
近年来,大型语言模型(LLMs)在文本生成和理解方面取得了显著进展,但它们在处理视觉信息方面存在局限性。为了弥补这一缺陷,阿里巴巴推出了Qwen-VL系列,这是一种大规模的视觉语言模型(LVLMs),旨在提升计算机对图像和文本的综合理解和生成能力。本文将深入探讨Qwen-VL的技术架构、训练方法及其在多模态任务中的卓越表现。
Qwen-VL:技术架构与核心特性
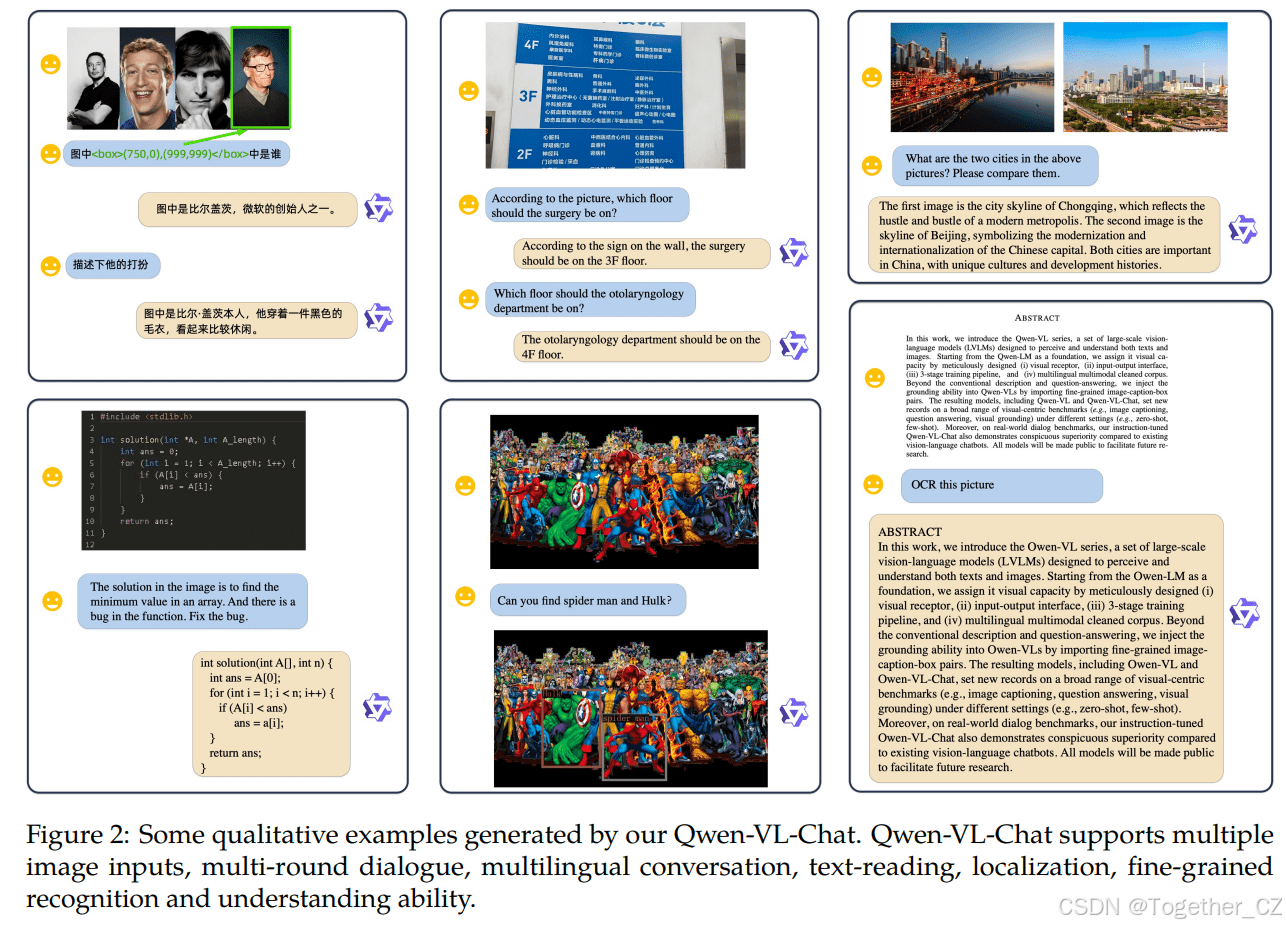
Qwen-VL系列模型以Qwen-LM为基础,通过引入视觉接收器、输入输出接口、三阶段训练管道和多语言多模态清洗语料库,赋予了其强大的视觉能力。该系列模型包括Qwen-VL和Qwen-VL-Chat,它们在图像描述、问答和视觉定位等视觉中心基准测试中均表现出色,并在实际对话基准测试中超越了现有的视觉语言聊天机器人。
模型架构:融合语言与视觉
Qwen-VL的整体网络架构由三个关键组件构成:大型语言模型、视觉编码器和位置感知的视觉语言适配器。
- 大型语言模型:Qwen-VL以Qwen-7B的预训练权重为基础,构建其语言理解和生成能力。
- 视觉编码器:采用Vision Transformer(ViT)架构,并从Openclip的ViT-bigG的预训练权重进行初始化。该编码器将输入图像分割成块,生成图像特征。

- 位置感知的视觉语言适配器:该适配器包含一个单层交叉注意力模块,用于压缩图像特征,并纳入二维绝对位置编码,以减轻压缩过程中潜在的位置细节损失。压缩后的图像特征序列随后被输入到大型语言模型中。
输入与输出:多模态信息的处理
Qwen-VL能够处理图像和边界框信息,并生成相应的文本描述。为了区分不同类型的输入,模型使用了特殊的标记。
- 图像输入:图像通过视觉编码器和适配器处理后,生成固定长度的图像特征序列,并使用特殊标记和进行区分。
- 边界框输入和输出:为了增强模型对细粒度视觉理解和定位的能力,Qwen-VL的训练涉及区域描述、问题和检测形式的数据。边界框被转换为特定字符串格式,并使用特殊标记和进行区分。边界框引用的内容则使用另一组特殊标记和进行标记。
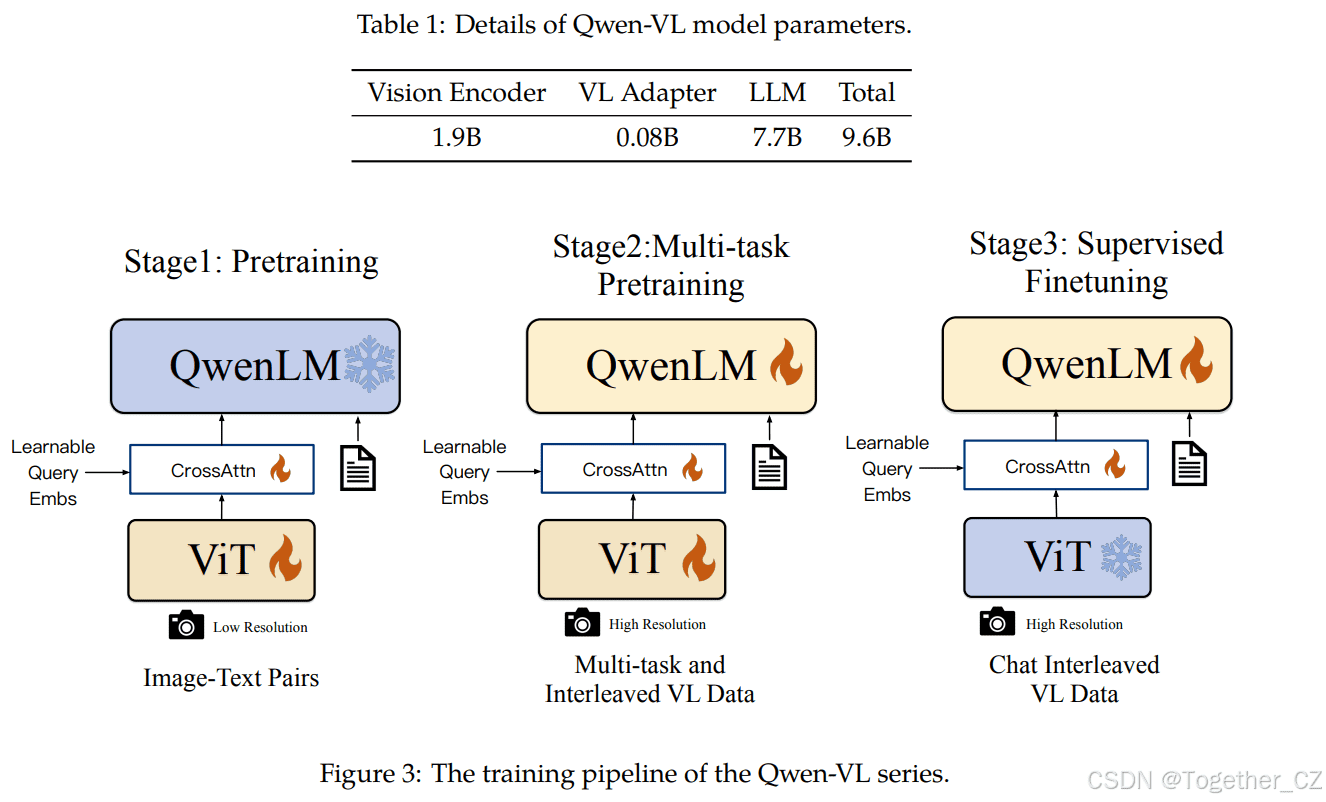
三阶段训练:逐步提升模型性能
Qwen-VL的训练过程包括三个阶段:第一阶段预训练、第二阶段多任务预训练和最终的指令微调训练阶段。
第一阶段预训练:大规模弱标记数据学习
该阶段主要利用大规模、弱标记的网络爬取的图像文本对数据集。数据集包含总共14亿个图像文本对,其中77.3%是英语数据,22.7%是中文数据。在该阶段,大型语言模型被冻结,仅优化视觉编码器和视觉语言适配器。
第二阶段多任务预训练:高质量细粒度数据注入
该阶段引入了高质量和细粒度的视觉语言注释数据,输入分辨率更大,图像文本数据交错。Qwen-VL在文本生成、图像描述、视觉问答、定位等七个任务上同时进行训练。在该阶段,大型语言模型被解锁并进行训练。
监督微调:指令跟随与对话能力增强
通过指令微调对Qwen-VL预训练模型进行微调,以增强其指令跟随和对话能力,从而得到交互式的Qwen-VL-Chat模型。多模态指令微调数据主要来自通过LLM自指令生成的描述数据或对话数据,这些数据通常仅涉及单图像对话和推理,并限于图像内容理解。此外,还在训练过程中混合多模态和纯文本对话数据,以确保模型在对话能力上的通用性。
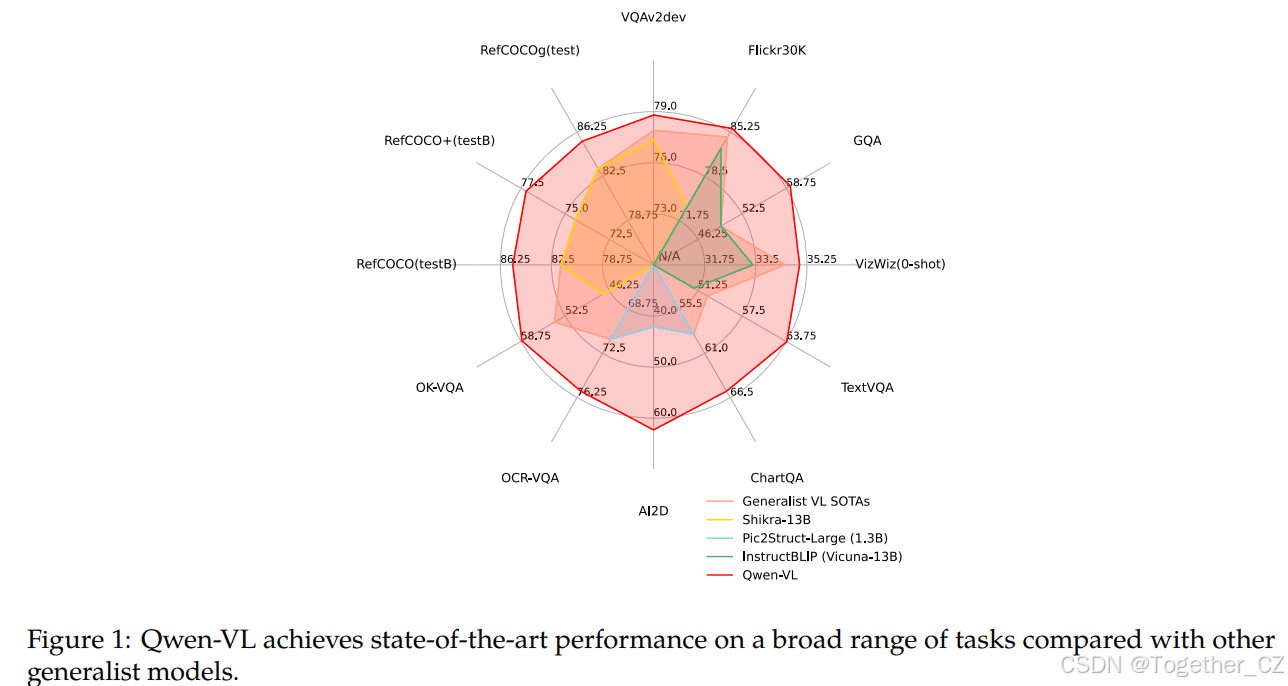
评估结果:多项任务表现卓越
为了全面评估Qwen-VL的视觉理解能力,研究人员在各种多模态任务上进行了评估。
图像描述与一般视觉问答
在图像描述任务中,Qwen-VL在Flickr30K karpathy-test分割上达到了最先进的性能(即85.8 CIDEr分数)。在一般VQA基准测试中,Qwen-VL在VQAv2、OKVQA和GQA基准测试中分别达到了79.5、58.6和59.3的准确率。
面向文本的视觉问答
在TextVQA、DocVQA、ChartQA等基准测试中,Qwen-VL的表现均优于之前的通用模型和最近的LVLMs。
引用表达理解
在RefCOCO、RefCOCOg和GRIT等基准测试中,Qwen-VL均获得了顶级结果,展示了其细粒度图像理解和定位能力。
少样本学习
Qwen-VL在OKVQA、VizWiz、TextVQA和Flickr30k上通过上下文少样本学习取得了更好的性能,与参数数量相似的模型相比,Qwen-VL的性能甚至可以与更大的模型相媲美。
指令跟随
在TouchStone、SEED-Bench和MME等基准测试中,Qwen-VL-Chat均取得了明显的优势,表明其在理解和回答多样化的用户指令方面表现更好。
相关工作:视觉语言模型的发展
近年来,研究人员对视觉语言学习表现出极大的兴趣。CoCa提出了一种编码器-解码器结构,同时解决图像文本检索和视觉语言生成任务。OFA通过定制的任务指令将特定的视觉语言任务转换为序列到序列任务。Unified I/O进一步将更多任务引入统一框架。另一类研究集中在构建视觉语言表示模型,CLIP利用对比学习和大量数据在语义空间中对齐图像和语言,BEIT-3采用混合专家结构和统一的掩码标记预测目标,在各种视觉语言任务上取得了最先进的结果。ImageBind和ONE-PEACE还将更多模态对齐到统一的语义空间中,从而创建了更通用的表示模型。
随着大型语言模型的发展,研究人员开始基于LLMs构建更强大的大型视觉语言模型,BLIP-2提出了Q-Former,以对齐冻结的视觉基础模型和LLMs。同时,LLaVA和MiniGPT4引入了视觉指令微调,以增强LVLMs的指令跟随能力。mPLUG-DocOwl通过引入数字文档数据,将文档理解能力纳入LVLMs。Kosmos-2、Shikra和BuboGPT进一步增强了LVLMs的视觉定位能力。Qwen-VL集成了图像描述、视觉问答、OCR、文档理解和视觉定位能力,并在这些多样化的任务上表现出色。
未来展望:多模态融合与能力拓展
Qwen-VL系列作为一种大规模多语言视觉语言模型,为多模态研究提供了有力的支持。未来,Qwen-VL将在以下几个关键维度上进一步增强:
- 多模态集成:将Qwen-VL与语音和视频等更多模态集成。
- 能力增强:通过扩大模型规模、训练数据和更高分辨率来增强Qwen-VL,使其能够处理多模态数据中更复杂和精细的关系。
- 生成能力扩展:扩展Qwen-VL在多模态生成方面的能力,特别是在生成高保真图像和流畅语音方面。
附录:数据集与训练细节
附录部分详细介绍了Qwen-VL所使用的数据集、训练数据格式、超参数设置以及评估基准等信息。这些细节对于理解Qwen-VL的性能和复现实验结果至关重要。
数据集详细信息
包括图像文本对、VQA数据集、定位数据集和OCR数据集的详细描述和预处理方法。
训练数据格式
可视化了多任务预训练的数据格式和监督微调的数据格式。
超参数
报告了Qwen-VL的详细训练超参数设置。
评估基准
提供了所用评估基准的详细总结和相应指标。
通过以上分析,我们可以看到Qwen-VL在多模态学习领域取得了显著进展,为未来的研究和应用奠定了坚实的基础。随着技术的不断发展,我们有理由相信,Qwen-VL将在更多领域发挥重要作用,推动人工智能技术的进步。








