
拥抱 Gemini:Google AI 在自动化 Bug 修复中的应用详解
在前沿技术领域,人工智能(AI)正以惊人的速度渗透到各个行业。在软件开发领域,AI 驱动的自动化 Bug 修复正逐渐成为现实。前文中,我们探讨了 AI 自动化修复 Bug 的实现思路,但未深入讨论 Google AI 的具体接入方法。本文将详细剖析如何有效接入 Google 的 Gemini 模型,为软件开发流程带来智能化变革。
Gemini:通向通用人工智能的桥梁
2023 年,Google 推出了 Gemini,其目标是打造真正的通用人工智能(AGI)。Gemini 并非单一模型,而是一个多模态 AI 系统,能够跨越文本、代码、音频、图像和视频等多种模态进行无缝对话,并提供最佳响应。它是 Google 迄今为止构建的最大、最强大的模型,能够理解复杂的世界,处理各种类型的输入和输出。在性能测试中,Gemini 在许多方面匹及甚至超越了领域专家,展现出强大的通用性。
Gemini 提供了三个不同版本的人工智能模型,以满足不同的应用需求:
- Gemini Ultra:专为处理高度复杂的任务而设计,例如科学研究、高级分析等。
- Gemini Pro:适用于广泛的任务,包括内容生成、代码编写、客户服务等。
- Gemini Nano:特别为设备端任务设计,例如移动设备上的智能助手、离线语音识别等。
值得关注的是,最近发布的 Gemini Advanced 模型目前仍在内测阶段,需要加入等待名单才能体验。不过,其他三个 AI 模型的使用不受影响,Gemini 的 API 接口目前开放免费调用,为开发者提供了宝贵的实践机会。
申请 Gemini API Key:开启智能之旅
要开始使用 Gemini,首先需要在 Google AI Studio 中创建一个 API Key。API Key 是访问 Gemini 服务的凭证,类似于通行证,拥有它才能调用 Gemini 的各项功能。
Google AI Studio 地址:https://aistudio.google.com/app/apikey
以下是创建 API Key 的详细步骤:
- 进入 Google AI Studio:打开 Google AI Studio 链接,进入 API Key 管理页面。
- 创建 API Key:点击左侧菜单中的
Get API key选项,然后点击页面中的Create API key按钮。
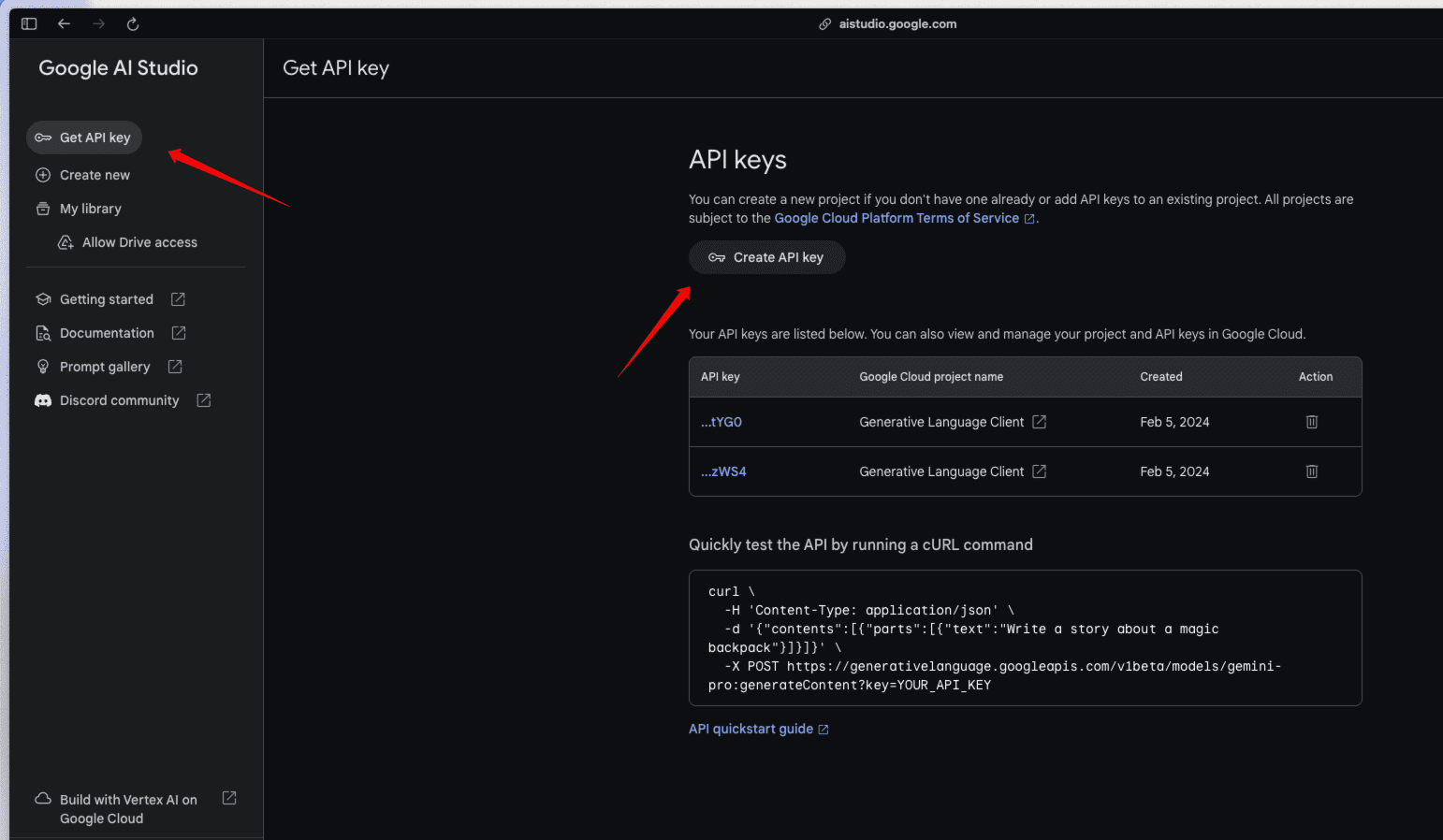
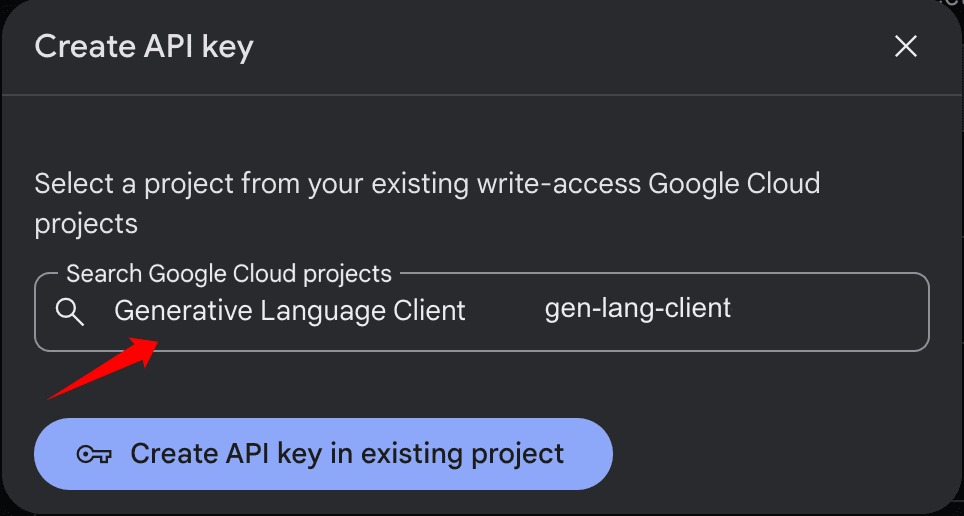
- 选择 Google Cloud 项目:在弹出的窗口中,选择一个 Google Cloud Project。通常情况下,这里会默认有一个 Generative Language Client 项目。如果已有项目,直接选择即可;如果没有,也可以在 Google Cloud 上创建一个空项目。
- 创建 API Key:选择项目后,点击
Create API key in existing project按钮,系统将开始创建 API Key。
- 复制 API Key:生成 API Key 后,会弹出一个窗口,其中包含你的 API Key。务必复制并妥善保管此 Key,后续调用 API 时需要使用。
- 找回 API Key:如果忘记了 API Key,可以在页面上点击对应的 API Key 条目再次查看。

探索 Gemini API:代码世界的无限可能
Gemini API 提供了多种语言的 SDK,包括 Python、Go、Node.js 等。开发者也可以选择直接通过接口地址进行调用,灵活性很高。
Python SDK:快速上手指南
本文以 Python SDK 为例,介绍 Gemini API 的使用方法。
1. 安装 SDK
使用 pip 安装 Gemini API 的 Python SDK:
pip install -q -U google-generativeai2. 导入包
安装完成后,在代码中导入 google.generativeai 包:
import google.generativeai as genai3. 设置 API 密钥
设置 API 密钥有两种方式:
- 方式一:环境变量
将密钥放入 GOOGLE_API_KEY 环境变量中。SDK 会自动从环境变量中获取 API Key。
import os
os.environ["GOOGLE_API_KEY"] = "<你的API Key>"- 方式二:直接配置
将密钥传递给 genai.configure(api_key=...) 方法。
genai.configure(api_key=GOOGLE_API_KEY)注意: 两种方式选择其一即可。
文本生成:初试 Gemini 的强大
Gemini 提供了多种模型,对于纯文本提示,我们通常使用 gemini-pro 模型。
model = genai.GenerativeModel('gemini-pro')通过 generate_content 方法,Gemini 模型可以处理包括多轮对话和跨模态输入在内的复杂用例。无论是简单的问答还是复杂的对话,甚至是需要对图像资料进行分析和描述,Gemini 都能提供有效的输出。
要实现基本的文本提示功能,只需向 GenerativeModel.generate_content 方法传递一个字符串。例如,要询问生命的意义,代码如下:
response = model.generate_content("什么是生命的意义?")
print(response.text)默认情况下,模型在完成整个内容的生成之后才会返回响应,这种方式适合于那些不需要即时反馈的场景。然而,在某些情况下,我们可能希望能够实时地获得模型的每个响应部分,这时可以使用流式传输。
启用流式传输非常简单,只需在调用 generate_content 方法时添加一个 stream=True 参数。这样,就可以在模型生成响应的同时接收到每一块内容,提供更为动态和互动的体验。
response = model.generate_content("什么是生命的意义?", stream=True)
for chunk in response:
print(chunk.text)Gemini 的更多可能性:超越文本的边界
Gemini 的能力远不止于文本生成。它还支持处理图像、音频和视频等多种模态的数据,并能进行复杂的聊天对话。这些高级功能为开发者提供了广阔的创新空间。
由于本文侧重于自动化 Bug 修复,我们在此不再赘述 Gemini 的所有功能。如果读者对 Gemini 的其他功能感兴趣,可以查阅 Google API 文档,其中包含详细的说明和示例。
总结:Gemini 在自动化 Bug 修复中的应用前景
Gemini 作为 Google 最新的 AI 模型,为自动化 Bug 修复带来了新的可能性。通过 Gemini 的强大能力,开发者可以构建更智能、更高效的 Bug 修复工具,从而提高软件开发的效率和质量。随着 Gemini 技术的不断发展,我们有理由相信,AI 将在软件开发领域发挥越来越重要的作用。
相关资料:
- Gemini API 文档:https://ai.google.dev/docs
- Google Gemini 宣传片:https://www.youtube.com/watch?v=jV1vkHv4zq8








