
Gemini语言能力深度评测报告:第三方视角下的AI模型对比分析
最近,谷歌发布了Gemini系列模型,声称其在多项任务上的性能可以与OpenAI的GPT系列相媲美。为了验证这一说法,并深入了解Gemini的语言处理能力,我们进行了一项全面的第三方评测。本报告旨在通过可复现的代码和完全透明的结果,对Gemini Pro与OpenAI的GPT模型进行客观比较,并分析它们各自的优势与不足。同时,我们还简要对比了Mixtral模型,作为一个优秀的开源模型参照。
实验设计与方法
我们的评估涵盖了10个不同的数据集,旨在测试模型在推理、知识问答、数学问题解决、语言翻译、代码生成以及作为指令遵循型AI智能体等方面的能力。实验过程中,我们使用了统一的提示和评估协议,以确保所有模型在同等条件下进行比较。这些提示通常包含问题、输入以及少量示例,有时还会加入“思维链推理”等方法。
为了更全面地了解模型的性能,我们不仅关注整体准确率,还深入分析了模型在不同难度级别、不同类型的任务以及不同输出长度下的表现。此外,我们还特别关注了Gemini Pro在处理特定类型问题时的一些潜在问题,例如多项选择题的答案排序偏差、数学推理的不足以及内容过滤的限制。
知识问答能力评测
我们利用MMLU数据集对模型的知识问答能力进行了评估。MMLU包含57个基于知识的多项选择题任务,涵盖STEM、人文学科和社会科学等多个领域。评估方法包括标准的五次尝试(5-shot)提示和五次尝试链式思考(5-shot chain-of-thought)提示。需要注意的是,我们没有采用多次响应采样和基于自我一致性的重排方法,因为这会大幅增加成本。
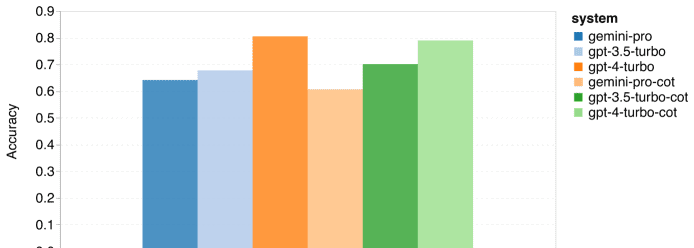
结果分析
从总体结果来看,Gemini Pro的准确率低于GPT 3.5 Turbo,与GPT 4 Turbo相比差距更为明显。思路链式提示对性能的提升并不显著,这可能是因为MMLU主要考察的是知识储备,而非复杂的推理能力。
进一步分析发现,Gemini Pro在选择多项选择题的“D”选项时存在明显的偏好,这暗示其在解决此类问题时可能存在指令调优不足的问题。此外,Gemini Pro在如人类性学、逻辑学、初等数学以及医学专业等方面的表现不如GPT 3.5 Turbo,这可能与内容过滤机制以及基础数学推理能力的不足有关。
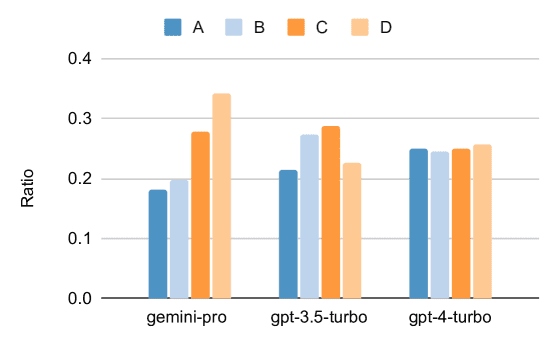
问题与挑战
值得注意的是,Gemini Pro在某些情况下无法提供答案,尤其是在涉及潜在非法或敏感内容的问题时。此外,Gemini Pro在解决逻辑学和初等数学任务所需的基础数学推理方面略显不足。
通用推理能力评测
我们利用BIG-Bench Hard数据集对模型的通用推理能力进行了评估。该数据集包含27种多样化的推理任务,涵盖算术、符号、多语言推理以及事实知识理解等领域。评估方法遵循Eleuther harness的标准3-shot提示规则。
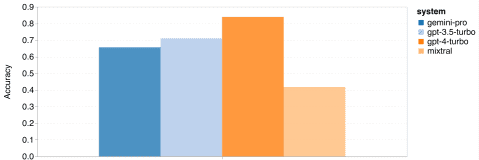
结果分析
总体而言,Gemini Pro在总体准确率方面略逊于GPT 3.5 Turbo,与GPT 4 Turbo相比差距明显。Mixtral模型的整体准确率则更低。
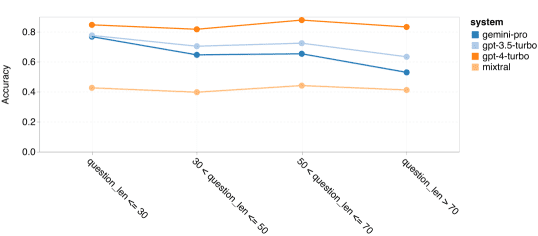
进一步分析发现,Gemini Pro在处理较长和更复杂的问题时表现不佳,而GPT系列模型则表现更加稳定。此外,Gemini Pro在“tracking_shuffled_objects”任务上的表现尤其糟糕,经常无法正确追踪物品在不同持有者之间的转移过程。
亮点与优势
值得一提的是,在某些任务中,Gemini Pro的表现优于GPT 3.5 Turbo,例如体育理解、迪克语言、单词排序以及解析表格等。这表明Gemini Pro在某些特定领域具有一定的优势。
总的来说,在执行通用推理任务时,尝试使用Gemini和GPT模型,然后根据具体情况决定选用哪一个,可能是个不错的选择。
数学推理能力评测
我们选择了GSM8K、SVAMP、ASDIV和MAWPS四个数学文字问题基准测试来评估模型的数学推理能力。评估方法采用了标准的8次少样本连锁思考提示(8-shot chain-of-thought prompting)。
结果分析

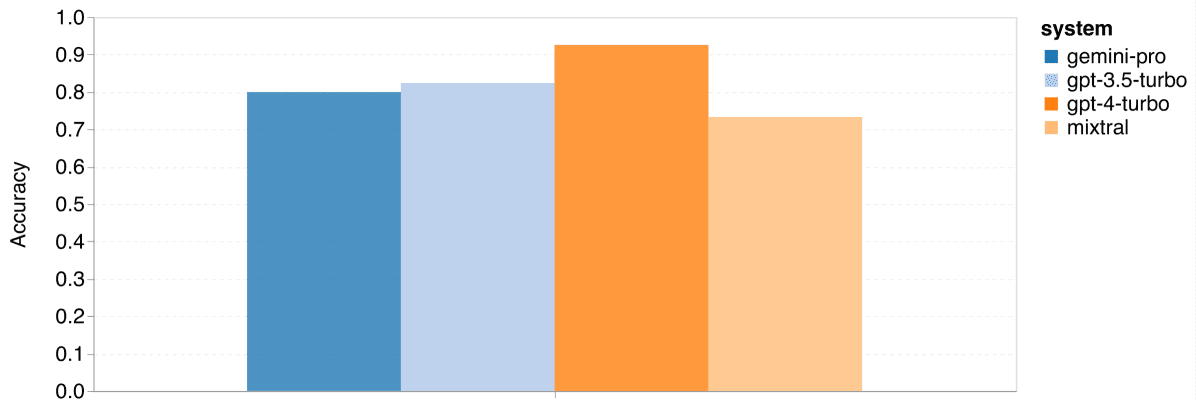
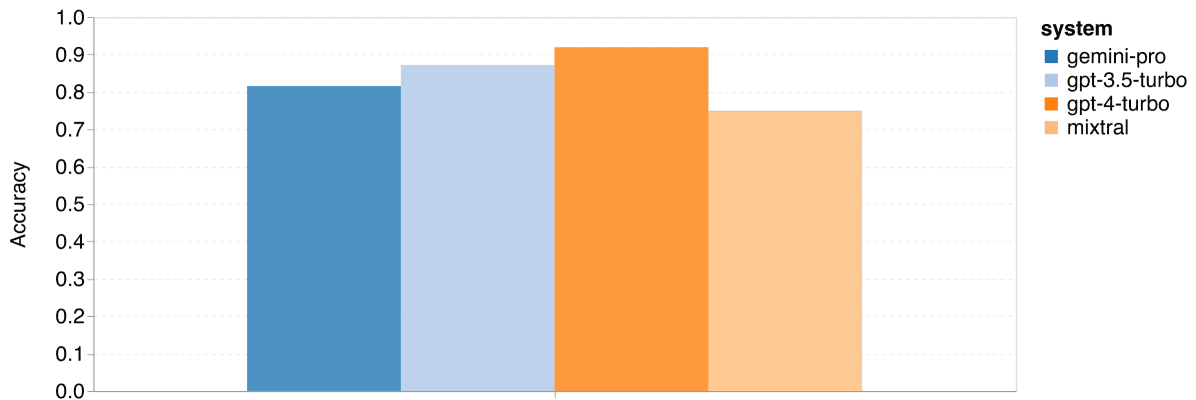
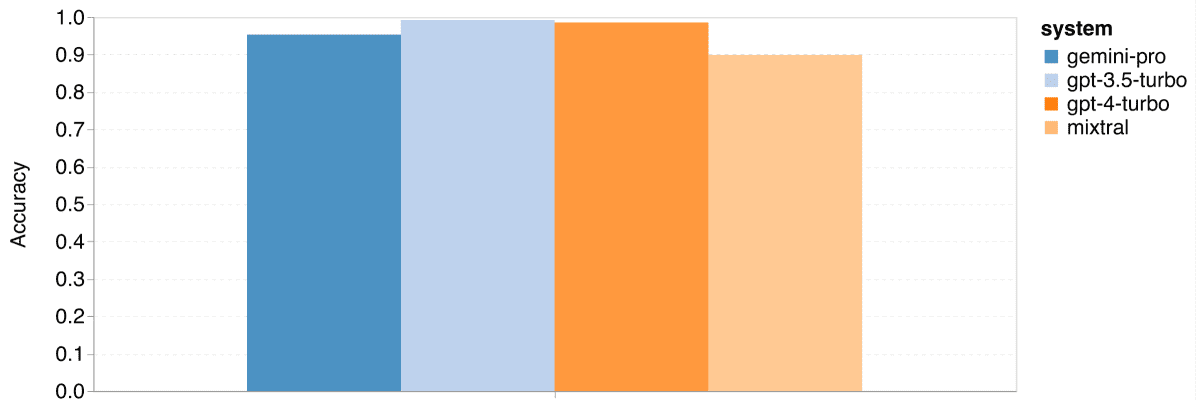
Gemini Pro在GSM8K、SVAMP和ASDIV任务中的准确率略低于GPT 3.5 Turbo,与GPT 4 Turbo相比差距更大。在MAWPS任务中,所有模型的准确率都超过了90%,但Gemini Pro的表现仍稍逊于GPT模型。Mixtral模型的准确率相比其他模型要低很多。
问题长度的影响
在处理较短的问题时,GPT 3.5 Turbo的表现超过了Gemini Pro,但在处理较长问题时,其表现下降得更快。相比之下,Gemini Pro在处理长问题时虽然准确率略低,但表现相对稳定。
推理链条长度的影响
GPT 4 Turbo即使在长推理链的应用中也表现出色,而GPT 3.5 Turbo、Gemini Pro和Mixtral在处理较长的推理链时则表现不佳。在涉及超过100个COT步骤的复杂任务中,Gemini Pro的表现优于GPT 3.5 Turbo,但在处理较简单的任务时则稍显不足。
数字位数的影响
GPT 3.5 Turbo在处理多位数的数学问题上更加稳健,而Gemini Pro在处理数字较多的问题时表现稍显下降。
代码生成能力评测
我们使用HumanEval和ODEX数据集对模型的代码生成能力进行了评估。HumanEval主要测试模型对Python标准库的理解能力,而ODEX则更广泛地考察模型在整个Python生态中使用各种库的能力。评估指标为Pass@1,即模型生成的单个代码样本是否能通过测试用例。
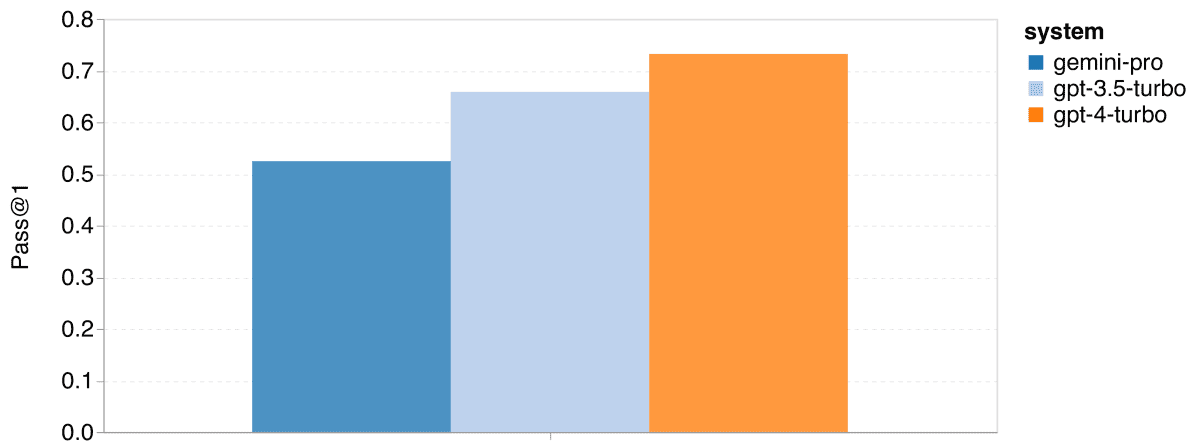
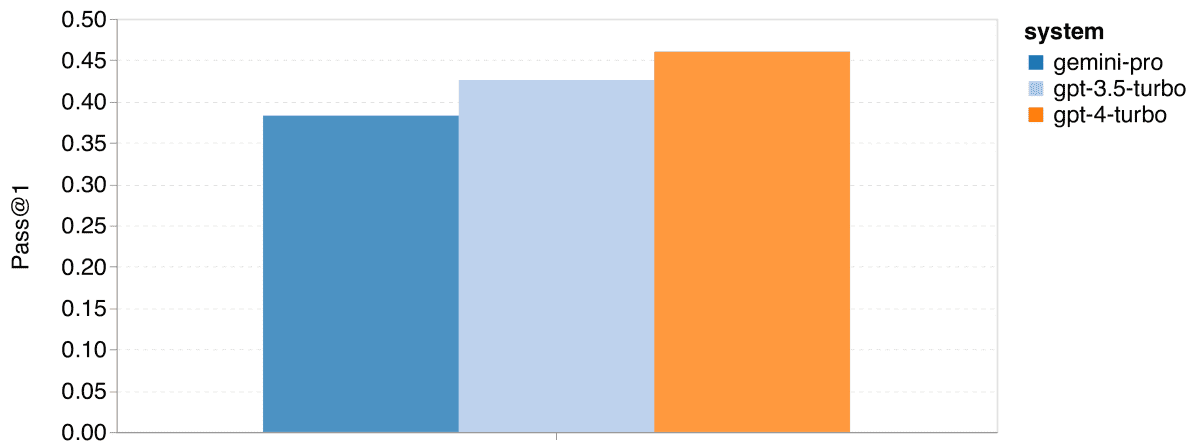
结果分析
Gemini Pro在两项任务中的首次通过率(Pass@1)低于GPT 3.5 Turbo,且远低于GPT 4 Turbo。这表明Gemini在代码生成方面的能力尚有提高空间。
解决方案长度的影响
尽管在解决方案较短时,Gemini Pro的首次通过率与GPT 3.5相当,但在解决方案更长时,它的表现则大幅落后。
所需库的影响
在大多数使用了特定库的情况下,Gemini Pro的表现不如GPT 3.5。然而,在涉及matplotlib的情况下,Gemini Pro的表现超过了GPT 3.5和GPT 4,展现出在代码绘图和可视化方面的强大能力。
机器翻译能力评测
我们使用FLORES-200机器翻译基准来评估模型在多语言方面的能力,重点研究了20种多样化语言组合间的翻译能力。评估指标包括spBLEU和chrF2++。
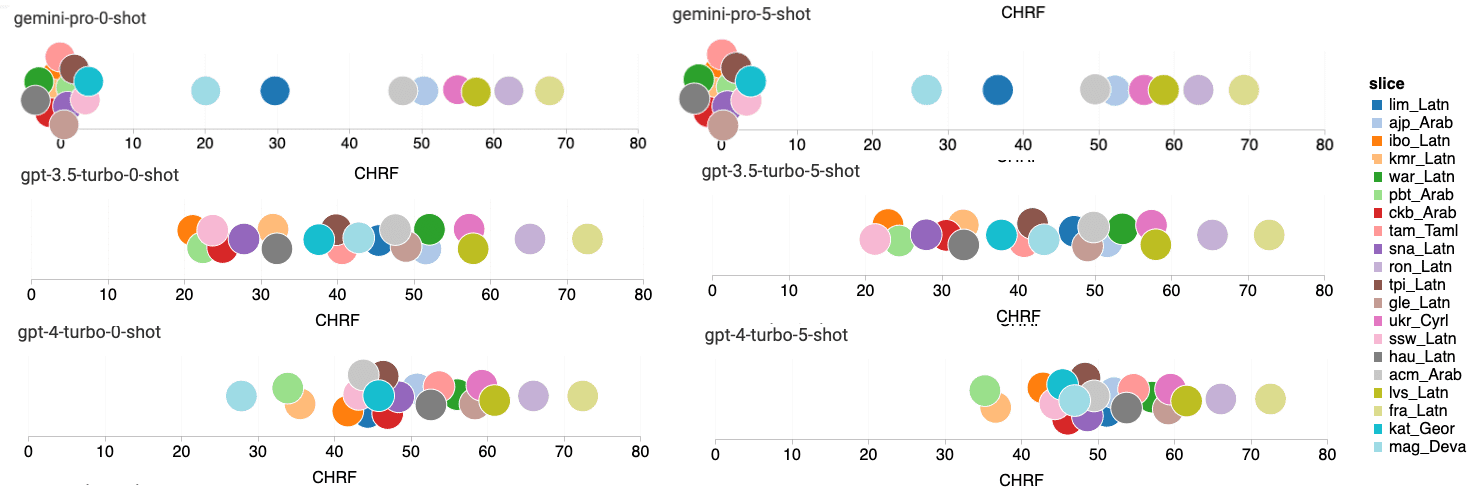
结果分析
Google Translate通常优于其他模型,尤其在9种语言上表现出色。而NLLB在“零样本”和“少样本”设置中,在6到8种语言上表现优秀。尽管通用语言模型表现出竞争力,但它们在翻译非英语语言方面还未能超过专门的机器翻译系统。
Gemini Pro的响应屏蔽情况
Gemini Pro在特定语言上性能不佳的原因是,在置信度较低的情况下,它倾向于屏蔽响应。在非屏蔽样本中,Gemini Pro的表现略胜于GPT 3.5 Turbo和GPT 4 Turbo。
网络代理能力评测
我们采用了WebArena作为基于执行结果的仿真环境,评估模型充当网络导航代理的能力。分配给代理的任务包括信息搜寻、网站导航以及内容和配置操作。评估标准依据实际执行结果。
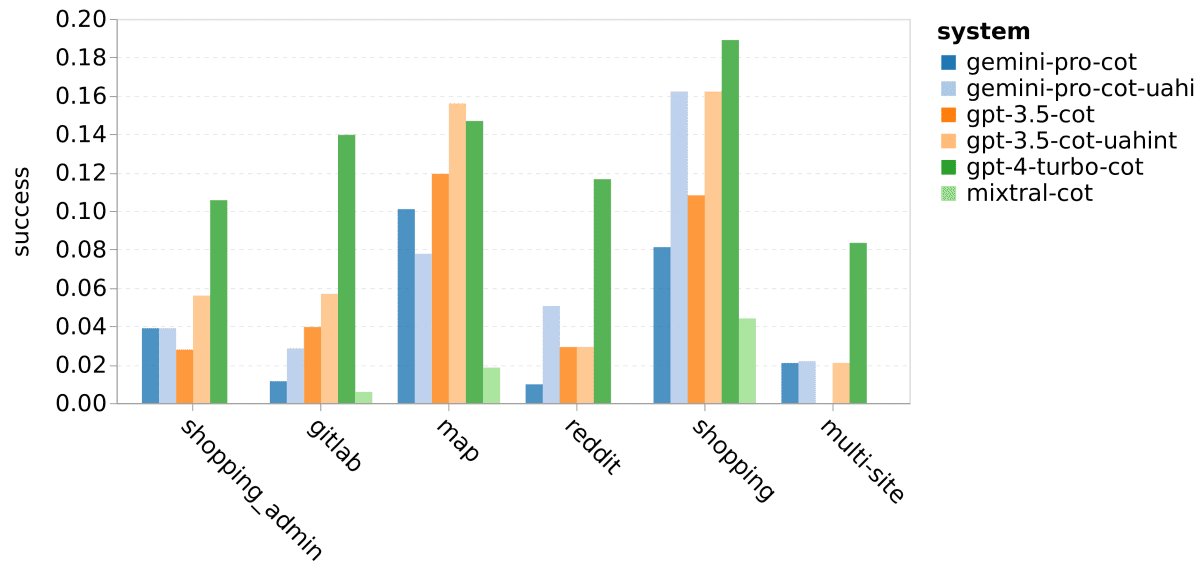
结果分析
与GPT-3.5-Turbo相比,Gemini-Pro的表现相似,但略有不足。在提醒任务可能无法完成的情况下,Gemini-Pro表现更佳。Gemini Pro更倾向于预测任务无法完成,并且更倾向于使用简短的短语进行回应,在得出结论前的步骤较少。
结论与展望
我们的研究表明,Gemini Pro在准确性上大体与GPT 3.5 Turbo相当,但略逊一筹,远不及GPT 4。它优于Mixtral。Gemini Pro在多项选择题的回应顺序偏差、处理大数字的数学推理、代理任务的提前终止以及因严格内容过滤导致的失败回应等方面,表现略逊于GPT 3.5 Turbo。然而,在特别长和复杂的推理任务上,Gemini的表现优于GPT 3.5 Turbo;并且,在任务回应不受过滤时,Gemini在多语言任务上也表现出色。
我们建议研究人员和实践者仔细研究Gemini Pro模型,将其作为与GPT 3.5 Turbo相当的工具。Gemini的Ultra版本尚未发布,但据称能与GPT 4相媲美,因此一旦这一模型推出,对其进行进一步的研究将是非常有价值的。
局限性
值得注意的是,我们的研究是对当前不断变化且不稳定的基于API的系统的一个时间点的快照。此外,这些结果可能受我们选择的特定提示语和生成参数的影响。最后,数据泄露问题是目前评估大语言模型时普遍面临的挑战。








