
在人工智能领域,模型之间的竞争日趋白热化。OpenAI 的 ChatGPT 系列和 Google 的 Gemini 模型无疑是其中的佼佼者。本文将深入对比这两大模型的各项性能指标,并结合实际案例,探讨它们在不同应用场景下的优劣势。
从综合评分来看,在特定时间段内(例如 2023 年 12 月 22 日之前),Gemini 模型曾占据领先地位,而 OpenAI 的 ChatGPT-4o 紧随其后,总体比分略逊一筹。然而,AI 模型的迭代速度极快,排名随时可能发生变化。
ChatGPT 会员升级指南
提示:笔者在使用过程中,ChatGPT 和 Claude 是主力。需要升级 ChatGPT Plus/Pro 会员的朋友,可以参考 ChatGPT 订阅升级教程。
模型的稳定性至关重要,直接影响到用户体验和应用效果。
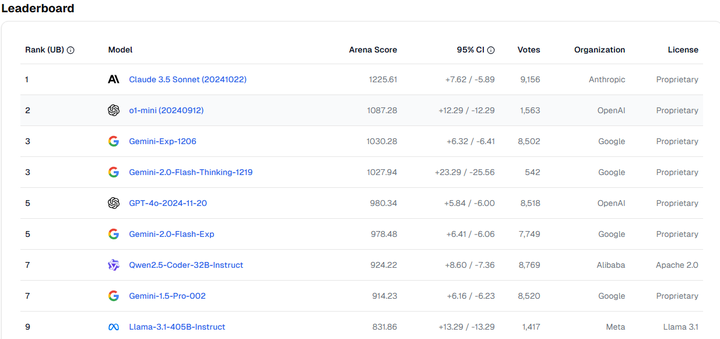
图标说明:模型强度的置信区间(Confidence Interval, CI)指的是模型评分的统计范围,用于表明在重复测评中,模型真实表现可能落在哪个区间。
具体来说:上下限范围:置信区间通常以“±某值”表示,比如95%置信区间为+5.84 / -6.00,表示实际分数有95%的概率落在这个范围内。
用途:它反映了模型评分的稳定性。如果置信区间较窄,说明评分更稳定、误差更小;较宽则表明可能存在更大变动。
从置信区间来看,ChatGPT-4o 的稳定性略优于 Gemini。置信区间越窄,代表模型的输出结果越稳定,可靠性越高。这意味着在多次测试中,ChatGPT-4o 的表现更加一致,不易出现大幅波动。
除了稳定性,模型之间的胜率也是一个关键指标。
数据显示,Gemini 在与其他模型的对比中胜率最高,ChatGPT-4o 紧随其后。胜率反映了模型在特定任务或数据集上的综合表现,是评估模型竞争力的重要参考。
Web 能力是衡量 AI 模型实用性的重要指标之一。一个优秀的 AI 模型应该具备强大的网络信息检索和整合能力,能够为用户提供准确、全面的信息。
为了更直观地对比 Gemini 和 Claude 模型的 Web 能力,我们在竞技场中进行了一次实测。
Gemini 的测试结果如下:
从结果来看,Gemini 在信息提取方面存在一些问题,例如界面中出现了不必要的括号,影响了用户体验。这表明 Gemini 在处理网页内容时,可能存在解析错误或信息提取不完整的情况。
再来看看 Claude Haiku 的表现:
Claude Haiku 的结果相对较好,信息呈现清晰、完整。虽然 Claude 在思考时间上略长于 Gemini,但考虑到 Gemini 不尽人意的结果,Claude 的表现仍然更胜一筹。对于需要高质量输出的应用场景,稍长的等待时间是可以接受的。
总的来说,Claude 在 Web 能力方面表现更佳,能够提供更准确、更可靠的信息。然而,AI 模型的性能受多种因素影响,例如任务类型、数据集、提示词等等。在实际应用中,我们需要根据具体需求选择合适的模型。
案例分析:AI 模型在原型设计中的应用
近年来,AI 模型在原型设计领域的应用越来越广泛。设计师可以利用 AI 模型快速生成设计稿、评估用户体验、优化设计方案,从而提高设计效率和质量。Gemini 和 Claude 等模型都具备一定的原型设计能力,可以帮助设计师快速搭建产品原型。
例如,设计师可以利用 AI 模型生成用户界面草图、创建交互动画、模拟用户行为。AI 模型还可以根据用户反馈自动调整设计方案,从而实现个性化定制。此外,AI 模型还可以帮助设计师发现潜在的设计缺陷,提高产品的可用性和易用性。
未来展望:AI 模型的持续演进
随着人工智能技术的不断发展,AI 模型的性能将持续提升,应用场景也将越来越广泛。未来,AI 模型将在更多领域发挥重要作用,例如智能客服、自动驾驶、医疗诊断等等。我们可以期待,AI 模型将为人类社会带来更大的便利和福祉。
当然,AI 技术的发展也面临着一些挑战,例如数据安全、算法偏见、伦理道德等等。我们需要加强对 AI 技术的监管和引导,确保其健康、可持续发展。只有这样,我们才能充分利用 AI 技术的优势,避免潜在的风险。
总而言之,OpenAI 的 ChatGPT 系列和 Google 的 Gemini 模型都是优秀的 AI 产品,它们在不同方面展现出了强大的能力。在实际应用中,我们需要根据具体需求选择合适的模型,并不断探索 AI 技术的更多可能性。








