
在人工智能领域,Gemini 和 ChatGPT 无疑是备受瞩目的焦点。它们不仅代表了当前语言模型的最高水平,也在不断推动着 AI 技术的发展边界。本文将深入剖析 Gemini 的技术架构和数据工程,并结合 AlphaCode 2 的案例,探讨如何从原理到实践,构建一个类 Gemini/ChatGPT 的大模型。
Gemini 技术架构深度剖析
Google 推出的 Gemini 模型家族,以其在文本、图像、音频、视频等多模态上的卓越能力而备受瞩目。Gemini 系列包含 Ultra、Pro 和 Nano 三种尺寸,旨在满足从复杂的推理任务到设备内存受限的应用场景的广泛需求。其中,Gemini Ultra 作为最强大的模型,能够在各种高度复杂的任务中提供最先进的性能,尤其是在推理和多模态任务方面表现突出。Gemini 架构的设计使其在 TPU 加速器上能够高效地进行规模化服务,这为大规模部署提供了坚实的基础。
Gemini 模型基于 Transformer 解码器构建,并针对神经网络结构和目标进行了优化,从而提升了大规模预训练时训练和推理的稳定性。与 GPT 类似,Gemini 采用 Decoder-only 架构,通过预测下一个 token 的方式进行学习。该模型经过训练,能够支持 32k 的上下文长度,并采用了高效的注意力机制,如多查询注意力(MQA),这使得模型能够处理更长的序列,从而更好地捕捉上下文信息。
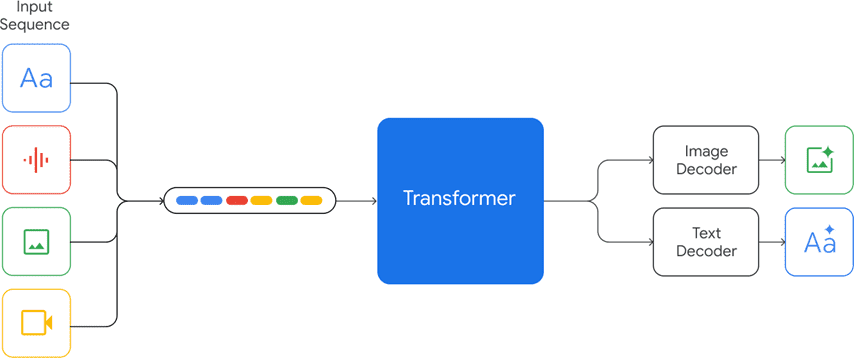
Gemini 的一个显著特点是其对多模态数据的支持。该模型能够接收文本、图像、音频和视频的交错序列作为输入,并输出交错的图像和文本响应。这种多模态输入输出的能力,使得 Gemini 能够更好地理解和生成与现实世界相关的复杂信息。
为了实现多模态数据的统一处理,Gemini 采用了将不同模态数据联合起来从头训练的方法。该方法遵循 next token prediction 的模式,将文本、图片、音频、视频等不同模态的数据转换为 token,然后将图片、视频等平面数据转换为 32*32 (举例) 的 tokens,最终变成一维线性输入,让模型预测 next token。这种方法将不同模态的数据在预训练阶段统一起来,使得模型能够更好地学习不同模态之间的关联性。
Gemini 模型在训练算法、数据集和基础设施方面进行了创新。对于 Pro 模型,采用了基础设施和学习算法的固有可扩展性,使其能够在几周内完成预训练,并利用 Ultra 的一小部分资源。Nano 系列模型则利用了蒸馏和训练算法的进一步改进,为各种任务(如摘要和阅读理解)提供了最佳的小型语言模型。
Gemini 数据工程深度剖析
Gemini 模型是在一个既包含多模态又包含多语言的数据集上进行训练的。预训练数据集使用了来自网络文档、书籍和代码的数据,并包括图像、音频和视频数据。多样化的数据来源保证了模型的泛化能力和适应性。
为了更好地处理多语言数据,Gemini 使用了 SentencePiece 分词器。研究表明,在整个训练语料库的大样本上训练分词器可以改善推断的词汇,并进而提高模型性能。例如,Gemini 模型可以高效地标记非拉丁脚本,这反过来可以提高模型质量以及训练和推理速度。
数据质量是训练高性能模型的关键。Gemini 团队对所有数据集应用了质量过滤器,使用启发式规则和基于模型的分类器来筛选数据。此外,还进行了安全过滤以删除有害内容。为了保证评估的公正性,团队还从训练语料库中筛选出评估集。通过对较小的模型进行消融实验,最终确定了最终的数据混合和权重。在训练过程中,团队还采用了分阶段训练的方法,通过增加领域相关数据的权重来改变混合组合,直到训练结束。这些措施确保了模型能够从高质量的数据中学习,从而提高模型的性能和可靠性。
AlphaCode 2 技术架构深度剖析
AlphaCode 2 是 AlphaCode 团队构建的一个新的基于 Gemini 的代理程序,它将 Gemini 的推理能力与搜索和工具使用相结合,以在解决竞争性编程问题方面表现出色。AlphaCode 2 在 Codeforces 竞技编程平台上排名前 15% 的参赛者中,相比于排名前 50% 的最新技术前身有了很大的改进,其架构设计如下:
- 多个策略模型:用于为每个问题生成各自的代码样本。
- 采样机制:能够生成多样化的代码样本,以在可能的程序解决方案中进行搜索。
- 过滤机制:移除那些不符合问题描述的代码样本。
- 聚类算法:将语义上相似的代码样本进行分组,以减少重复。
- 评分模型:用于从 10 个代码样本集群中筛选出最优解。
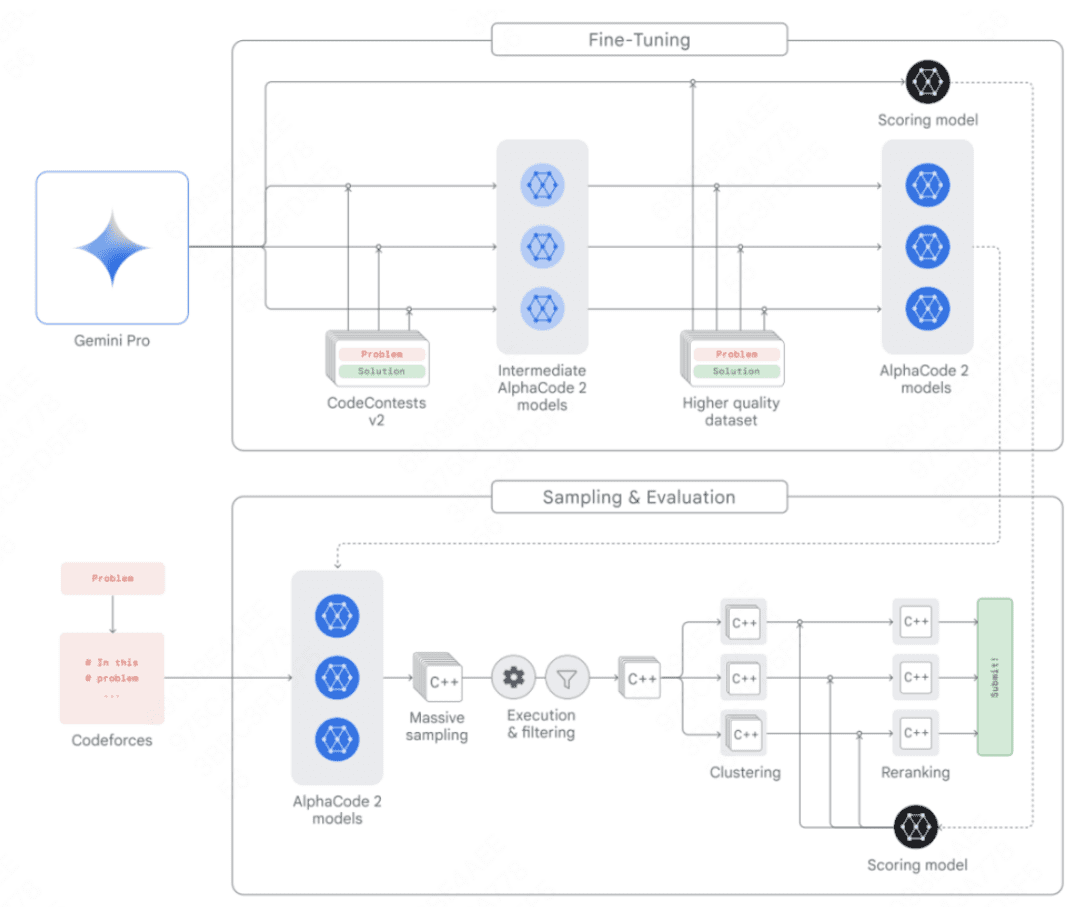
AlphaCode 2 的成功表明,将大型语言模型的推理能力与搜索和工具使用相结合,可以有效地解决复杂的编程问题。其架构设计为构建类似的应用提供了有益的借鉴。
从原理到实践:构建类 Gemini/ChatGPT 大模型
要构建一个类 Gemini/ChatGPT 的大模型,需要深入理解其技术架构和数据工程,并结合实际应用场景进行创新。以下是一些关键步骤和考虑因素:
- 选择合适的模型架构:Transformer 架构是当前大型语言模型的主流选择。可以根据实际需求选择 Decoder-only 或 Encoder-Decoder 架构。同时,需要关注最新的模型架构进展,如 MQA 等,以提高模型的性能和效率。
- 构建高质量的多模态数据集:数据是训练大型语言模型的关键。需要构建一个包含文本、图像、音频和视频等多模态数据的数据集。同时,需要对数据进行清洗、过滤和标注,以提高数据质量。
- 采用合适的训练方法:预训练和微调是训练大型语言模型的常用方法。可以采用自监督学习的方式进行预训练,然后根据具体任务进行微调。同时,需要关注最新的训练方法进展,如分阶段训练等,以提高模型的性能和效率。
- 优化模型推理性能:大型语言模型的推理计算量巨大,需要采用各种优化技术来提高推理性能。可以采用模型压缩、量化、剪枝等技术来减小模型大小和计算量。同时,可以利用 GPU、TPU 等硬件加速器来加速推理过程。
- 结合实际应用场景进行创新:大型语言模型的应用场景非常广泛。可以结合实际应用场景,进行模型定制和优化。例如,在智能客服领域,可以构建一个能够理解用户意图并生成自然语言回复的智能客服模型;在内容创作领域,可以构建一个能够自动生成文章、视频等内容的智能创作模型。
总而言之,构建一个类 Gemini/ChatGPT 的大模型是一个复杂而具有挑战性的任务。只有深入理解其技术架构和数据工程,并结合实际应用场景进行创新,才能成功构建出具有竞争力的 AI 产品。








