
最近,谷歌DeepMind推出了其号称是谷歌史上功能最强大、最通用的多模态模型——Gemini 1.0,这一事件在人工智能领域引起了广泛关注。Gemini 1.0被设计为一套全面的模型,旨在处理各种复杂的任务,并提供高效的设备端解决方案。
Gemini 1.0 分为三个版本,分别是 Gemini Ultra、Gemini Pro 和 Gemini Nano。其中,Gemini Ultra 是最大、最强的模型,适用于需要高度复杂处理的任务;Gemini Pro 是在各种任务中都能表现出色的模型,具有良好的可扩展性;而 Gemini Nano 则是最高效的设备端任务模型。
谷歌发布的测评报告宣称,Gemini Ultra 在多项任务上的表现超越了 GPT-4,而 Gemini Pro 则与 GPT-3.5 的性能相当。然而,这一说法很快受到了质疑。有网友指出,Gemini Ultra 在测评中可能存在一些“小动作”,有刻意刷榜、夸大性能的嫌疑,甚至演示视频也被质疑为“合成造假”。
不仅 Gemini Ultra 超越 GPT-4 的说法受到了质疑,Gemini Pro 的性能是否真的能赶超 GPT-3.5 也存在疑问。卡耐基梅隆大学的学者对 OpenAI 的 GPT 模型和 Google 的 Gemini 模型进行了深入的语言能力测试,涵盖了推理、知识问答、数学问题解决、语言翻译、代码生成和指令跟随等多个方面。他们公开了可复现的代码和完全透明的结果,为研究的公正性提供了保障。
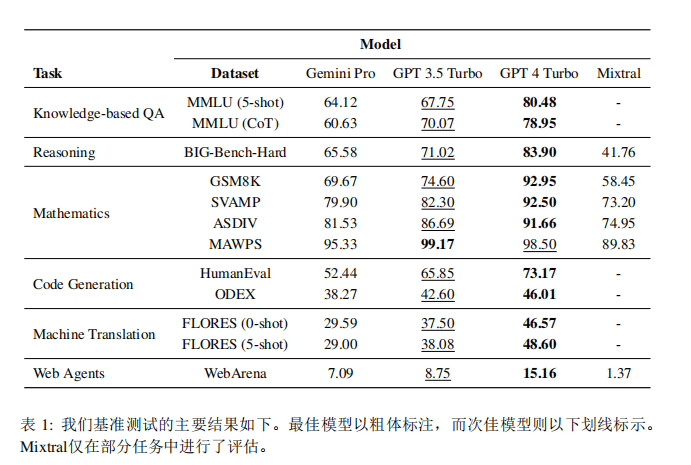
研究结果显示,Gemini Pro 在所有评估任务中的表现均不如 GPT-3.5 Turbo,与 GPT-4 Turbo 相比更是存在明显的差距。这一发现与谷歌的官方测评报告形成了鲜明对比。
面对这些质疑,谷歌发布了 Gemini 评测报告作为回应,声称 Gemini Pro 的性能优于 GPT 3.5,并且即将于 2024 年初推出的更强大的版本 Gemini Ultra,在谷歌的内部研究中得分高于 GPT 4。谷歌在回应中表示,他们通过一系列基于文本的学术基准测试,对 Gemini Pro 和 Ultra 与其他外部 LLM 以及之前的最佳模型 PaLM 2 进行了比较,这些基准测试涵盖了推理、阅读理解、STEM 和编程等领域。结果表明,Gemini Pro 的性能优于推理优化模型,如 GPT-3.5,与目前可用的最强大的几个模型相当,而 Gemini Ultra 的性能超过了所有现有模型。特别是在 MMLU 上,Gemini Ultra 达到了 90.04% 的准确率,是第一个超过这一阈值的模型。
谷歌也承认,由于数据污染等问题,评估的可靠性可能受到挑战,但他们已经尽可能保证结果的真实可靠性。

接下来,我们将深入探讨卡耐基梅隆大学的这份报告,了解其具体的研究方法和发现。
实验设置
卡耐基梅隆大学的报告中,研究人员使用了 LiteLLM 提供的统一接口来查询 Gemini Pro、GPT-3.5 Turbo、GPT-4 和 Mixtral 四个模型。其中,Mixtral 是一个开源的专家混合模型,由八个 7B 参数模型组成,其准确性与 GPT 3.5 Turbo 相当,因此也被纳入了比较之中。作者还列出了每个模型通过 API 访问的定价。

接下来,我们将详细分析每个任务上的模型表现。
基于知识的问答
研究人员使用 MMLU 数据集来评估模型的知识问答能力。MMLU 包含科学、技术、工程、数学、人文、社会科学等各个主题的多项选择题,总共有 14,042 个测试样本。研究人员分别在 5-shot 的条件下,使用标准提示和思维链提示生成答案。
从整体结果来看,Gemini Pro 的准确率低于 GPT 3.5 Turbo,且远低于 GPT 4 Turbo。另外,使用思维链引导时性能几乎没有差异。这可能是因为 MMLU 主要是一个以知识为基础的问答任务,可能无法从更强的推理导向的提示中获得显著的好处。
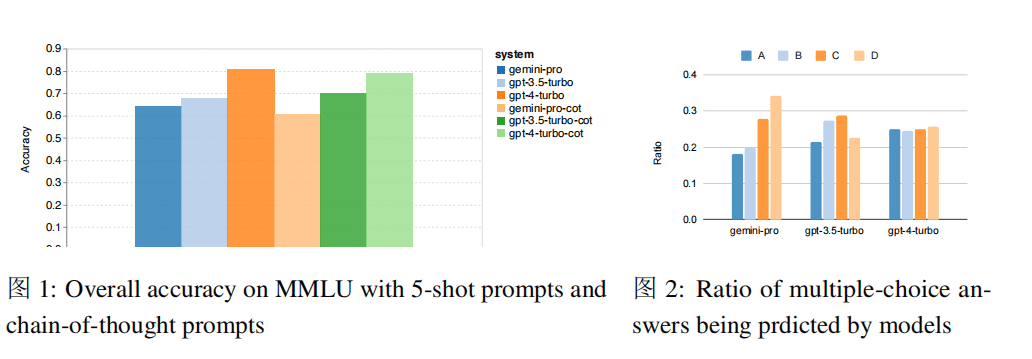
图 2 展示了每个模型选择每个多选题答案的次数比例。Gemini 偏向于选择最后一个答案“D”,而 GPT 模型选项分布更加均衡。这可能表明 Gemini 在解决多选题方面没有经过严格的指导调整,导致模型在答案排序上存在偏见。
此外,作者还深入探讨了 Gemini Pro 在表现最差/表现最好的任务中的情况。如下图所示,Gemini Pro 在多项任务上落后于 GPT3.5,而胜出的两项任务也仅保持着轻微的优势。
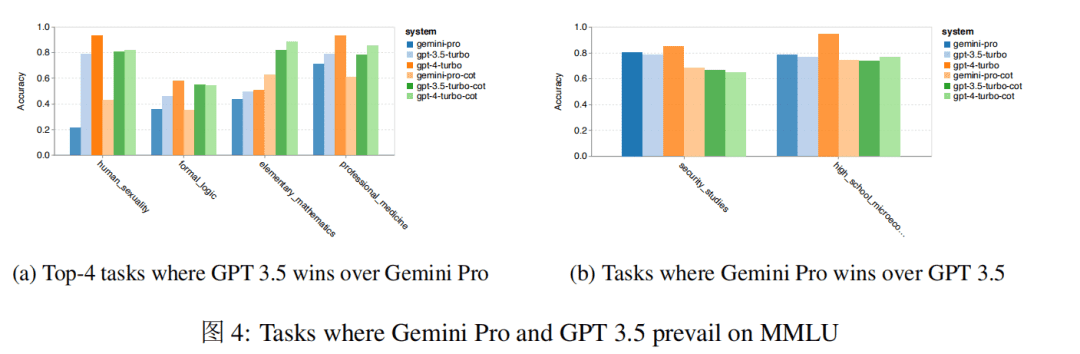
Gemini Pro 在特定任务上的表现不佳,可能是因为其过强的内容过滤机制造成的。在某些情况下,Gemini 无法返回答案,特别是在涉及到潜在非法或敏感材料的情况下。在大多数 MMLU 子任务中,API 响应率大于 95%,但 Gemini 在 moral_scenarios 中的响应率为 85%,而在 human_sexuality 任务中响应率低至 28%。其次,Gemini Pro 在解决 formal_logic 和 elementary_mathematics 任务所需的基本数学推理方面表现较差。
通用推理
研究人员使用 BIG-Bench Hard 数据集来评估模型的通用推理能力。该数据集包含 27 个不同的推理任务,包括算术推理、符号推理、多语言推理和事实知识理解任务。大多数任务由 250 个问题-答案对组成。
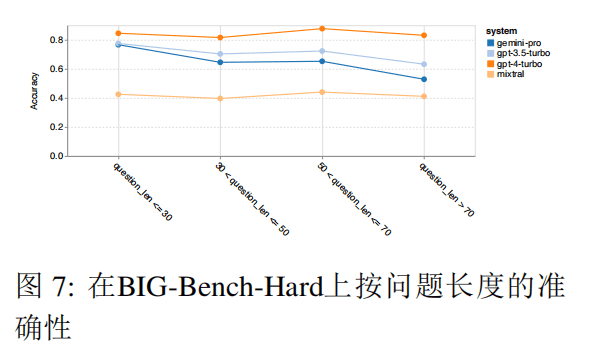
从整体准确率来看,Gemini Pro 的准确率略低于 GPT 3.5 Turbo,远低于 GPT 4 Turbo,而 Mixtral 模型的准确率要低得多。

作者从多个方面分析了 Gemini 表现不佳的原因:
- Gemini Pro 在更长、更复杂的问题上表现不佳,而 GPT 模型则更具鲁棒性。特别是 GPT 4 Turbo,在更长的问题上几乎没有退化,而 Mixtral 不受问题长度影响,但总体准确率较低。
- Gemini Pro 不擅长做物品状态跟踪,比如在“交换物品”任务中,在步骤 2 中物品状态更新错误。

- Gemini 也有优势科目,比如在一些需要世界知识的任务、操作符号堆栈的任务、按字母顺序排序单词的任务以及解析表格的任务等优于 GPT 3.5 Turbo。
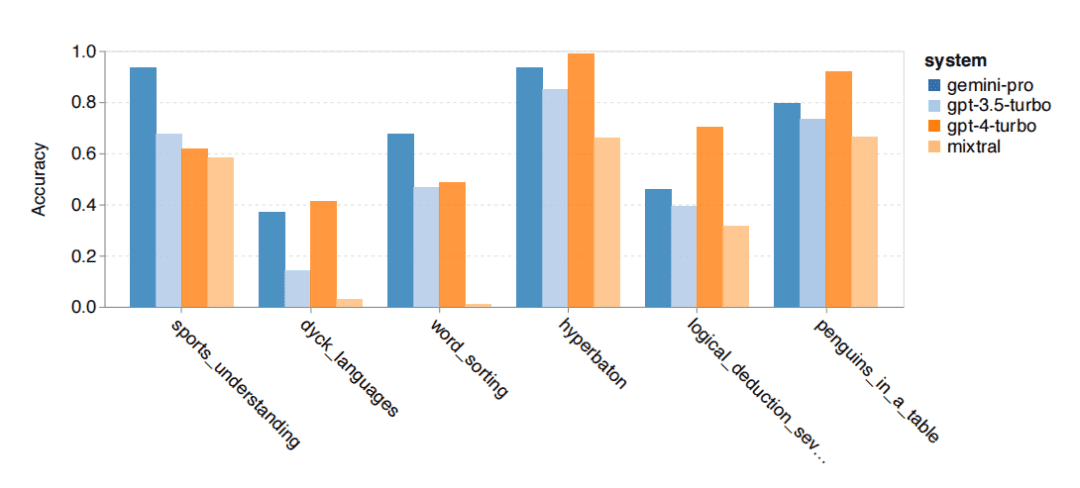
数学推理
在数学推理能力上,从下图中可以发现在四项数学推理数据集中,Gemini Pro 的准确率略低于 GPT 3.5 Turbo。
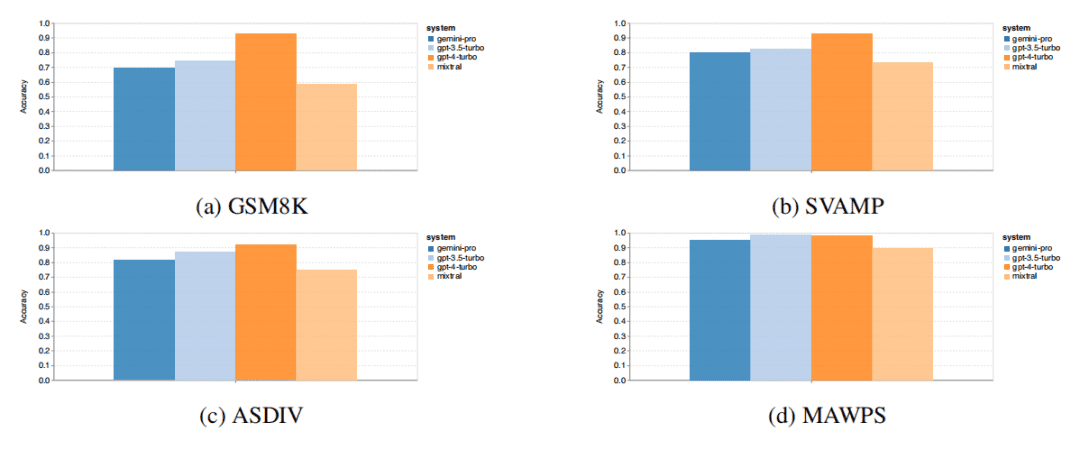
作者比较了模型在生成不同位数答案时的准确性,包括一位、两位、三位数。结果表明,GPT 3.5 Turbo 在多位数数学问题上似乎更具鲁棒性,而 Gemini Pro 的性能有所下降。

代码生成
作者使用两个代码生成数据集 HumanEval 和 ODEX 来测试模型的编码能力。
从下图中可以看到 Gemini Pro 在两个任务上的性能低于 GPT 3.5 Turbo,并远低于 GPT 4 Turbo,Gemini 的代码生成能力仍有改进的空间。

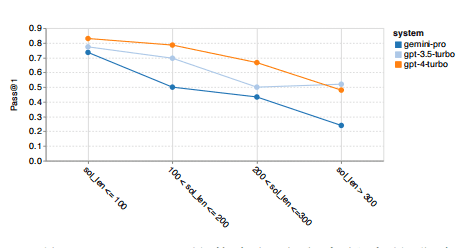
其次,作者分析了黄金解长度与模型性能之间的关系。解长度在一定程度上可以代表任务的难度,越长的任务越难。在解长度小于 100(较简单的案例)时,Gemini Pro 能够与 GPT 3.5 达到相当的水平,但当解变得更长时,它却大幅落后。
另外,作者还发现在使用诸如 mock、pandas、numpy、datetime 的库时,Gemini Pro 的表现不如 GPT 3.5,而在 matplotlib 案例中,它的表现超过了 GPT 3.5 和 GPT 4,表明在通过代码进行绘图可视化时具有更强的能力。

机器翻译
作者使用 FLORES-200 机器翻译基准测试,将任务范围限定为仅从英语翻译为其他语言。还增加了开源机器翻译模型 NLLB-MoE 和谷歌翻译作对比。
下图分别是在 zero-shot 和 5-shot 的比较结果:
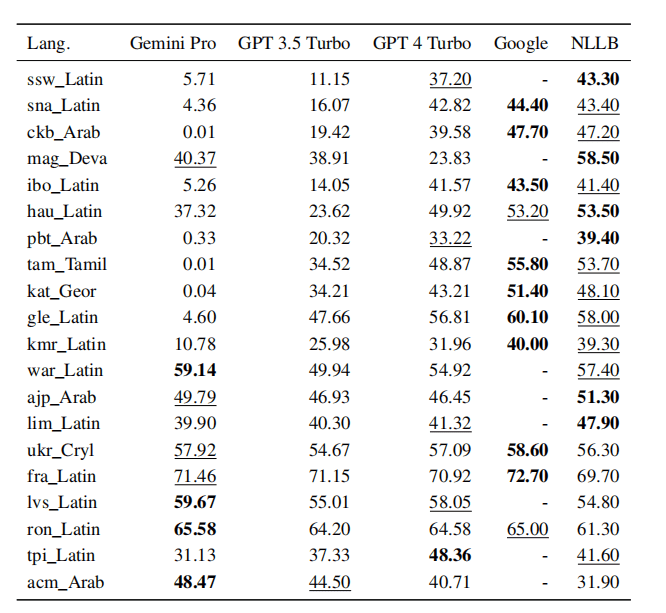
▲zero-shot
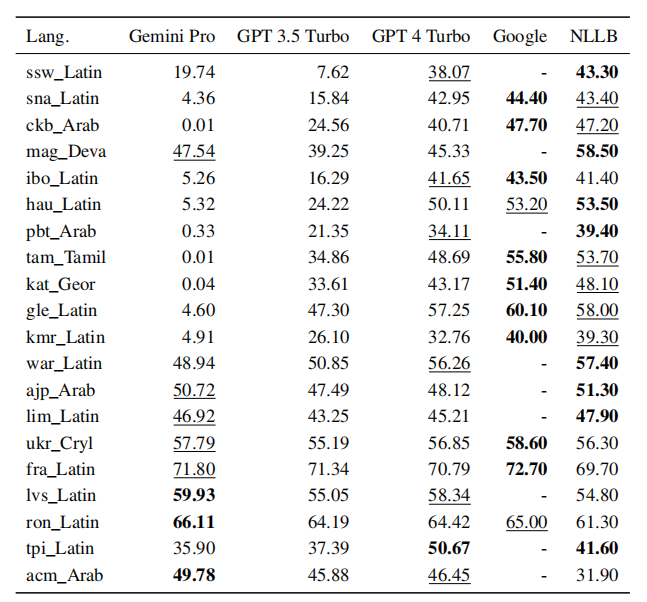
▲5-shot
结果显示,专有的机器翻译系统强于常规的语言模型。在语言模型中,GPT 4 Turbo 仍然是最强大的,即使在低资源语言中也可与专有的机器翻译系统一较高下。而 Gemini Pro 在 8 种语言上优于 GPT 3.5 Turbo 和 GPT 4 Turbo,并在 4 种语言上表现出最佳性能。
然而,Gemini Pro 在约 10 种语言对中呈现出强烈的阻塞回应倾向,即在置信度较低的情况下生成了“Blocked Response”错误,造成最终得分不理想。
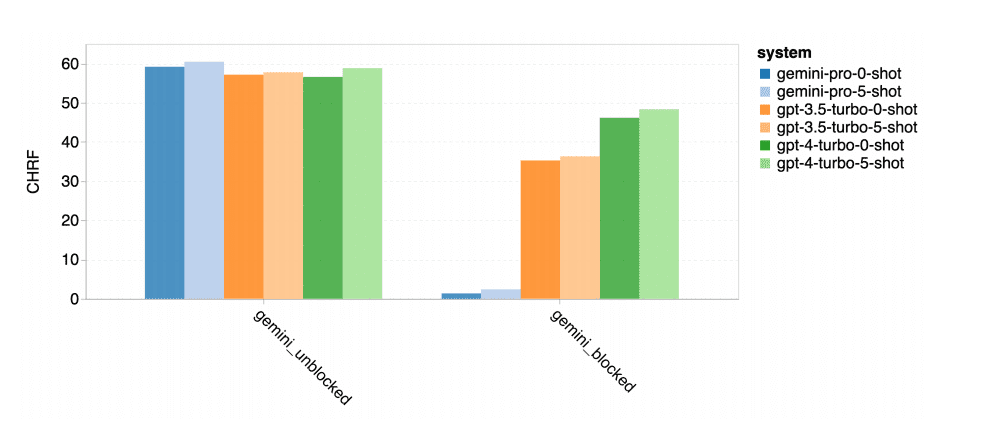
▲在阻塞和非阻塞样本上性能
网络导航代理
网络导航代理任务是一个需要长期规划和复杂数据理解的任务。作者使用了基于执行的模拟环境 WebArena,给予代理的任务包括信息搜索、站点导航以及内容和配置操作。作者使用带有 UA 提示的 CoT 提示和不带 UA 提示的 CoT 提示进行测试。所谓带有 UA 提示就是告诉模型在任务无法完成时终止执行。
总体来看,Gemini-Pro 的表现与 GPT-3.5-Turbo 相比稍微逊色一些。与 GPT-3.5-Turbo 类似,在 UA 提示的情况下,Gemini Pro 的表现更好,达到了 7.09% 的成功率。

网络导航代理任务包含了各种网站,可以看到在 gitlab 和 map 上,Gemini-Pro 的表现不如 GPT-3.5-Turbo,而在 shopping admin、reddit 和 shopping 网站上与 GPT-3.5-Turbo 接近。另外,在多网站任务上,Gemini-Pro 表现优于 GPT-3.5-Turbo,这说明 Gemini 在各种基准测试中在更复杂的子任务表现更好。

Gemini-Pro 更倾向于将更多任务预测为不可实现,尤其是在给出 UA 提示的情况下。给出 UA 提示时,Gemini-Pro 将 80.6% 的任务预测为不可实现,而 GPT-3.5-Turbo 则为 47.7%。但实际上数据集中只有 4.4% 的任务是不可实现的,因此两者都过高地预测了实际不可实现的任务数量。
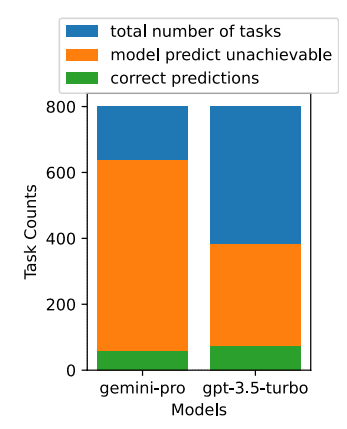
另外,Gemini Pro 更倾向于使用较短的短语回应,并在采取较少的步骤得到结论。如下图所示, Gemini Pro 的超过一半轨迹在十个步骤以下, 而 GPT 3.5 Turbo 和 GPT 4 Turbo 的轨迹大多在 10 到 30 个步骤之间。同样,Gemini 的大部分回应长度不超过 100 个字符,而 GPT 3.5 Turbo、GPT 4 Turbo 和 Mixtral 的回应长度大多超过 300 个字符。
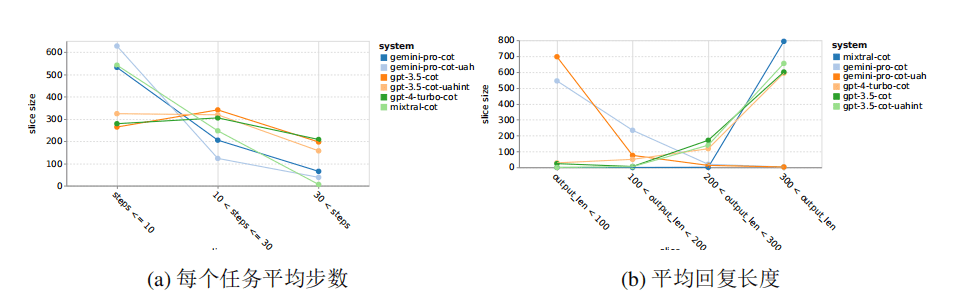
结论
通过以上多个任务的比拼,可以总结出以下几点:
- Gemini Pro 在模型大小和类型上与 GPT 3.5 Turbo 相当,但在某些任务上的表现略逊于 GPT 3.5 Turbo。
- Gemini Pro 相比其他模型存在一些短板,比如在多项选择题中存在回答顺序的偏见、推理步骤较短、由于内容过滤机制严格导致的响应失败等问题。
- 当然,Gemini Pro 也有其优势:在特别长而复杂的推理任务上,Gemini 的表现更佳,且在未经筛选的多语种任务上也表现出出色的能力,而 GPT 3.5 Turbo 则稍逊一筹。
值得注意的是,以上结论截至到 2023 年 12 月 19 日,并且依赖于作者选择的具体提示和生成参数。随着模型和系统的升级,结果随时可能发生变化。另外,Gemini 是一个多模态模型,但本文只关注 Gemini 在语言理解、生成和翻译能力上的表现,其多模态能力还有待深入探索。
目前,Gemini 只发布了 Pro 版本。让我们共同期待能够与 GPT 4 一较高下的 Gemini Ultra 版本的发布。








