巴巴通义千问系列大语言模型的又一重要里程碑。它在模型架构、预训练数据、后训练方法和评估结果等方面都进行了创新和改进。Qwen2的卓越性能和多语言能力,使其在各种应用场景中具有广泛的应用前景。
随着AI技术的不断发展,大语言模型将在更多领域发挥重要作用。Qwen2的发布,将为AI研究和应用提供新的动力,推动人工智能技术的进步。
Qwen2与其他模型的对比
为了更清晰地了解Qwen2的优势,我们将其与一些知名的开源和闭源大语言模型进行了对比。
- **Qwen2 vs. Llama 3:**在某些基准测试中,Qwen2的表现略优于Llama 3,但在另一些测试中则稍逊。总体而言,两者的性能相当接近。
- **Qwen2 vs. GPT-4:**GPT-4在某些任务上的表现仍然领先于Qwen2,尤其是在需要复杂推理和创造力的任务中。然而,Qwen2在某些特定领域,如中文处理方面,具有一定的优势。
- **Qwen2 vs. Mixtral:**Qwen2的MoE模型在某些任务上表现出色,尤其是在需要处理大量数据的任务中。然而,Mixtral在推理速度方面可能更具优势。
Qwen2的应用场景
Qwen2作为一款通用的大语言模型,可以应用于各种场景,包括:
- **自然语言处理:**文本生成、机器翻译、情感分析、问答系统等。
- **代码生成:**自动生成代码、代码补全、代码调试等。
- **教育:**智能辅导、个性化学习、作业批改等。
- **医疗:**辅助诊断、药物研发、健康咨询等。
- **金融:**风险评估、智能客服、投资建议等。
未来的发展方向
Qwen2的发布标志着大语言模型技术的新进展。未来,Qwen2团队将继续努力,在以下几个方向进行改进:
- **提升推理能力:**通过引入更先进的推理机制,提高模型在复杂推理任务中的表现。
- **增强多语言能力:**扩大多语言数据集,提高模型在更多语言上的表现。
- **改进安全性:**加强安全评估,降低模型生成有害内容的风险。
- **优化模型效率:**降低模型的大小和计算复杂度,使其更易于部署在各种设备上。
我们期待Qwen2在未来能够取得更大的突破,为AI技术的发展做出更大的贡献。