
在人工智能领域,模型迭代的步伐从未停歇。Qwen2.5的发布,无疑为开源社区注入了新的活力。作为Qwen家族的最新成员,Qwen2.5不仅在规模上实现了突破,更在智能和知识储备上进行了全面升级。此次发布堪称开源历史上规模最大的一次,涵盖了语言模型Qwen2.5,以及专注于编程的Qwen2.5-Coder和数学的Qwen2.5-Math模型,为开发者们提供了丰富的选择。这些模型均为稠密的decoder-only语言模型,规模各异,满足不同应用场景的需求。
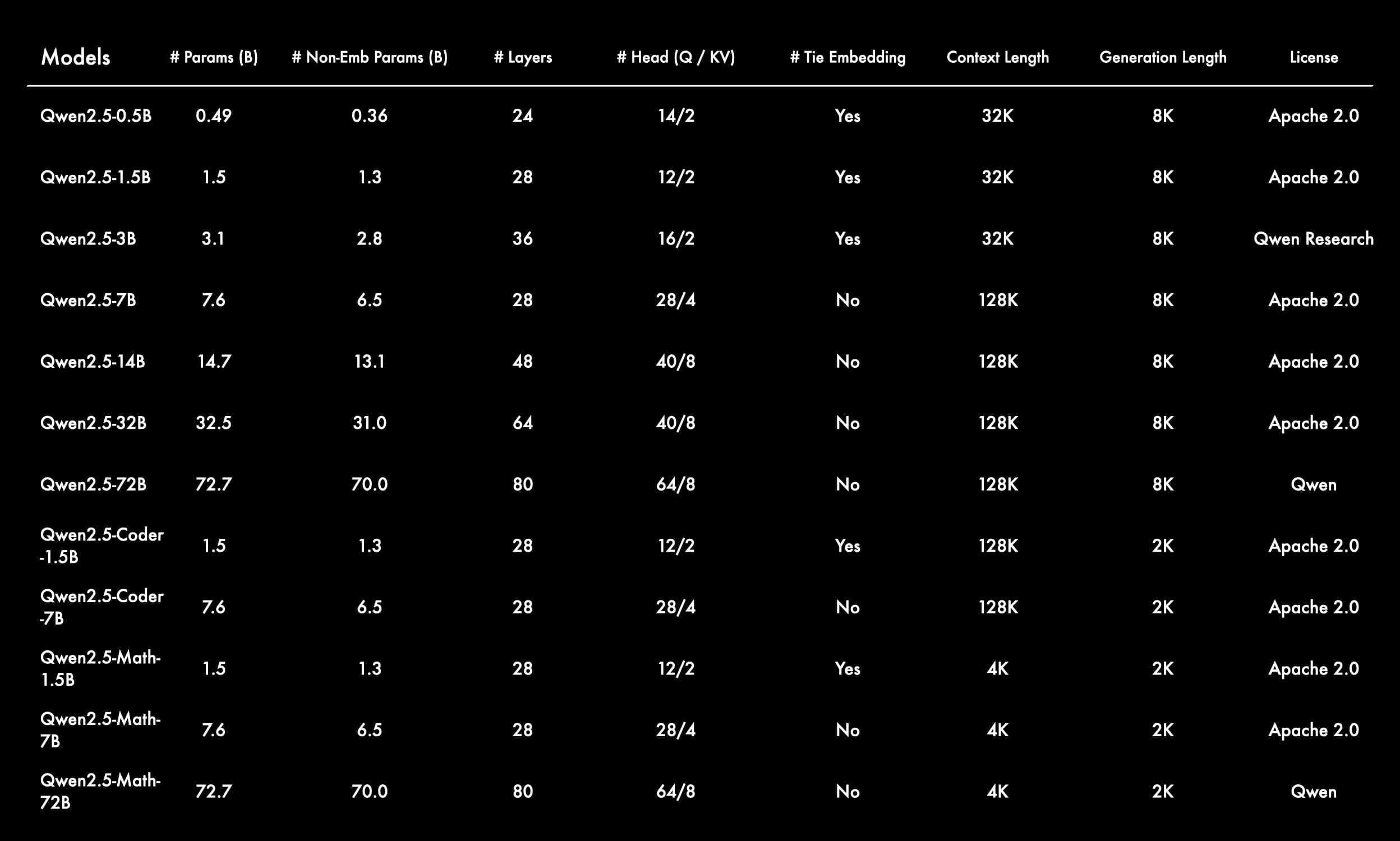
Qwen2.5系列提供了多种尺寸的模型,包括0.5B、1.5B、3B、7B、14B、32B以及72B等版本。而Qwen2.5-Coder则有1.5B、7B以及即将推出的32B版本。Qwen2.5-Math则包含1.5B、7B和72B版本。除了3B和72B版本外,所有开源模型均采用Apache 2.0许可证,确保了使用的自由度和灵活性。此外,阿里云Model Studio还提供了旗舰语言模型Qwen-Plus和Qwen-Turbo的API,为开发者提供了更多选择。

Qwen2.5在多个方面都取得了显著的进步。首先,所有模型都基于最新的大规模数据集进行预训练,该数据集包含高达18万亿的tokens。这使得Qwen2.5在知识储备上远超Qwen2,MMLU(Massive Multitask Language Understanding)评估结果超过85分。其次,Qwen2.5在编程和数学能力方面也取得了显著提升,HumanEval评估结果超过85分,MATH评估结果超过80分。此外,新模型在指令执行、生成长文本、理解结构化数据以及生成结构化输出(尤其是JSON格式)等方面也得到了显著改进。Qwen2.5模型对各种系统提示的适应性更强,从而增强了角色扮演和聊天机器人的条件设置功能。与Qwen2类似,Qwen2.5语言模型支持高达128K的tokens,并能生成最多8K的tokens内容。它们同样保持了对包括中文、英文、法文、西班牙文、葡萄牙文、德文、意大利文、俄文、日文、韩文、越南文、泰文、阿拉伯文等29种以上语言的支持。
专业领域的专家语言模型,即用于编程的Qwen2.5-Coder和用于数学的Qwen2.5-Math,相比其前身CodeQwen1.5和Qwen2-Math有了实质性的改进。具体来说,Qwen2.5-Coder在包含5.5万亿tokens编程相关数据上进行了训练,使得即使较小的编程专用模型也能在编程评估基准测试中表现出媲美大型语言模型的竞争力。同时,Qwen2.5-Math支持中文和英文,并整合了多种推理方法,包括CoT(Chain of Thought)、PoT(Program of Thought)和TIR(Tool-Integrated Reasoning)。
除了开源模型之外,阿里云还通过API服务提供了更多的模型。用户可以通过阿里云百炼平台获取更多详情,包括定价信息。这些API模型针对不同的应用场景进行了优化,允许用户选择最适合特定需求的模型。无论需要顶级性能、快速响应时间,还是两者之间的平衡,API服务都能满足需求。阿里云百炼平台已经兼容 OpenAI 接口规范。使用通义千问 API 来调用:
from openai import OpenAI
import os
client = OpenAI(
api_key=os.getenv("YOUR_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model="qwen-plus-latest",
messages=[
{'role': 'user', 'content': 'Tell me something about large language models.'}
]
)
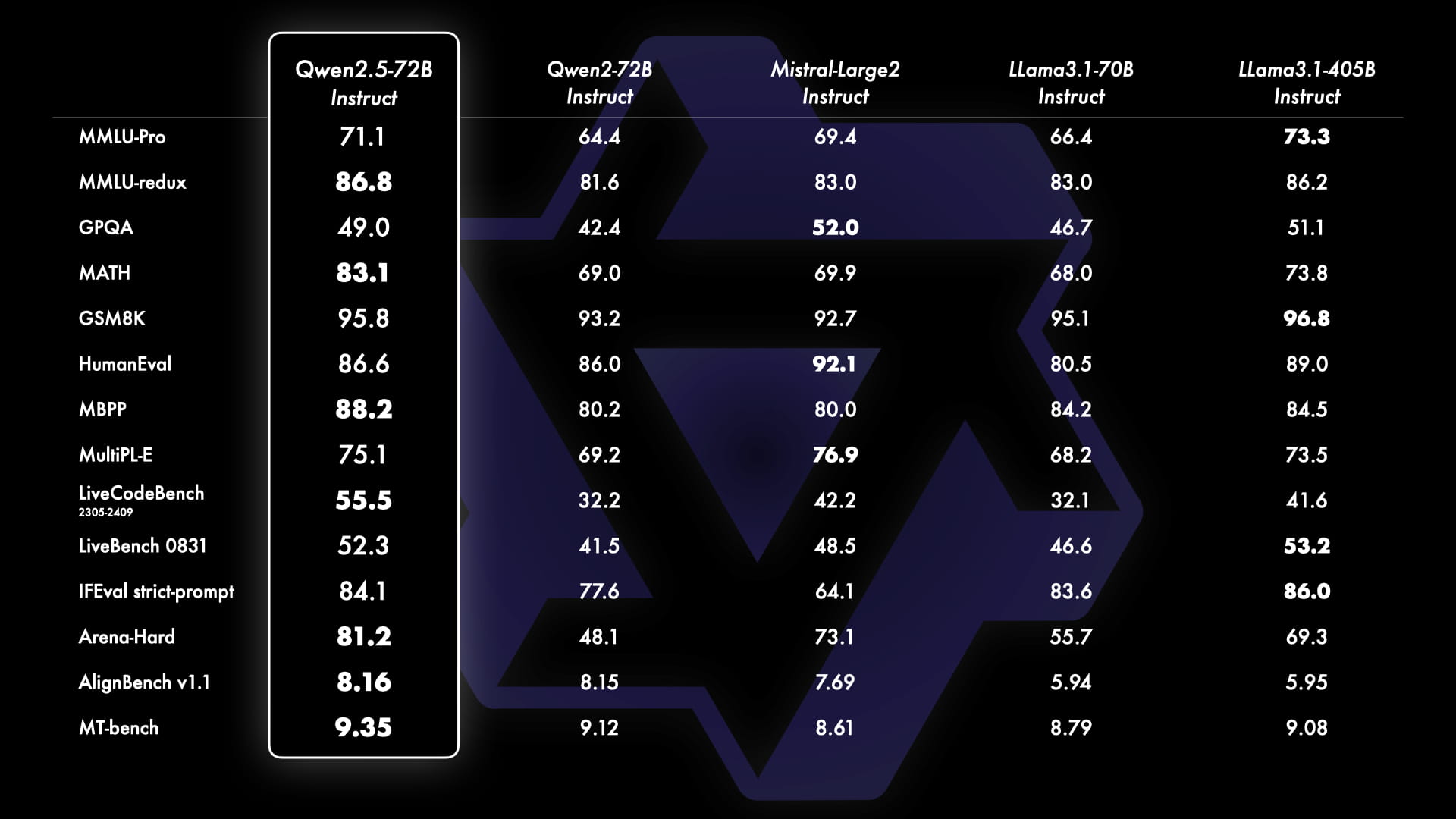
print(completion.choices[0].message.content)Qwen2.5的能力通过基准测试得到了充分的展示。其中,最大的开源模型Qwen2.5-72B(拥有720亿参数的稠密decoder-only语言模型)与Llama-3.1-70B和Mistral-Large-V2等领先的开源模型进行了对比。测试结果表明,Qwen2.5在多个基准测试中都表现出色,尤其是在指令调优后的版本中,模型的能力和人类偏好都得到了很好的体现。同时,Qwen2.5-72B的基础语言模型性能也达到了顶级水准,甚至可以与更大的模型(如Llama-3-405B)相媲美。
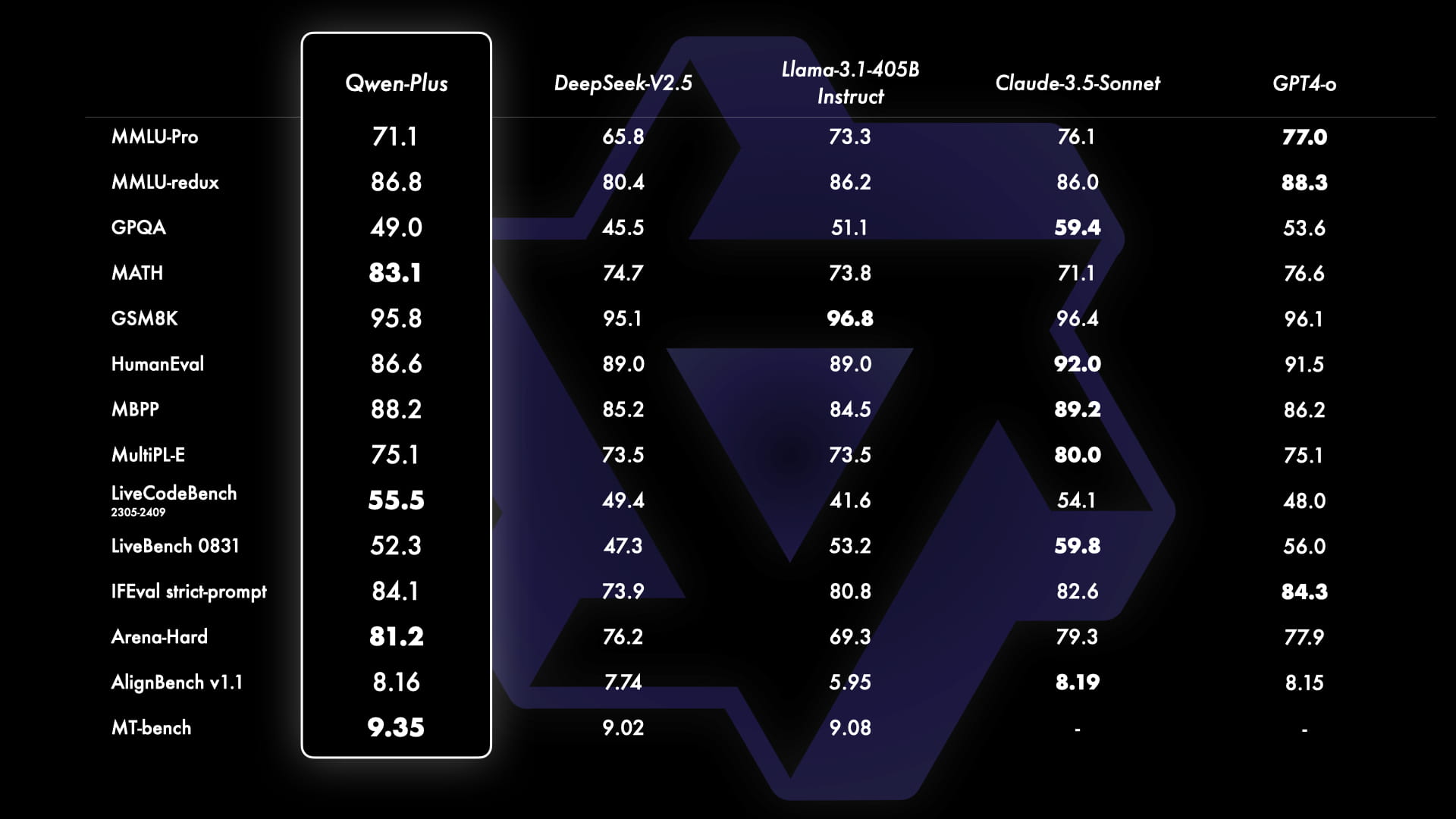
API模型Qwen-Plus与GPT4-o、Claude-3.5-Sonnet、Llama-3.1-405B和DeepSeek-V2.5等领先模型进行了对比。结果显示,Qwen-Plus显著优于DeepSeek-V2.5,并且在与Llama-3.1-405B的竞争中表现出了竞争力,虽然在某些方面仍不及GPT4-o和Claude-3.5-Sonnet。这些基准测试不仅突显了Qwen-Plus的优势,也指出了未来需要改进的地方,进一步强化了在大型语言模型领域持续改进和创新的承诺。
Qwen2.5的一个重要更新是重新引入了14B和32B模型,即Qwen2.5-14B和Qwen2.5-32B。这些模型在多样化的任务中超越了同等规模或更大规模的基线模型,例如Phi-3.5-MoE-Instruct和Gemma2-27B-IT。它们在模型大小和能力之间达到了最佳平衡,提供了匹配甚至超过一些较大模型的性能。此外,API模型Qwen2.5-Turbo相比这两个开源模型提供了极具竞争力的性能,同时提供了成本效益高且快速的服务。
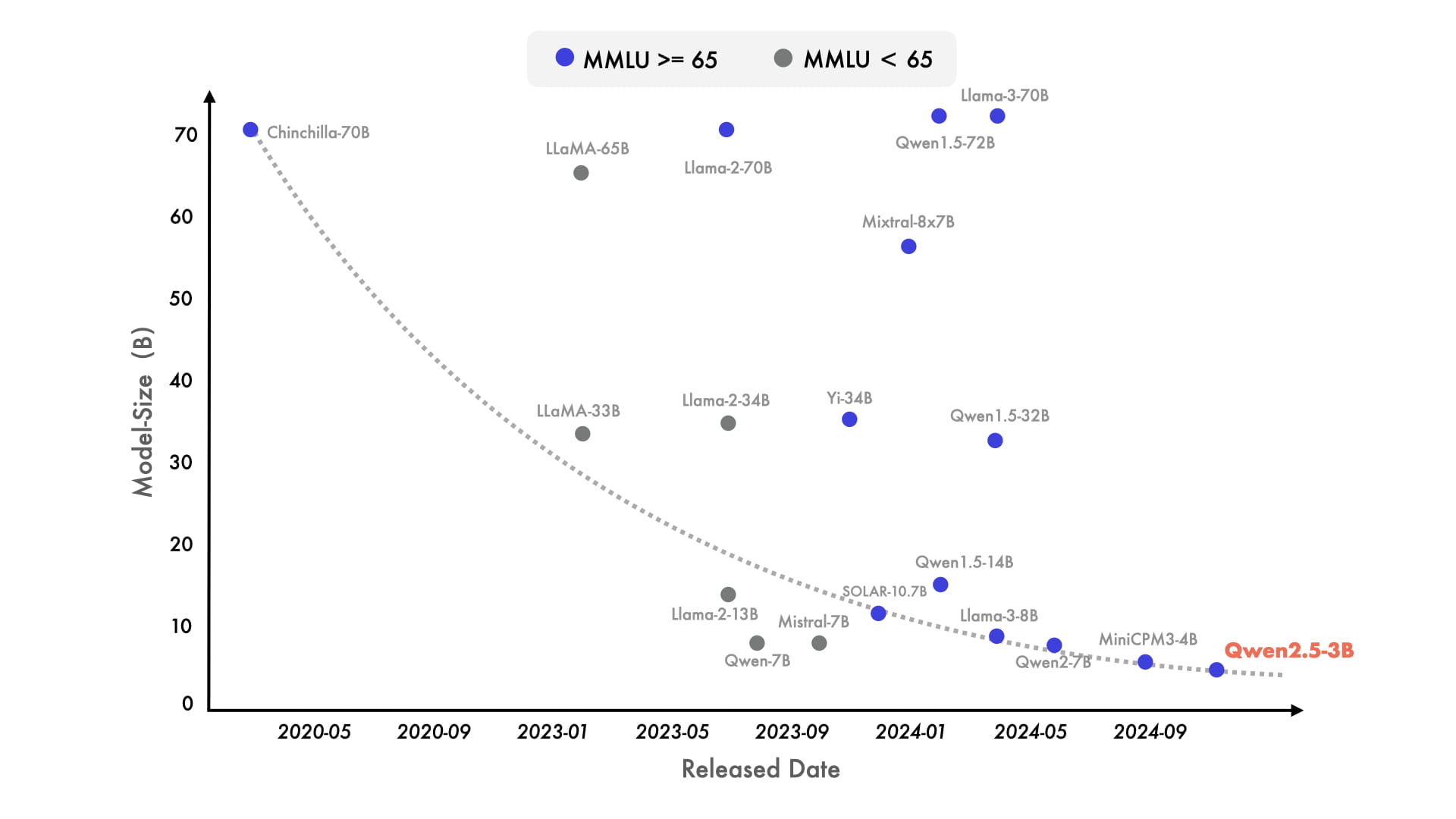
近年来,小型语言模型(SLMs)越来越受到关注。虽然SLMs的表现一直落后于大型语言模型(LLMs),但二者之间的性能差距正在迅速缩小。值得注意的是,即使是只有大约30亿参数的模型现在也能取得高度竞争力的结果。图表显示,在MMLU中得分超过65的新型模型正变得越来越小,这凸显了语言模型的知识密度增长速度加快。Qwen2.5-3B就是一个典型的例子,它仅凭约30亿参数就实现了令人印象深刻的性能。
除了在基准评估中取得的显著增强外,Qwen团队还改进了后训练方法。主要更新包括支持最长可达8K标记的长文本生成,大幅提升了对结构化数据的理解能力,生成结构化输出(特别是JSON格式)更加可靠,并且在多样化的系统提示下的表现得到了加强,这有助于有效进行角色扮演。这些改进使得Qwen2.5在实际应用中更加灵活和高效。
Qwen2.5-Coder是专门为编程应用而设计的。在性能测试中,Qwen2.5-Coder-7B-Instruct与领先的开源模型进行了基准测试,包括那些参数量大得多的模型。
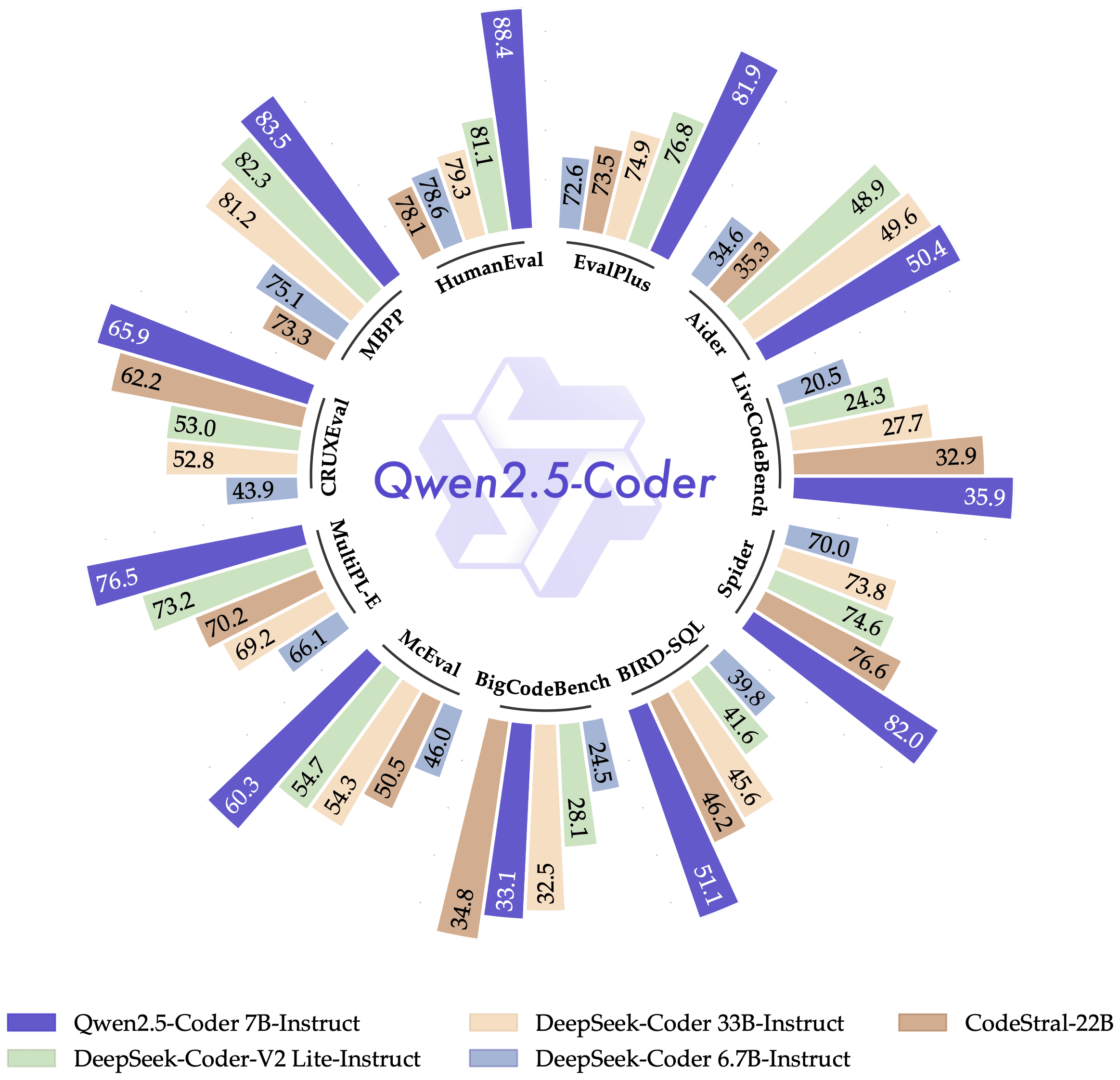
Qwen2.5-Coder在多种编程语言和任务中,它的表现超过了众多大型语言模型,展现了其卓越的编程能力,堪称个人编程助手的优秀选择。
在数学专用语言模型方面,Qwen2.5-Math相比Qwen2-Math,在更大规模的数学相关数据上进行了预训练,包括由Qwen2-Math生成的合成数据。Qwen2.5-Math还增加了对中文的支持,并通过赋予其进行CoT、PoT和TIR的能力来加强其推理能力。Qwen2.5-Math-72B-Instruct的整体性能超越了Qwen2-Math-72B-Instruct和GPT4-o,甚至是非常小的专业模型如Qwen2.5-Math-1.5B-Instruct也能在与大型语言模型的竞争中取得高度竞争力的表现。

可以通过Hugging Face Transformers库来使用Qwen2.5:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen2.5-7B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]要使用 vLLM 运行 Qwen2.5 并部署一个与 OpenAI API 兼容的服务,可以运行如下命令:
python -m vllm.entrypoints.openai.api_server \
--model Qwen/Qwen2.5-7B-InstructQwen2.5的发布是Qwen团队不断创新和突破的又一重要里程碑。这些模型的卓越性能和广泛应用前景,必将为人工智能领域的发展注入新的动力。Qwen团队将继续致力于开发更强大的基础模型,并期待与开源社区携手合作,共同推动人工智能技术的进步。










