
在人工智能领域,竞争日趋白热化。面对DeepSeek的凌厉攻势,谷歌迅速做出反应,发布了Gemini 2.0全家桶,旨在捍卫其行业地位。此次发布的Gemini 2.0系列包括Flash、Flash-Lite以及新一代旗舰大模型Gemini 2.0 Pro的实验版本,同时还在Gemini App中推出了推理模型Gemini 2.0 Flash Thinking,向所有用户开放。
Gemini 2.0系列模型各有侧重:Pro版本在代码和复杂提示方面表现卓越;Flash版本则拥有更高的速率限制、更强的性能和简化的定价;Flash-Lite则以其极具竞争力的性价比脱颖而出。Gemini 2.0 Flash Thinking Experimental则可在桌面端和移动端APP中体验,为用户提供更加便捷的人工智能服务。

从性能指标来看,这三个模型在通用性、代码能力、推理能力、事实性、多语言支持、数学能力、长上下文处理、图像理解、音频处理和视频处理等多个领域均有不俗表现。谷歌此举旨在通过不同版本的模型,满足不同用户的需求,进一步扩大Gemini系列的市场份额。
在价格方面,谷歌计划通过Gemini 2.0 Flash和2.0 Flash-Lite进一步降低成本,让更多的开发者和用户能够享受到人工智能带来的便利。此举无疑将加剧市场竞争,推动人工智能技术的普及。

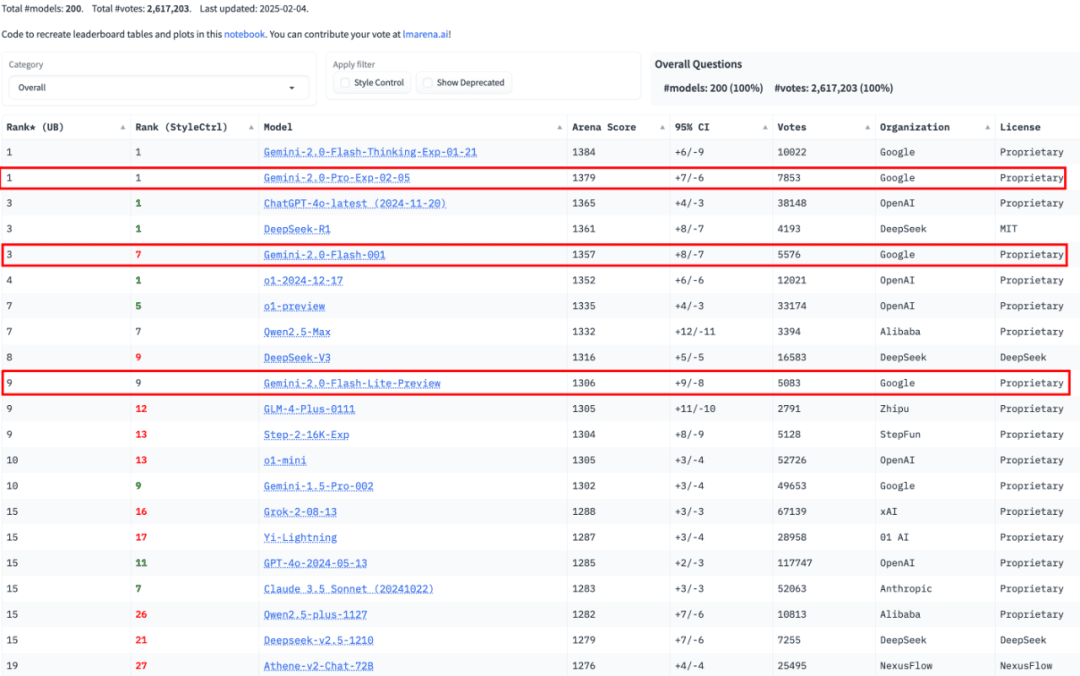
大模型LMSYS排行榜显示,Gemini 2.0 Pro与四大模型并列第一,Flash版本位列第三,Flash-Lite位列第九。这一排名充分展示了Gemini 2.0系列模型的实力,也为用户选择模型提供了参考。
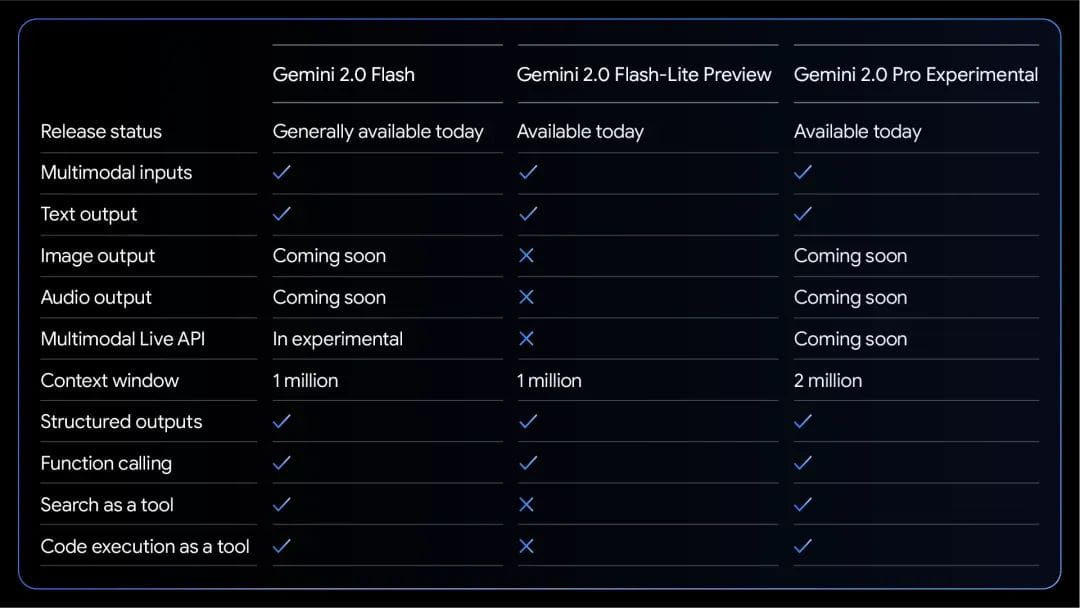
从模型参数汇总可以看出,图像和音频功能即将上线,这意味着Gemini 2.0系列模型将具备更强大的多模态处理能力,应用场景也将更加广泛。
值得一提的是,在谷歌正式发布Gemini 2系列的同时,OpenAI也迅速作出回应,宣布将其AI搜索功能面向所有免费用户开放。这场人工智能领域的竞争,正在以前所未有的速度演进。
与此同时,国内人工智能领域也呈现出一片繁荣景象。越来越多的平台选择接入DeepSeek大模型,以提升自身的服务能力。
自2月以来,华为、百度、阿里、腾讯等多个平台纷纷宣布与DeepSeek大模型展开合作。2月4日,华为计算宣布,潞晨科技携手昇腾,联合发布基于昇腾算力的DeepSeek R1系列推理API及云镜像服务。

潞晨科技以自研国产推理引擎为技术底座,成功实现了国产华为昇腾910B算力与DeepSeek R1系列模型的推理适配优化,性能表现与使用高端GPU持平。这为开发者提供了高效、灵活、稳定的AI推理服务,助力企业实现降本增效,加速智能业务基于国产软硬件体系快速部署落地。
近期,百度智能云、华为云、阿里云、腾讯云、云轴科技等多家平台也宣布接入DeepSeek模型,进一步扩大了DeepSeek大模型的影响力。
2月4日,火山引擎宣布将支持V3/R1等不同尺寸的DeepSeek开源模型,并提供多种使用方式。2月3日,百度智能云宣布,百度智能云千帆平台已正式上架DeepSeek-R1和DeepSeek-V3模型,并推出了超低价格方案和限时免费服务。同日,阿里云也宣布,阿里云PAI Model Gallery支持云上一键部署DeepSeek-V3、DeepSeek-R1。
2月2日,腾讯云和秘塔AI先后宣布接入DeepSeek-R1模型。腾讯云表示,将DeepSeek-R1大模型一键部署至腾讯云「HAI」上,开发者仅需3分钟就能接入调用。云轴科技ZStack也在2月2日宣布,其AI Infra平台ZStack智塔全面支持企业私有化部署DeepSeek-V3/R1/Janus Pro三种模型,并可基于海光、昇腾、英伟达、英特尔等多种国内外CPU/GPU适配。2月1日,硅基流动和华为云团队联合首发并上线基于华为云昇腾云服务的DeepSeek-R1/V3推理服务。
在开源模型方面,艾伦人工智能研究所(Ai2)推出了Tülu 3 8B和70B,在性能上超越了同等参数的Llama 3.1 Instruct版本。2024年11月,Ai2发布了长达82页的论文,详细公布了其训练细节,包括训练数据、代码和测试基准。

1月30日,艾伦人工智能研究所(Ai2)又推出了基于强化学习的新一代开源模型Tülu3 405B,其性能甚至超越了DeepSeek V3和GPT-4o,并完整发布了训练数据方法。该模型采用了新的后训练框架RLVR,标志着开放后训练研究进入了一个新的里程碑,为开发者提供了构建高性能模型的基础。
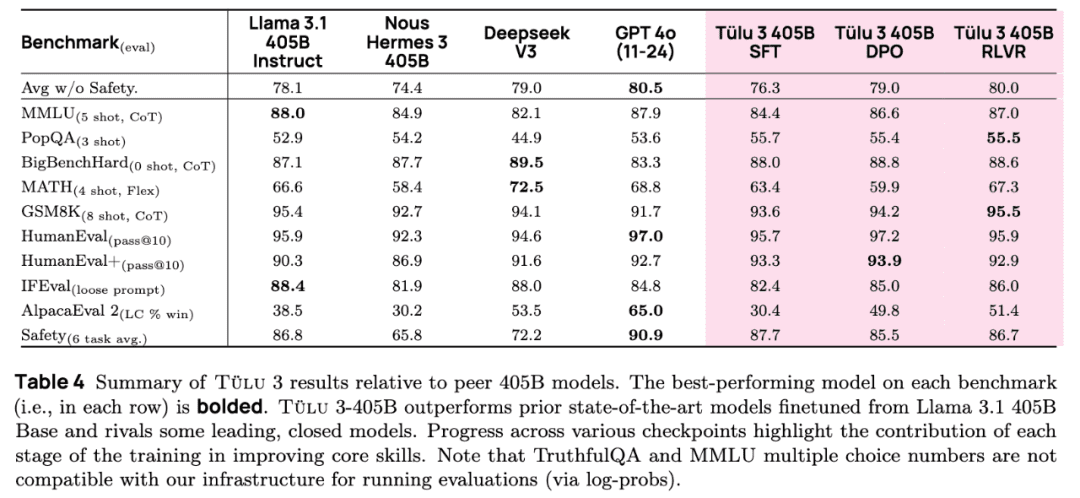
在许多标准的基准测试中,Tülu3 405B均实现了与Deepseek V3和GPT-4o相当或更优的性能,同时也超越了许多先前发布的后训练开源模型(同等参数规模),包括Llama 3.1 405B Instruct和Nous Hermes 3 405B。
各项基准结果比较显示,经过强化学习优化过的Tülu 3 405B在多项指标上超越了Deepseek V3,尤其是在数学推理和安全性方面表现突出。
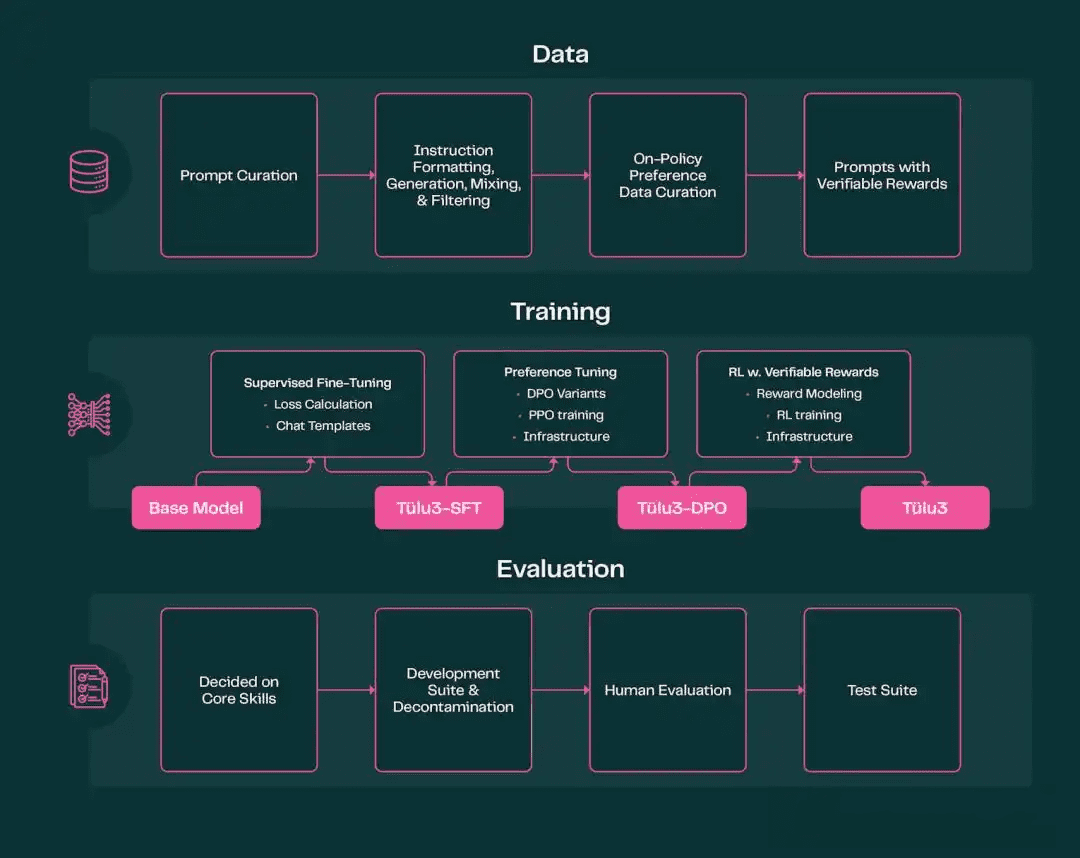
Tülu 3的构建流程主要包括数据、训练和评估三个部分,为开发者提供了全面的参考。
人工智能领域的竞争愈发激烈,各大厂商纷纷推出更强大的模型和更优惠的服务,力求在市场中占据有利地位。无论是谷歌的Gemini 2.0系列,还是DeepSeek大模型的广泛应用,亦或是Ai2的Tülu3 405B,都展现了人工智能技术的巨大潜力和发展前景。未来,随着技术的不断进步和应用场景的不断拓展,人工智能将在更多领域发挥重要作用。
人工智能的未来发展趋势将更加注重模型的效率和可扩展性。更小、更快的模型将更容易部署在边缘设备上,实现更广泛的应用。同时,多模态融合将成为重要的发展方向,模型将能够处理图像、音频、视频等多种类型的数据,从而更好地理解和模拟人类的智能。
此外,人工智能的伦理问题也将受到越来越多的关注。如何确保人工智能的公平性、透明性和可解释性,避免其被用于恶意目的,将是未来人工智能发展的重要课题。只有在解决这些伦理问题的前提下,人工智能才能真正为人类带来福祉。
总而言之,人工智能领域正迎来一个快速发展的时代。各大厂商之间的竞争将推动技术的不断创新,而技术的进步又将为人工智能的应用开辟更广阔的空间。让我们拭目以待,共同见证人工智能的未来。








