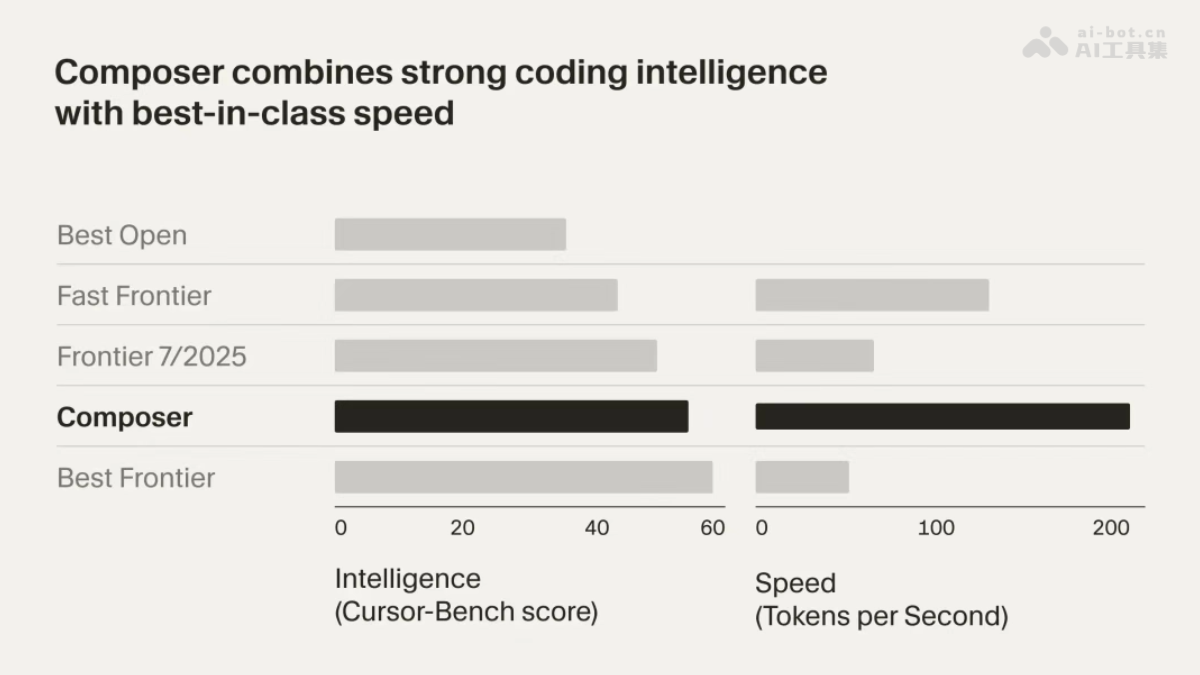
在数字化内容生态面临重大变革的今天,一场由网络基础设施巨头Cloudflare引领的"安静监管"正在悄然进行。这家支撑着全球近20%网络流量的公司,通过大规模更新网站的robots.txt文件,向Google的AI主导地位发起挑战。这一举措不仅关乎技术标准的调整,更涉及到整个互联网经济模式的根本性变革。
背景冲突:AI摘要与传统网络经济的碰撞
自2023年以来,Google推出了一种让网站管理员选择退出其大型语言模型(如Gemini)训练内容的方法。然而,这一选项与传统的搜索引擎爬取和索引机制被捆绑在一起,使得网站管理者面临两难选择:要么接受Google使用其内容生成AI摘要,要么完全切断Google的流量来源。
这种捆绑政策引发了内容发布者的强烈不满。皮尤研究中心2025年7月的一项研究显示,当搜索结果页面顶部出现AI摘要时,用户点击链接的比例从15%骤降至8%。《华尔街日报》援引多家主流媒体的内部流量数据指出,由于AI摘要的推出,这些网站的流量出现了行业性下滑,导致裁员和战略调整。
新闻网站、研究机构等依赖流量变现的内容创作者发现,他们精心制作的内容被AI系统直接消化,却无法获得相应的补偿或流量回馈。这种"内容被掠夺"的现象正在动摇整个网络经济的根基。
Cloudflare的反击:内容信号政策的推出
面对这一困境,Cloudflare在2025年9月24日宣布推出"内容信号政策"(Content Signals Policy),试图利用其市场影响力改变网络爬虫与内容提供者之间的关系。
robots.txt的演进与局限
自1994年起,网站开始在域名根目录放置名为"robots.txt"的文件,向自动化网络爬虫指示哪些部分应该被爬取和索引,哪些应该被忽略。这一标准逐渐成为网络爬虫的"行为准则",Google的爬虫也一直遵循这一规则。
然而,传统的robots.txt只能告诉爬虫是否可以访问内容,而不能规定内容的具体用途。例如,Google支持通过"Google-Extended"代理禁止爬取用于训练Gemini模型的内容,但这并不能阻止内容被用于检索增强生成(RAG)和AI摘要。
新政策的核心创新
Cloudflare的新提案旨在扩展robots.txt的功能,使其能够区分内容的不同用途。根据内容信号政策,网站运营商可以明确选择是否同意以下三种使用场景:
- 搜索:构建搜索索引并提供搜索结果
- AI输入:将内容输入到一个或多个AI模型(如RAG、基础构建或其他实时获取内容用于生成AI搜索答案)
- AI训练:训练或微调AI模型
Cloudflare已为其客户提供了快速设置这些值的途径,并自动更新了380万个使用其托管robots.txt功能的域名的robots.txt文件。默认设置是:搜索允许,AI训练禁止,AI输入保持中性。