
Mini-Gemini:多模态视觉语言模型的潜力挖掘
香港中文大学和SmartMore的研究团队联合推出了Mini-Gemini模型,旨在探索视觉语言模型(VLM)在计算成本可接受范围内的潜力。该研究的核心在于如何高效地利用高分辨率图像,优化数据质量,并扩展应用范围,从而推动VLM在学术环境中的发展。
问题背景
随着视觉语言模型的发展,研究人员发现通过增加图像分辨率可以显著提升模型性能。更高分辨率的图像意味着更多的视觉标记,从而丰富语言模型中的视觉嵌入。然而,这种提升伴随着计算成本的急剧增加,尤其是在处理多张图像时。此外,现有数据的质量、模型的能力和应用范围仍存在不足,阻碍了训练和开发过程的加速。因此,如何在保证成本效益的前提下,推动VLM达到成熟水平,成为了一个关键问题。
Mini-Gemini模型详解
为了解决上述问题,Mini-Gemini从三个关键方面入手:高效的高分辨率解决方案、高质量的数据以及扩展的程序。
1. 双视觉编码器
Mini-Gemini的核心框架是采用双视觉编码器。这种架构同时处理低分辨率(LR)和高分辨率(HR)的视觉嵌入。低分辨率图像通过双线性插值从高分辨率图像生成。这种方法旨在结合全局上下文信息与精细的局部细节。
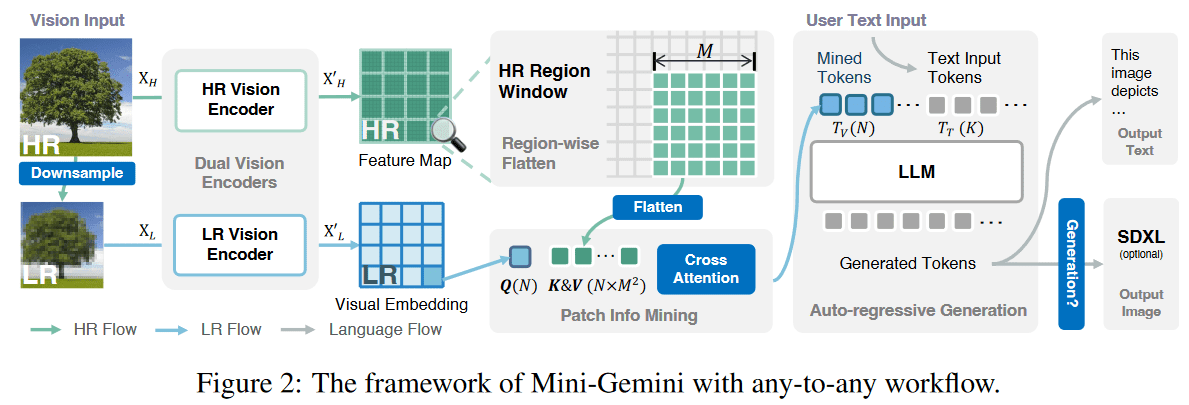
具体来说,对于低分辨率图像,研究团队采用了CLIP ViT模型,以保留视觉块之间的长程关系,便于后续在大型语言模型(LLM)中进行交互。对于高分辨率图像,则使用基于卷积神经网络(CNN)的编码器,实现自适应且高效的高分辨率图像处理。研究团队选择了在LAION数据集上预训练的ConvNeXt模型作为高分辨率视觉编码器。通过将不同卷积阶段的特征进行上采样并拼接,最终获得1/4输入尺寸的高分辨率特征图。
2. Patch信息挖掘
为了在提高效率的同时,维持LLM中视觉标记的数量,Mini-Gemini引入了Patch信息挖掘机制。该机制以低分辨率视觉嵌入作为查询(Query),高分辨率视觉嵌入作为键(Key)和值(Value),从高分辨率视觉嵌入中检索相关视觉线索。简而言之,低分辨率块与高分辨率图像中对应的子区域相关联,包含多个像素级特征。
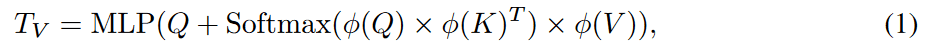
其中,$\varphi$ 和 MLP 分别代表一个投影层(projection layer)和一个多层感知机(multi-layer perceptron)。
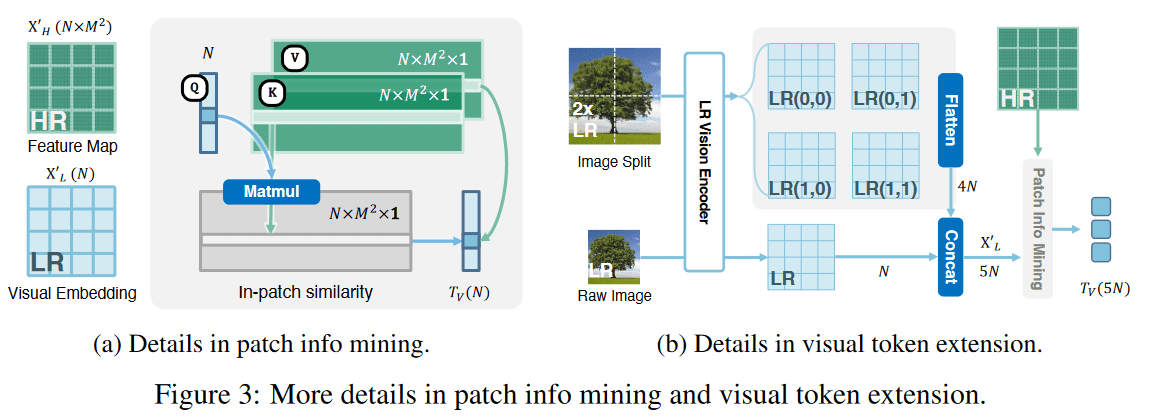
通过这个过程,模型能够合成和细化视觉线索,生成增强的视觉标记 $T_v$,用于后续的LLM处理。这种设计确保了每个查询的挖掘仅限于高分辨率图像中具有 $M^2$ 个特征的相应子区域,从而保持了效率。这种方法允许在不显著增加视觉标记数量的前提下提取高分辨率细节,实现了细节丰富度和计算可行性之间的平衡。
此外,Mini-Gemini还支持视觉令牌扩展。通过将原始图像与其放大两倍的版本合并,可以生成批量输入 $X_L \in R^{5 \times H' \times W' \times 3}$。然后,使用低分辨率视觉编码器对这些图像进行编码,得到视觉嵌入 $X'_L \in R^{5 \times N \times C}$。
3. 文本和图像生成
通过Patch信息挖掘得到的视觉标记 $T_v$ 和输入文本标记 $T_t$ 被拼接在一起,作为LLM的输入,用于自回归生成。Mini-Gemini支持纯文本和文本图像生成作为输入和输出,实现了任意到任意的推理。该模型可以将用户指令转化为高质量的prompt,从而在潜在扩散模型中生成上下文相关的图像。这种方法与DALLE 3和SORA等高质量图像生成框架类似,它们利用VLM的生成和理解能力来获取更高质量的文本条件。
Text-image Instructions(文本图像指令)
为了更好地进行跨模态对齐和指令微调,研究团队从公开来源收集了高质量的数据集。具体来说,对于跨模态对齐,他们利用了来自LLaVA过滤的CC3M数据集中的558K图像标题对,以及来自ALLaVA数据集的695K采样的GPT-4V response caption。至于指令微调,他们从LLaVA数据集中采样了643K单轮和多轮对话(不包括21K TextCaps数据),从ShareGPT4V中采样了100K QA对,从ShareGPT4V中采样了10K LAION-GPT-4V字幕,来自ALLaVA数据集的700K GPT-4V响应指令对,以及来自LIMA和OpenAssistant2的6K纯文本多轮对话。为了增强OCR相关能力,研究团队进一步收集了28K QA对,其中包括10K DocVQA、4K ChartQA、10K DVQA和4K AI2D数据。总的来说,用于图像理解的数据集包含了大约1.5M的指令相关对话。此外,还收集了13K对用于图像相关的生成。
Generation-related Instructions(生成相关指令)
为了支持图像生成,研究团队使用GPT-4 Turbo进一步构建了13K指令数据集。训练数据包含两个任务:(a)简单指令重述:采用LAION-GPT-4V中的8K描述性图像标题,让GPT-4逆向推断相应用户的短输入和稳定扩散(SD)域中的目标标题。(b) 上下文提示生成:基于LIMA和OpenAssistant2中的一些高质量的真实对话上下文,生成提示,生成适合对话上下文的图像,总共带来5K条指令。对于这两种数据,在每次对GPT-4的query中,从GigaSheet中随机采样5个高质量SD文本到图像提示作为上下文示例,以获得生成的目标提示。格式化数据以使用

实验结果与分析
1. 实验细节
为了高效训练,研究团队固定了两个视觉编码器,并仅优化Patch信息挖掘模块中的投影层。同时,仅在指令调优阶段对LLM进行优化。他们使用了AdamW优化器和余弦学习计划,优化1 epoch的所有模型。在大多数情况下,模态对齐和指令调整的初始学习率分别设置为1e-3和2e-5,对于Mixtral-8×7B和Hermes-2-Yi-34B,调整率为1e-5,以确保指令调优的稳定性。该框架在标准机器配置的8个A800 GPU上进行训练。对于最大的模型Hermes-2-Yi-34B,利用4台机器,使用DeepSpeed Zero3策略在2天内完成优化。对于HD版本,由于LLM视觉令牌的扩展,总成本增加到大约4天。
2. 主要结果
Normal Resolution(普通分辨率)
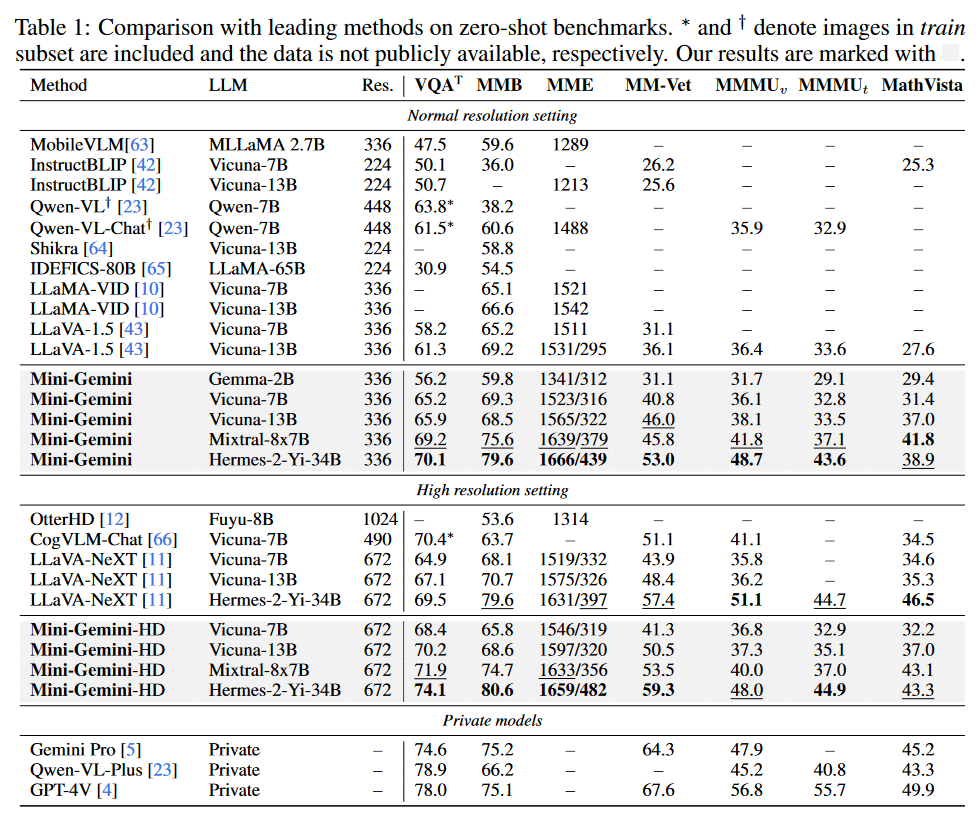
Mini-Gemini在多种设置(包括普通分辨率和高分辨率)下与之前的领先方法进行了比较,并且还考虑了私有模型。在普通分辨率下,Mini-Gemini在各种LLM中始终优于现有模型。
High Resolution(高分辨率)
为了验证扩展视觉标记的框架,研究团队对表1中LR视觉编码器的输入大小为672,HR视觉编码器的输入大小为1536进行了实验。尽管分辨率提高了,LLM处理的视觉标记的有效数量仍然与LR输入大小672保持一致,确保了计算效率。这种方法的好处在注重细节的任务中尤其明显。
3. 组件分析
Patch Info Mining(Patch信息挖掘)
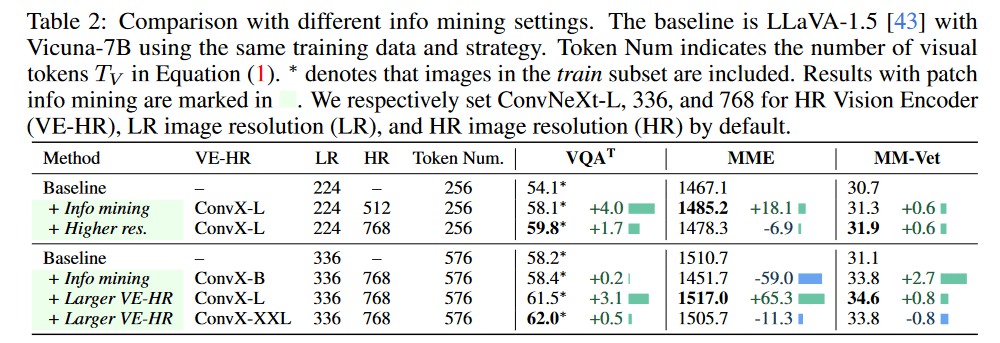
通过集成ConvNeXt-L作为HR图像的视觉编码器,Mini-Gemini获得了显著的性能提升。
Vision Encoder(视觉编码器)
为了评估视觉编码器的影响,研究团队对比了ConvNeXt-B和ConvNeXt-XXL。虽然使用ConvNeXt-B在TextVQA和MM-Vet中表现更好,但ConvNeXt-L始终提供最佳结果,尤其是在MME和MM-Vet数据集中,表明其在处理详细视觉信息方面具有卓越的平衡。因此,考虑到有效性和计算效率之间的平衡,研究团队选择了ConvNeXt-L作为默认的HR视觉编码器。
High-quality Data(高质量数据)
高质量的数据对于提升LLM和VLM能力至关重要。
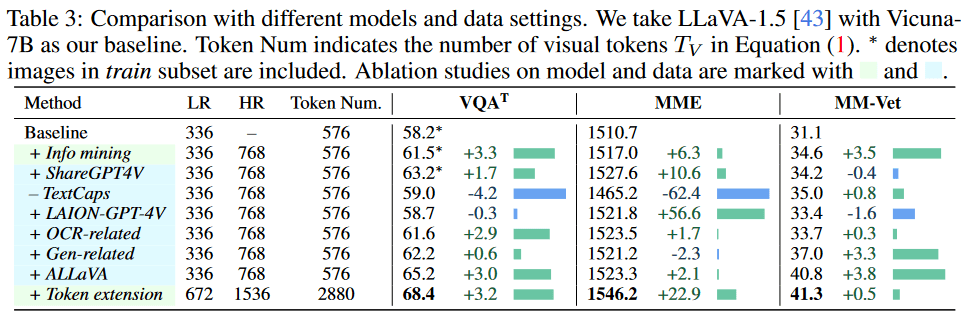
Visual Token Extension(视觉令牌扩展)
扩展的视觉标记可以在不同的输入分辨率下推广其实用性。当增加LR和HR输入分辨率时,模型在所有基准测试中都取得了显著的增益。分辨率的提高显著减少了幻视,从而使图像理解更加准确和可靠。一般来说,随着视觉令牌数量的增加,Mini-Gemini可以扩展到更好的能力。
4. 定性结果
Visual Understanding(视觉理解)
为了确定Mini-Gemini在现实环境中的视觉理解能力,研究团队将其应用于各种理解和推理任务。得益于补丁信息挖掘和高质量的数据,Mini-Gemini可以很好地解决多种复杂情况。

Image Generation(图像生成)
研究团队对Mini-Gemini的生成能力进行了全面评估。与最近的研究(例如AnyGPT和ChatIllusion)相比,更强的多模态理解能力使模型能够生成与给定指令更好地对齐的文本到图像标题,从而产生更适合上下文的图像文本答案。如图6所示,它能够熟练地基于多模式人类指令和纯文本训练数据生成高质量内容。这一能力凸显了Mini-Gemini强大的图像文本对齐和语义解释能力,这些能力在推理阶段有效发挥作用。利用LLM强大的推理能力,可以在单轮或多轮对话中产生合理的图文输出。

结论与讨论
Mini-Gemini模型在视觉语言理解和生成方面展现了巨大的潜力,但仍有很大的潜力需要进一步挖掘。对于视觉理解而言,计数能力和复杂的视觉推理能力还远不能令人满意。这可能是由于缺乏相应的训练数据,特别是在预训练阶段。同时,对于基于推理的生成,在这项工作中使用文本来桥接VLM和扩散模型,因为没有发现基于嵌入的方法有明显的增益。未来的研究将尝试寻找一种更先进的方式来进行视觉理解、推理和生成。








