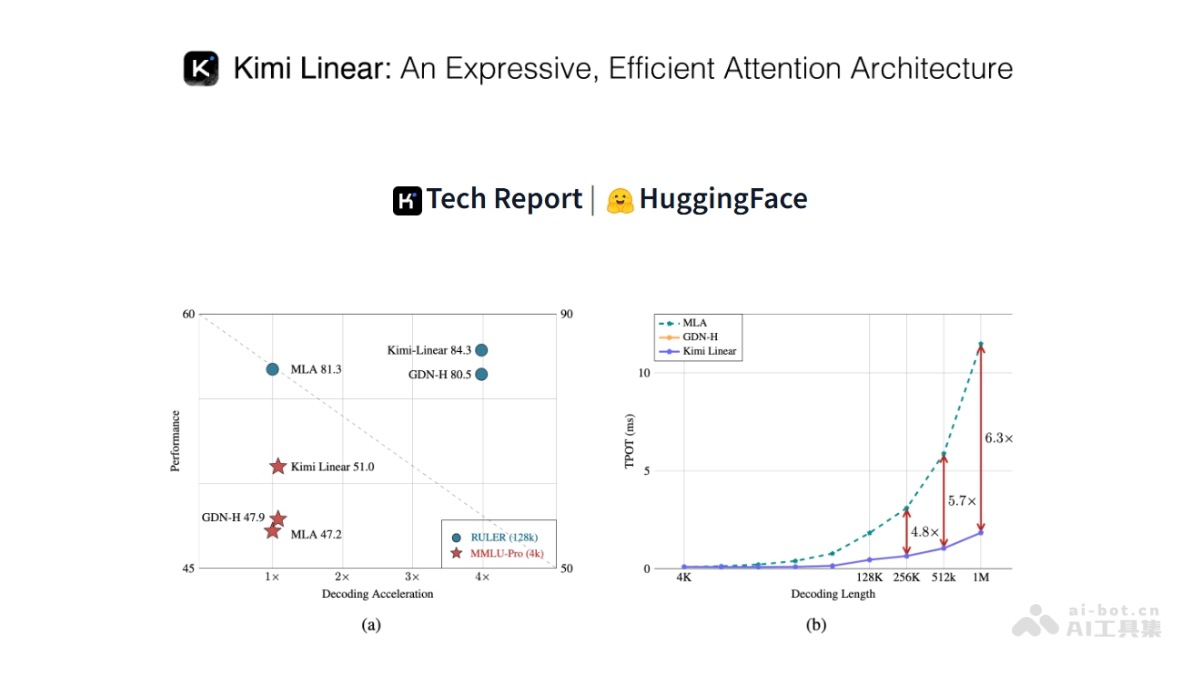
人工智能领域近日迎来重大技术突破。月之暗面(MoonshotAI)正式发布革命性的"Kimi Linear"混合线性注意力架构,这一创新不仅在理论层面带来了Attention机制的全新范式,更在实际应用中展现出惊人的性能提升。据官方数据显示,该架构在KV缓存管理方面实现了75%的减少,解码吞吐量最高提升6倍,训练速度更是实现了6.3倍的显著加速。这一系列数据指标不仅刷新了行业记录,更为大模型的发展开辟了全新路径。
传统注意力机制的瓶颈与挑战
在深入探讨Kimi Linear的创新之前,有必要先了解传统注意力机制面临的挑战。自Transformer架构提出以来,自注意力机制(Self-Attention)已成为现代大模型的基石。然而,随着模型规模的不断扩大和序列长度的持续增加,传统注意力机制逐渐暴露出几个关键瓶颈:
计算复杂度问题:传统自注意力的计算复杂度与序列长度的平方(O(n²))成正比,这意味着当处理长文本时,计算资源需求呈指数级增长。
内存占用困境:KV(Key-Value)缓存机制虽然加速了推理过程,但也带来了巨大的内存压力,尤其是在处理超长文本时。
长距离依赖捕捉困难:尽管理论上自注意力可以捕捉任意距离的依赖关系,但在实践中,随着距离的增加,有效信息往往被稀释。
训练与推理效率差异:许多模型在训练阶段表现优异,但在推理阶段却面临效率挑战,难以满足实时应用需求。
这些瓶颈不仅限制了模型的应用场景,也增加了部署成本,成为制约AI技术普及的关键因素。月之暗面的研发团队正是针对这些痛点,提出了Kimi Linear这一创新解决方案。
Kimi Linear架构的核心创新
Kimi Linear架构最引人注目的创新在于其独特的"Kimi Delta Attention"(KDA)机制,这是对Gated DeltaNet的优化升级。KDA通过引入更高效的门控机制,显著提升了有限状态RNN(递归神经网络)记忆的使用效率,从根本上改变了注意力计算的方式。
三重KDA与全局MLA的协同设计
Kimi Linear的架构设计极具特色,由三份Kimi Delta Attention和一份全局MLA(多层感知机)组成。这种"3+1"的设计模式并非简单的堆叠,而是经过精心设计的协同工作机制:
- 三重KDA:负责处理不同粒度的信息,分别关注局部、区域和全局特征,形成多层次的信息提取机制。
- 全局MLA:作为补充,提供非线性变换能力,增强模型的表达灵活性。
这种架构设计使得Kimi Linear能够在保持计算效率的同时,不牺牲模型的表达能力,实现了性能与效率的完美平衡。
细粒度门控机制的创新
KDA的核心在于其细粒度门控机制。与传统的门控单元不同,KDA的门控设计更加精细,能够动态调整不同信息通道的权重。具体来说:
- 选择性记忆:门控机制能够智能决定哪些信息需要被保留在有限状态RNN的记忆中,哪些可以被遗忘。
- 信息压缩:通过高效的编码方式,将关键信息压缩到有限的状态空间中,大幅减少内存占用。
- 动态调整:根据输入数据的特性,实时调整门控策略,适应不同类型的任务需求。
这种设计不仅提高了模型处理信息的速度,还显著降低了内存消耗,为长文本处理提供了可能。
性能突破:数据背后的意义
官方公布的数据令人印象深刻,但这些数字背后蕴含的技术意义更为深远。让我们深入分析这些性能提升背后的技术原理和实际价值。
KV缓存减少75%的内存革命
KV缓存减少75%是Kimi Linear最引人注目的成就之一。在传统Transformer架构中,为了加速自回归解码过程,模型需要保存之前所有token的Key和Value向量,这导致内存占用随序列长度线性增长。对于处理百万token级别的任务,这种内存需求变得难以承受。
Kimi Linear通过以下方式实现了这一突破:
- 选择性存储:KDA门控机制能够识别并只保留对后续生成最重要的token信息,大幅减少需要存储的数据量。
- 高效编码:通过创新的编码方式,将多个token的信息压缩表示,在保持信息完整性的同时减少存储空间。
- 分层缓存:不同层次的KDA负责不同粒度的信息,实现了更精细的缓存管理。
这一突破意味着在相同硬件条件下,模型可以处理更长的文本序列,或者同时处理更多并行任务,极大地扩展了AI模型的应用边界。
推理速度提升6倍的效率飞跃
解码吞吐量提升6倍直接关系到AI服务的响应速度和并发能力。在实时翻译、内容生成等对延迟敏感的应用场景中,这一提升具有革命性意义。
实现这一加速的关键技术包括:
- 并行计算优化:Kimi Linear的架构天然支持更高程度的并行计算,充分利用现代GPU的并行处理能力。
- 计算复杂度降低:通过线性注意力机制,将计算复杂度从O(n²)降低到O(n)或O(n log n),显著减少了计算量。
- 内存访问优化:减少的KV缓存意味着更少的内存访问操作,避免了内存带宽瓶颈。
这一提升不仅改善了用户体验,还降低了服务成本,使AI技术能够应用于更多实时场景。
训练速度提升6.3倍的范式转变
训练速度提升6.3倍是Kimi Linear的另一大亮点。在模型训练阶段,这一提升意味着:
- 研发周期缩短:模型迭代和优化所需的时间大幅减少,加速了AI技术的创新进程。
- 能耗降低:训练时间的减少直接对应着能源消耗的降低,有助于实现更可持续的AI发展。
- 更大规模训练可能:在相同时间内可以完成更大规模的数据训练,推动模型能力的边界。
实现这一突破的关键在于Kimi Linear对传统训练流程的重新设计,通过更高效的注意力计算和内存管理,解决了训练过程中的多个效率瓶颈。
技术原理深度解析
要真正理解Kimi Linear的革命性意义,需要深入其技术原理。下面我们将从数学基础和工程实现两个层面,剖析这一创新架构的工作机制。
数学基础:从全局注意力到线性注意力的转变
传统自注意力的核心计算可以表示为:
Attention(Q, K, V) = softmax((QK^T)/√d_k) * V
其中Q、K、V分别是查询(Query)、键(Key)和值(Value)矩阵,d_k是键向量的维度。这种计算方式导致复杂度为O(n²),因为需要计算所有查询与所有键之间的点积。
Kimi Linear通过引入线性注意力机制,将复杂度降低到O(n)。其核心思想是将点积操作替换为更高效的线性变换:
LinearAttention(Q, K, V) = softmax(QK^T) * V ≈ φ(Q)φ(K)^T * V
其中φ是一个非线性变换函数。这种近似虽然牺牲了一定的精度,但带来了计算效率的巨大提升。
工程实现:KDA门控机制的工作原理
KDA门控机制是Kimi Linear的核心创新,其工作原理可以概括为以下几个步骤:
- 输入预处理:对输入序列进行初步编码,提取特征表示。
- 门控计算:通过专门的门控网络,计算每个时间步需要保留和遗忘的信息。
- 状态更新:根据门控信号,更新有限状态RNN的隐藏状态,实现信息的压缩和选择。
- 输出生成:基于更新后的状态,生成注意力输出。
这一过程与传统RNN的状态更新有本质区别:KDA的门控机制更加精细,能够同时处理多个时间步的信息,并且具有全局视野。
与现有技术的比较优势
与现有的注意力优化技术相比,Kimi Linear具有以下明显优势:
相比稀疏注意力:虽然稀疏注意力通过限制注意力范围降低了计算复杂度,但可能会丢失长距离依赖信息。Kimi Linear通过线性机制保持了全局视野。
相比低秩近似:低秩近似方法通过矩阵分解减少计算量,但可能会损失信息。Kimi Linear的门控机制是信息选择而非信息丢弃。
相比循环注意力:循环注意力通过迭代方式近似全局注意力,但计算效率仍然较低。Kimi Linear实现了真正的线性复杂度。
这些优势使得Kimi Linear在保持模型性能的同时,实现了计算效率的显著提升。
实际应用场景与价值
技术的价值最终体现在应用中。Kimi Linear的创新设计使其在多个场景中展现出独特优势,为AI技术的实际应用开辟了新可能。
长文本处理的新突破
长文本处理一直是AI领域的难点,尤其在法律文档、学术论文、书籍等超长内容理解方面。传统模型往往面临以下挑战:
- 上下文窗口限制:大多数模型的上下文窗口有限,难以处理完整的长文档。
- 信息丢失:在处理长文本时,早期信息往往被稀释或遗忘。
- 计算资源需求高:长文本处理需要巨大的计算资源,成本高昂。
Kimi Linear通过以下方式解决这些问题:
- 扩展上下文窗口:KV缓存减少75%意味着在相同内存条件下,可以处理更长的文本序列。
- 信息保留增强:门控机制能够智能保留关键信息,减少信息丢失。
- 效率提升:推理速度的提升使得长文本处理更加经济可行。
这一突破将极大促进AI在内容创作、文档分析、法律咨询等领域的应用。
实时AI服务的加速器
在实时翻译、智能客服、内容生成等对延迟敏感的应用场景中,推理速度至关重要。Kimi Linear的6倍速度提升将带来以下变革:
- 响应时间缩短:用户等待时间大幅减少,体验显著改善。
- 并发能力提升:在相同硬件条件下,可以支持更多并发用户。
- 部署成本降低:更高的效率意味着更低的单位服务成本。
这些优势将使AI技术能够应用于更多实时场景,推动AI服务的普及。
多模态融合的理想选择
随着AI技术的发展,多模态融合成为趋势,需要同时处理文本、图像、音频等多种类型的数据。Kimi Linear在这一场景中具有独特优势:
- 统一处理框架:线性注意力机制可以自然扩展到不同模态的数据处理。
- 资源效率高:在处理多种模态数据时,内存和计算资源的高效利用尤为重要。
- 长距离依赖捕捉:多模态任务往往需要捕捉跨模态的长距离依赖关系。
Kimi Linear的这些特性使其成为构建下一代多模态AI系统的理想选择。
行业影响与未来展望
Kimi Linear的发布不仅是一项技术创新,更可能对整个AI行业产生深远影响。从技术路线到应用场景,从研发模式到产业格局,这一突破都可能带来连锁反应。
对大模型发展的范式影响
Kimi Linear代表了注意力机制的一次重要演进,可能引发以下范式转变:
- 从复杂到高效:AI模型的发展可能从单纯追求规模和复杂度,转向更加注重效率和创新架构。
- 从通用到专用:针对特定场景优化的专用架构可能受到更多关注,与通用模型形成互补。
- 从理论到工程:更加注重工程实现的创新架构将获得更多青睐,推动AI技术的实用化进程。
这些转变将重塑AI技术的发展方向,推动行业向更高效、更实用的方向演进。
对产业格局的潜在重塑
从产业角度看,Kimi Linear的突破可能带来以下影响:
- 竞争格局变化:拥有高效架构的厂商将在算力资源有限的情况下获得竞争优势。
- 应用边界扩展:效率提升将使AI能够应用于更多资源受限的场景,扩大市场空间。
- 合作模式创新:开源与商业化可能形成新的平衡,推动技术生态的健康发展。
这些变化将为AI产业注入新的活力,促进创新和竞争良性循环。
未来技术演进方向
基于Kimi Linear的创新,我们可以预见以下技术演进方向:
- 架构进一步优化:在现有基础上,可能出现更多针对特定场景的优化变种。
- 与其他技术的融合:如与神经符号AI、因果推理等技术的结合,可能产生新的突破。
- 硬件协同设计:软件架构的创新将推动专用硬件的发展,形成软硬件协同优化的良性循环。
这些方向将进一步推动AI技术的边界,为人类社会带来更多可能。
结语
月之暗面发布的Kimi Linear架构代表了注意力机制的一次重大突破,通过创新的KDA门控机制和线性注意力设计,实现了KV缓存减少75%、推理速度提升6倍、训练速度提升6.3倍的显著成就。这一创新不仅解决了传统注意力机制在效率方面的瓶颈,还为AI技术的实际应用开辟了新可能。
从技术原理到实际应用,从行业影响到未来展望,Kimi Linear都展现出其作为下一代AI架构的潜力。随着这一技术的进一步发展和普及,我们有理由相信,AI技术将迎来更加高效、更加实用的新时代,为人类社会带来更多价值。
技术的进步永无止境,Kimi Linear的发布只是一个开始。在未来的发展中,我们期待看到更多这样的创新,推动AI技术不断向前,创造更美好的智能未来。