
在人工智能领域,大型语言模型(LLM)正以前所未有的速度发展,并深刻地改变着我们与技术互动的方式。其中,Qwen2-7B作为一款备受瞩目的开源模型,以其卓越的性能和广泛的应用前景,吸引了众多开发者的目光。然而,对于许多初学者或不具备深厚技术背景的用户来说,本地部署大型语言模型仍然是一项具有挑战性的任务。幸运的是,Ollama的出现极大地简化了这一过程,使得一键部署Qwen2-7B成为可能。本文将深入探讨Ollama平台,并详细介绍如何利用它来轻松部署和运行Qwen2-7B模型,从而开启智能应用的新篇章。
Ollama:大型语言模型的“瑞士军刀”
Ollama是一款为简化大型语言模型本地部署而生的创新工具。它支持macOS、Linux和Windows等多种操作系统,并提供简洁明了的命令行界面,让用户能够轻松体验Qwen2等模型的强大功能。Ollama的设计理念是让用户摆脱繁琐的配置和依赖管理,专注于模型本身的应用和开发。对于Qwen2模型,Ollama提供了一站式的解决方案,从模型下载到运行,一切都变得异常简单。
Ollama部署运行:化繁为简
安装Ollama:轻松上手
安装Ollama的过程非常简单,只需几个步骤即可完成:
- 访问官方网站:打开浏览器,访问Ollama官方网站。
- 选择版本:根据您的操作系统选择相应的安装包。Ollama支持macOS、Linux和Windows。
- 下载安装包:点击Download按钮,下载适用于您设备的Ollama安装包。
- 安装Ollama:根据下载的安装包格式,运行安装程序或解压缩文件到您选择的目录。
对于Linux用户,还可以通过命令行进行安装:
curl -fsSL https://ollama.com/install.sh | sh请注意,根据实际发布的版本号替换上述命令中的版本信息。

验证安装:确保一切就绪
安装完成后,可以通过运行以下命令来验证Ollama是否正确安装:
ollama --version如果安装正确,该命令将输出Ollama的版本信息。

启动ollama服务:
ollama serve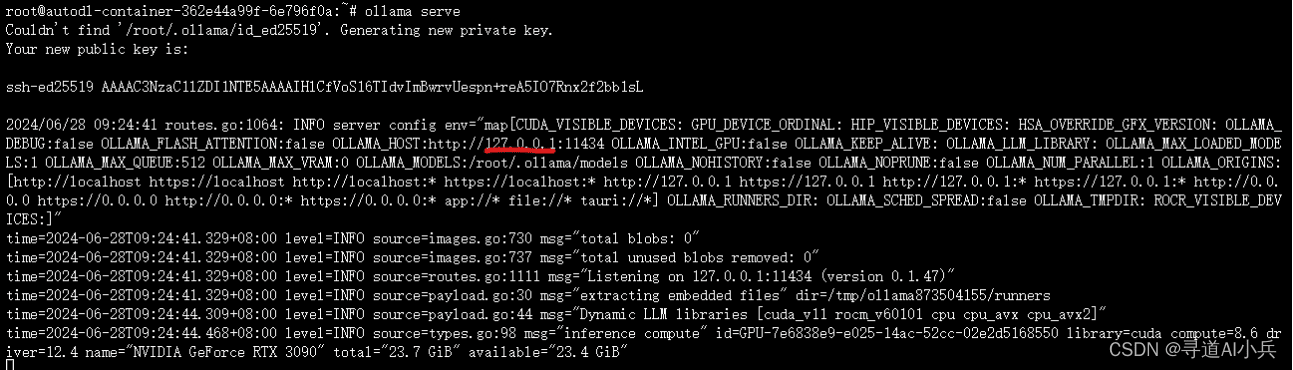
快速开始:体验Qwen2的强大
在Ollama中运行Qwen2模型非常简单。首先,确保您已安装Ollama并启动服务。然后,在命令行中运行以下命令:
ollama run qwen2要运行特定大小的Qwen2-Instruct模型,例如7B大小的模型,可以通过指定模型标签来实现:
ollama run qwen2:7bOllama将自动下载所需的模型文件并启动Qwen2。首次运行可能需要一些时间,具体取决于您的网络速度和计算机性能。下载和启动成功后,您就可以与Qwen2进行对话了。

对话测试:初探智能
让我们进行一些对话测试,看看Qwen2的表现如何:
>>> 你好?
你好!有什么问题我可以帮助你解答吗?
>>> 你是谁?
我是阿里云开发的一款超大规模语言模型,我叫通义千问。作为一个AI助手,我的主要任务是回答用户的问题、提供信息和在各个领域与用户进行交流。我被设计为能理解自然语
言,并以简洁明了的方式提供帮助或解答问题。请随时告诉我你有需要了解的内容,我会尽力提供支持!
>>> 什么是通义千问?
通义千问是阿里云研发的超大规模语言模型,它具有生成人类级别文本、回答问题和与用户进行对话的能力。作为一个AI助手,我旨在帮助解答问题、提供建议或进行信息交流。
请告诉我你有什么需要了解的内容或者想要探讨的话题,我会尽力提供帮助!
>>> 什么是大语言模型?
大语言模型(Large Language Model, LLM)是指通过大量数据训练的复杂深度学习模型,能够处理自然语言任务并生成与输入相关的文本。这些模型在结构上通常包含许多层神
经网络和大量的参数,使其具有高度的学习能力和适应性。从上述对话可以看出,Qwen2能够理解自然语言并给出合理的回答。它不仅可以提供信息,还可以进行简单的对话交流。
高级用法:定制您的Qwen2体验
Ollama不仅提供了简单的命令行操作,还允许用户通过高级配置来充分利用Qwen2模型的功能。通过调整各种参数,您可以控制生成文本的特性,从而满足不同的应用需求。
参数调整:精细化控制
以下是一些常用的参数及其说明:
| 参数名 | 描述 | 类型 | 默认值 | 设置值 |
|---|---|---|---|---|
| mirostat | 启用 Mirostat 采样以控制复杂度。(默认:0,0=禁用,1=Mirostat,2=Mirostat 2.0) | int | 0 | mirostat 0 |
| mirostat_eta | 影响算法响应生成文本反馈的速度。较低的学习率将导致调整速度较慢,而较高的学习率将使算法更具响应性。(默认:0.1) | float | 0.1 | mirostat_eta 0.1 |
| mirostat_tau | 控制输出的一致性与多样性之间的平衡。较低的值将导致文本更加集中和一致。(默认:5.0) | float | 5.0 | mirostat_tau 5.0 |
| num_ctx | 设置用于生成下一个令牌的上下文窗口大小。(默认:2048) | int | 2048 | num_ctx 4096 |
| repeat_last_n | 设置模型向后查看的距离,以防止重复。(默认:64,0=禁用,-1=num_ctx) | int | 64 | repeat_last_n 64 |
| repeat_penalty | 设置对重复的惩罚强度。较高的值(例如 1.5)将更强烈地惩罚重复,而较低的值(例如 0.9)将更宽容。(默认:1.1) | float | 1.1 | repeat_penalty 1.1 |
| temperature | 模型的温度。增加温度将使模型回答更具创造性。(默认:0.8) | float | 0.8 | temperature 0.7 |
| seed | 设置用于生成的随机数种子。将此设置为特定数字将使模型对同一提示生成相同的文本。(默认:0) | int | 0 | seed 42 |
| stop | 设置用于停止的序列。当遇到此模式时,LLM 将停止生成文本并返回。可以通过在 modelfile 中指定多个单独的 stop 参数来设置多个停止模式。 | string | stop “AI assistant:” | |
| tfs_z | 尾部自由采样用于减少输出中不太可能的令牌的影响。较高的值(例如 2.0)将更多地减少影响,而值为 1.0 时禁用此设置。(默认:1) | float | 1 | tfs_z 1 |
| num_predict | 生成文本时预测的最大令牌数。(默认:128,-1=无限生成,-2=填充上下文) | int | 128 | num_predict 42 |
| top_k | 降低生成无意义文本的概率。较高的值(例如 100)将提供更多样的回答,而较低的值(例如 10)将更为保守。(默认:40) | int | 40 | top_k 40 |
| top_p | 与 top-k 一起工作。较高的值(例如 0.95)将导致文本更多样化,而较低的值(例如 0.5)将生成更集中和保守的文本。(默认:0.9) | float | 0.9 | top_p 0.9 |
样例1:调整生成文本的多样性
通过调整top_p和top_k参数,可以控制生成文本的多样性和连贯性。例如,增加top_p的值可以使模型生成更多样化的文本:
ollama run qwen2:7b --top_p 0.9 --top_k 50样例2:避免重复生成文本
在需要避免模型重复生成相同文本的场景中,可以调整repeat_penalty参数。增加repeat_penalty的值可以降低模型生成重复文本的可能性:
ollama run qwen2:7b --repeat_penalty 2.0展望未来:Ollama的无限可能
Ollama作为一个强大的本地部署工具,为用户提供了一种简便、高效的方式来运行和体验大型语言模型。它简化了模型部署的复杂性,使得更多的开发者和用户能够参与到人工智能的应用和创新中来。随着技术的不断发展,Ollama将继续扩展其功能,支持更多的模型和应用场景,为广大用户提供更加丰富的人工智能体验。

Ollama的出现,无疑为大型语言模型的普及和应用开启了新的篇章。它让我们看到了人工智能技术 democratize 的希望,让更多的人能够参与到这场技术革命中来。让我们一起期待Ollama在未来的发展,并共同见证人工智能技术的辉煌!








