
LLaMA-Factory 模型权重合并实战指南:Qwen2-VL-7B-Instruct 微调模型整合
一、前言
在人工智能领域,模型微调和合并是提升模型性能和效率的关键技术。本文将深入探讨如何使用 LLaMA-Factory 工具,将微调后的 Qwen2-VL-7B-Instruct 模型的权重进行合并。通过本文,你将掌握模型合并的关键步骤,理解技术要点,并能够将这些知识应用到你自己的项目中,从而构建更强大的 AI 应用。
Qwen2-VL-7B-Instruct 微调首发:开源模型应用落地-qwen模型小试-调用Qwen2-VL-7B-Instruct-更清晰地看世界-Lora-V100(四)
二、术语介绍
为了更好地理解后续内容,我们首先对几个关键术语进行解释:
2.1. LoRA 微调
LoRA(Low-Rank Adaptation,低秩适应)是一种用于微调大型语言模型(LLM)的参数高效方法。它通过引入低秩矩阵来学习模型的增量更新,从而避免了直接修改原始模型的所有参数。这种方法不仅能有效减少训练参数的数量,还能在保持模型性能的同时,避免引入额外的推理延迟。
2.2. 参数高效微调 (PEFT)
参数高效微调(Parameter-Efficient Fine-Tuning,PEFT)是指仅微调少量(额外)模型参数,同时冻结预训练 LLM 的大部分参数。通过这种方式,可以大大降低计算和存储成本,使得在资源有限的环境下进行模型微调成为可能。LoRA 便是 PEFT 的一种典型实现。
2.3. Qwen2-VL
Qwen2-VL 是基于 Qwen2 打造的新一代视觉语言模型。它具有以下显著特点:
- 多模态理解:能够读懂不同分辨率和长宽比的图片,理解长视频内容。
- 智能代理:可作为手机和机器人的视觉智能体,实现更丰富的交互体验。
- 多语言支持:支持多种语言,满足不同地区用户的需求。
目前,开源了 Qwen2-VL-2B 和 Qwen2-VL-7B 模型,并发布了 Qwen2-VL-72B 的 API。该模型在多个视觉能力评估方面表现优异,能够进行更细节的识别理解、视觉推理、视频理解与实时聊天等。
应用场景:
- 图像理解与识别:识别植物、地标等,理解场景中多个对象间的关系,识别手写文字及图像中的多种语言。
- 文档解析:能够解析包含密集公式的文档,理解文档中的内容。
- 多语言文本识别:转录图中多种语言的内容,并识别其语言类型。
- 解决现实世界问题:通过分析图片解决问题,解读复杂数学问题,从真实世界图像和图表中提取信息,执行指令。
- 视频内容分析:总结视频要点、即时回答相关问题,并维持连贯对话,帮助用户从视频中获取有价值的信息。
- 视觉代理:利用视觉能力完成自动化的工具调用和交互,例如实时数据检索。
- 与环境交互:像人一样与环境进行视觉交互,不仅作为观察者,还能作为执行者。
模型结构:
- 动态分辨率支持:Qwen2-VL 的一项关键架构改进是实现了动态分辨率支持(Naive Dynamic Resolution support)。与上一代模型 Qwen-VL 不同,Qwen2-VL 可以处理任意分辨率的图像,而无需将其分割成块,从而确保模型输入与图像固有信息之间的一致性。这种方法更接近地模仿人类的视觉感知,使模型能够处理任何清晰度或大小的图像。

- 多模态旋转位置嵌入:另一个关键的架构增强是 Multimodal Rotary Position Embedding (M-ROPE) 的创新。通过将 original rotary embedding 分解为代表时间和空间(高度和宽度)信息的三个部分,M-ROPE 使 LLM 能够同时捕获和集成 1D 文本、2D 视觉和 3D 视频位置信息。这使 LLM 能够充当强大的多模态处理器和推理器。

2.4. 模型合并
模型合并指的是将多个模型的权重或参数整合到一个新的模型中,形成一个更强大的模型。
模型合并的用途:
- 提升模型性能:整合不同模型的优势,从而提高模型的精度、鲁棒性等性能指标。
- 增强模型泛化能力:降低过拟合风险,使模型在不同数据集上表现更稳定。
- 减少模型尺寸:通过知识蒸馏等技术,减少模型的存储空间和计算量。
- 提高模型效率:优化模型结构,提高模型的推理效率。
三、前置条件
3.1. 基础环境及前置条件
- 操作系统:CentOS 7
- 硬件环境:NVIDIA RTX 4090 24GB * 2,CUDA Version: 12.2
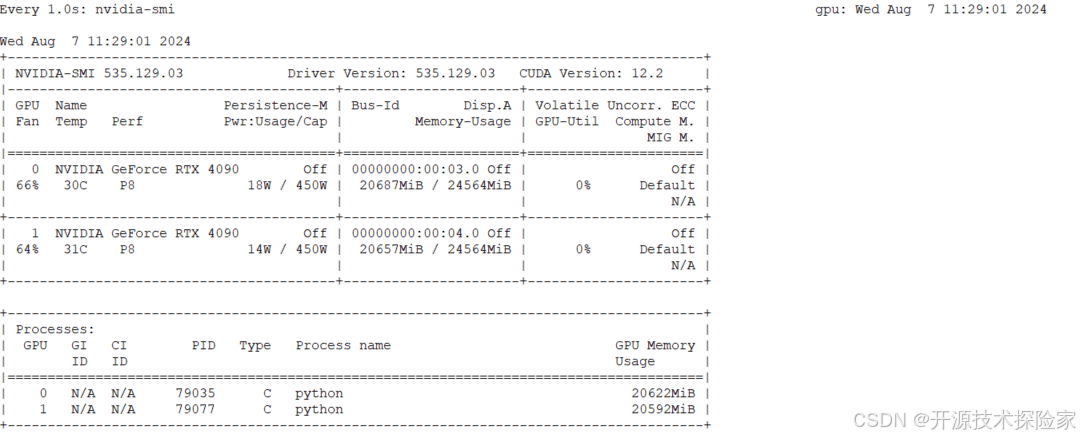
模型下载:提前下载好 Qwen2-7B-Instruct 模型,建议优先选择魔搭进行下载。
* ModelScope:`git clone https://www.modelscope.cn/qwen/Qwen2-7B-Instruct.git`
按需选择 SDK 或者 Git 方式下载。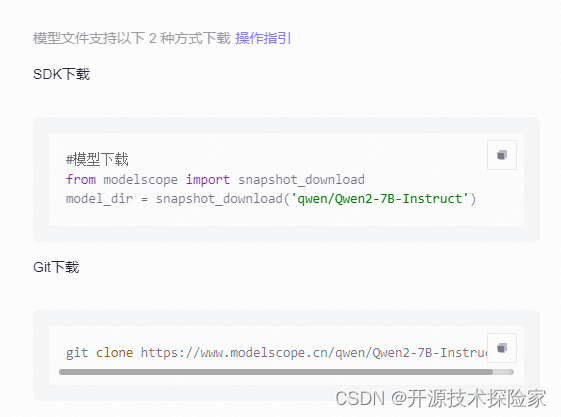
使用 git 方式下载示例(或者使用 git-lfs):
3.2. Anaconda 安装
具体安装步骤,请参见 “开源模型应用落地-qwen-7b-chat与vllm实现推理加速的正确姿势(一)”。
3.3. 下载 LLaMA-Factory
方式一:直接下载
地址:GitHub - hiyouga/LLaMA-Factory: A WebUI for Efficient Fine-Tuning of 100+ LLMs (ACL 2024)
方式二:使用 git 克隆项目
git clone https://github.com/hiyouga/LLaMA-Factory.git
下载好的项目放置在 /data/service 目录下。
3.4. 安装依赖
```bash
conda create --name llama_factory python=3.10
conda activate llama_factory
cd /data/service/LLaMA-Factory-main
pip install -e ".[torch,metrics]" -i https://pypi.tuna.tsinghua.edu.cn/simple
# v100 不需要安装 flash-attn
pip install flash-attn==2.6.3 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install bitsandbytes==0.43.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install deepspeed==0.14.4 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install --upgrade transformers
```PS:软硬件要求
- transformers 版本需要 ≥ 4.45.0

四、技术实现
4.1. 配置文件准备
备份原有的配置文件
cp /data/service/LLaMA-Factory-main/examples/merge_lora/qwen2vl_lora_sft.yaml /data/service/LLaMA-Factory-main/examples/merge_lora/qwen2vl_lora_sft.yaml.bak修改配置文件内容
vi /data/service/LLaMA-Factory-main/examples/merge_lora/qwen2vl_lora_sft.yaml内容如下:
### model model_name_or_path: /data/model/qwen2-vl-7b-instruct adapter_name_or_path: /data/model/sft/qwen2-vl-7b-instruct-sft/checkpoint-14 template: qwen2_vl finetuning_type: lora ### export export_dir: /data/model/merge/qwen2-vl-7b-instruct-sft export_size: 2 export_device: gpu export_legacy_format: false需要关注以下参数:
model_name_or_path:模型路径,指向 Qwen2-VL-7B-Instruct 模型的原始路径。adapter_name_or_path:权重路径,指向 LoRA 微调后的权重文件所在的目录。template:模版,选择与模型相匹配的模版,这里为qwen2_vl。finetuning_type:微调类型,指定微调方法,本示例使用 LoRA 方式。export_dir:模型合并后保存的路径,指定合并后的模型保存位置。
4.2. 启动合并
```bash
conda activate llama_factory
cd /data/service/LLaMA-Factory-main
llamafactory-cli export /data/service/LLaMA-Factory-main/examples/merge_lora/qwen2vl_lora_sft.yaml
```
4.3. 合并结果
执行上述命令后,将会看到如下输出信息:
```text
(llama_factory) [root@gpu LLaMA-Factory-main]# llamafactory-cli export /data/service/LLaMA-Factory-main/examples/merge_lora/qwen2vl_lora_sft.yaml
[INFO|configuration_utils.py:670] 2024-09-26 18:03:44,392 >> loading configuration file /data/model/qwen2-vl-7b-instruct/config.json
[WARNING|modeling_rope_utils.py:379] 2024-09-26 18:03:44,393 >> Unrecognized keys in `rope_scaling` for 'rope_type'='default': {'mrope_section'}
...
09/26/2024 18:03:56 - INFO - llamafactory.model.adapter - Merged 1 adapter(s).
09/26/2024 18:03:56 - INFO - llamafactory.model.adapter - Loaded adapter(s): /data/model/sft/qwen2-vl-7b-instruct-sft/checkpoint-14
09/26/2024 18:03:56 - INFO - llamafactory.model.loader - all params: 8,291,375,616
09/26/2024 18:03:56 - INFO - llamafactory.train.tuner - Convert model dtype to: torch.float16.
[INFO|configuration_utils.py:407] 2024-09-26 18:03:56,458 >> Configuration saved in /data/model/merge/qwen2-vl-7b-instruct-sft/config.json
[INFO|configuration_utils.py:868] 2024-09-26 18:03:56,459 >> Configuration saved in /data/model/merge/qwen2-vl-7b-instruct-sft/generation_config.json
[INFO|modeling_utils.py:2838] 2024-09-26 18:05:05,208 >> The model is bigger than the maximum size per checkpoint (2GB) and is going to be split in 10 checkpoint shards. You can find where each parameters has been saved in the index located at /data/model/merge/qwen2-vl-7b-instruct-sft/model.safetensors.index.json.
[INFO|tokenization_utils_base.py:2649] 2024-09-26 18:05:05,209 >> tokenizer config file saved in /data/model/merge/qwen2-vl-7b-instruct-sft/tokenizer_config.json
[INFO|tokenization_utils_base.py:2658] 2024-09-26 18:05:05,210 >> Special tokens file saved in /data/model/merge/qwen2-vl-7b-instruct-sft/special_tokens_map.json
[INFO|image_processing_base.py:258] 2024-09-26 18:05:05,407 >> Image processor saved in /data/model/merge/qwen2-vl-7b-instruct-sft/preprocessor_config.json
```合并后的文件:

至此,你已经成功地将微调后的 Qwen2-VL-7B-Instruct 模型权重与原始模型进行了合并。现在,你可以使用合并后的模型进行推理或部署。
通过本篇文章,你学习了如何使用 LLaMA-Factory 工具合并微调后的模型权重。掌握这些技术,将有助于你更好地利用大型语言模型,构建更智能、更高效的 AI 应用。在实践中,你可以根据自己的需求调整参数和配置,探索更多模型合并的可能性。








