
通义千问本地部署完全指南:Qwen-7B到Qwen-14B实战经验分享
在人工智能领域,大语言模型(LLM)正扮演着越来越重要的角色。通义千问,作为阿里巴巴旗下的明星产品,凭借其强大的性能和开放的姿态,吸引了众多开发者的目光。本文将深入探讨如何在本地部署通义千问,从环境搭建到模型运行,再到流式输出的实现,提供一份详尽且实用的教程。无论你是研究人员还是技术爱好者,都能从中获益。
1. 模型下载:从魔搭ModelScope开始
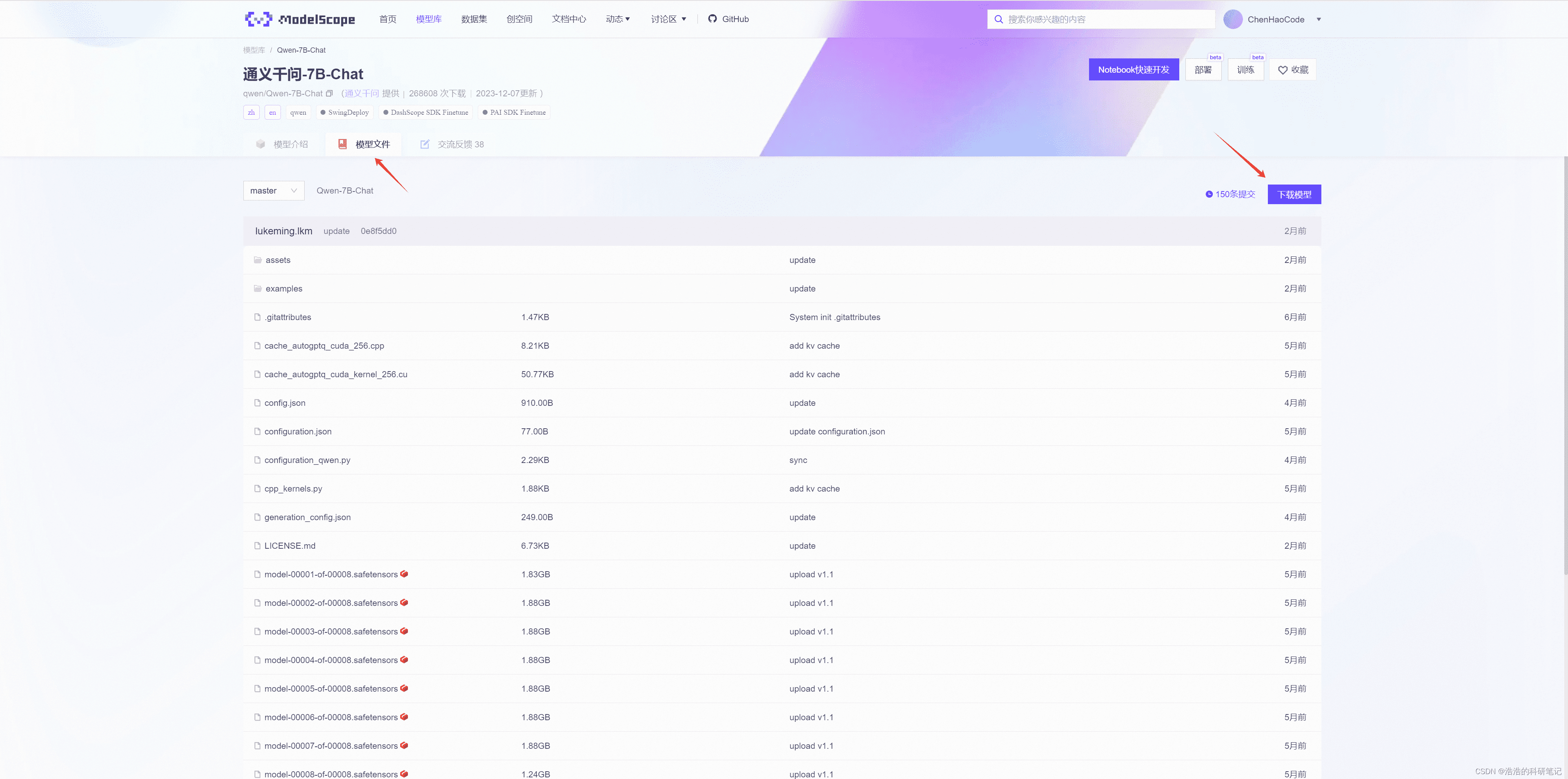
本地部署的第一步是获取模型文件。通义千问的Qwen系列模型,如Qwen-7B-Chat、Qwen1.5-1.8B以及Qwen-14B-Chat,都可以在魔搭ModelScope社区找到。以Qwen-7B-Chat为例,访问其模型页面:
https://modelscope.cn/models/qwen/Qwen-7B-Chat/summary

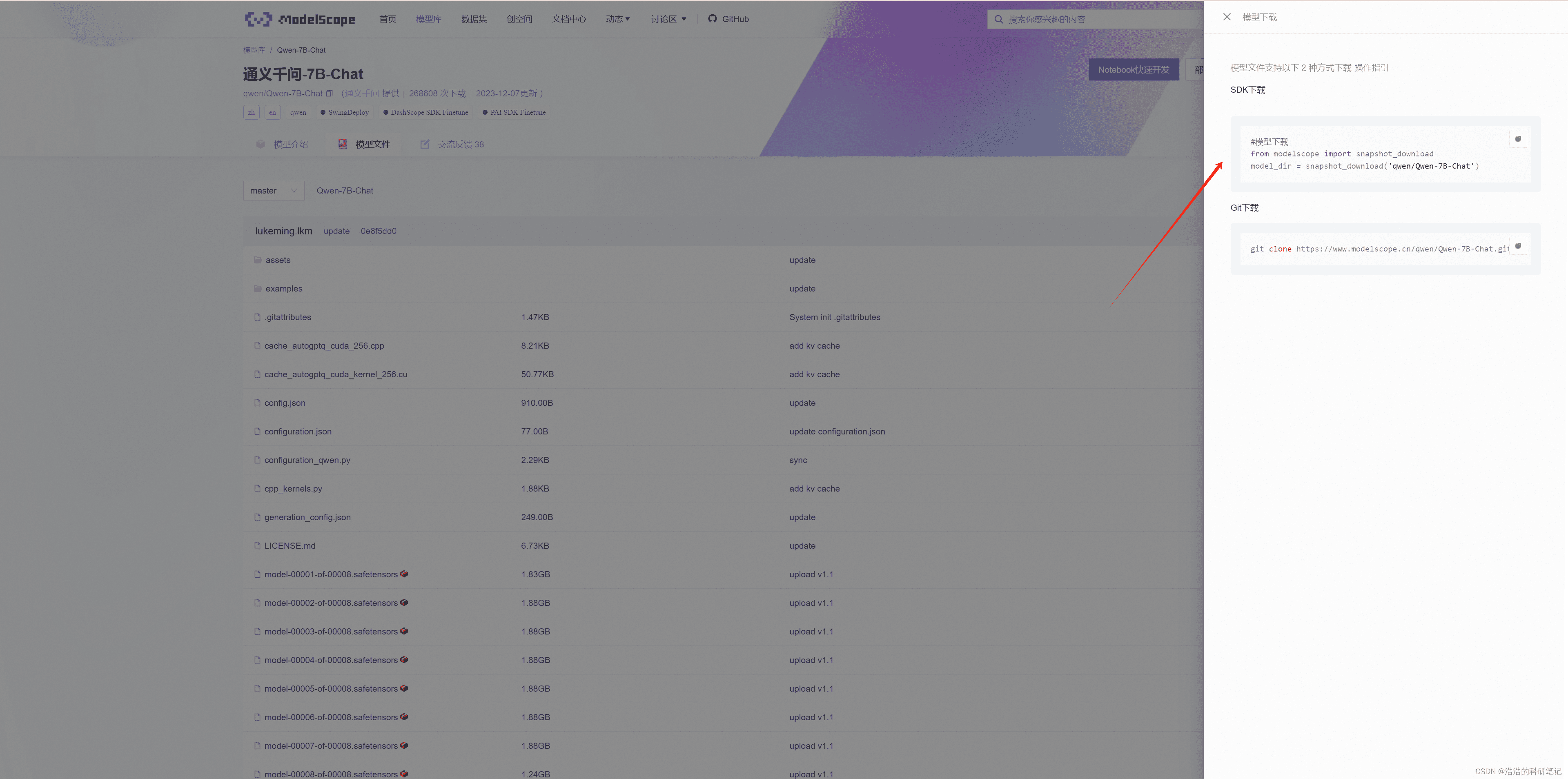
在模型文件页面,你可以选择使用SDK或Git进行下载。推荐使用SDK,但需要指定cache_dir参数,将模型下载到自定义的本地目录。模型大小约为14.4GB。
from modelscope import snapshot_download
model_dir = snapshot_download('qwen/Qwen-7B-Chat', cache_dir='你的模型存放目录')下载过程中,如果网络状况不佳,可能会出现卡顿或连接中断。确保网络稳定是成功下载的关键。

2. 环境搭建:打造本地运行的基石
为了顺利运行本地部署的通义千问模型,需要搭建满足要求的虚拟环境。官方推荐使用GPU版本的PyTorch。以下是我的环境配置,供你参考:
| 名称 | 硬件型号/软件版本 |
|---|---|
| CPU | 英特尔 Core i7-14700KF |
| GPU | NVIDIA GeForce RTX 4070 Ti(12 GB/华硕) |
| CUDA | Driver Version: 546.65 CUDA Version: 12.3 |
| 内存 | 32 GB(威刚 DDR5 6000MHz16GB x2) |
| 硬盘 | GAMMIX S70 SE(1024 GB/固态硬盘) |
| Python | 3.9.15 |
| Numpy | 1.23.4 |
| pip | 22.3.1 |
| Torch | 1.13.1 |
| modelscope | 1.12.0 |
除了PyTorch,还需要安装modelscope和一系列依赖:
pip install modelscope
pip install transformers==4.32.0 accelerate tiktoken einops scipy transformers_stream_generator==0.0.4 peft deepspeed根据不同的系统和硬件配置,安装过程可能存在差异。建议仔细阅读官方文档,并根据实际情况进行调整。

3. 基础代码运行:体验多轮对话
完成环境搭建和模型下载后,就可以运行官方提供的示例代码,体验多轮对话功能。以下是一个精简版的代码:
from modelscope import AutoModelForCausalLM, AutoTokenizer
model_path = "你的模型存放目录"
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto", trust_remote_code=True).eval()
history=None
while True:
message = input('User:')
response, history = model.chat(tokenizer, message, history=history)
print('System:',end='')
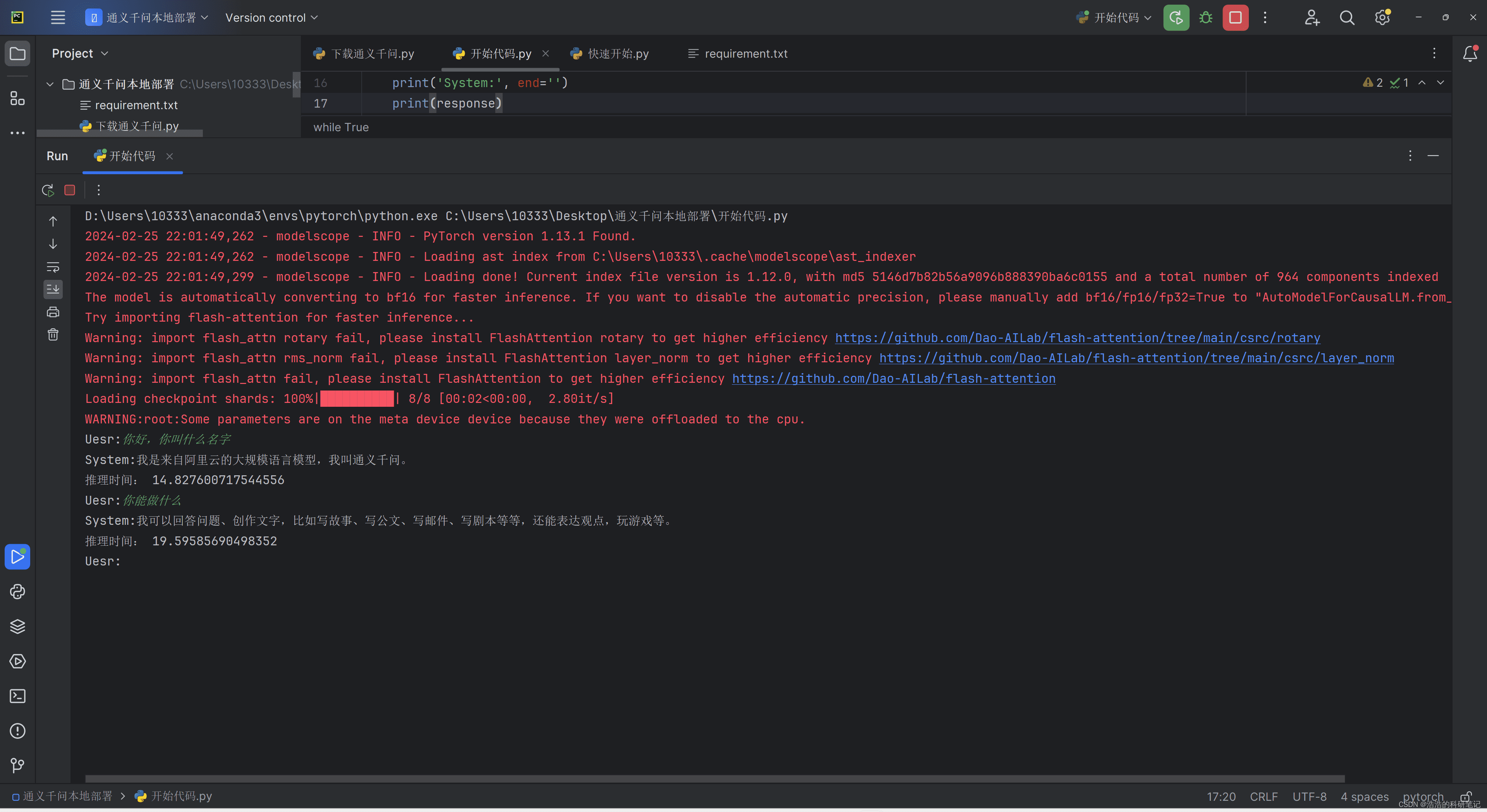
print(response)这段代码加载本地模型和分词器,并进入一个无限循环,持续接收用户输入,生成模型回应。device_map参数用于指定运行设备,auto表示自动选择GPU或CPU。tokenizer负责将文本转换为模型可理解的格式。
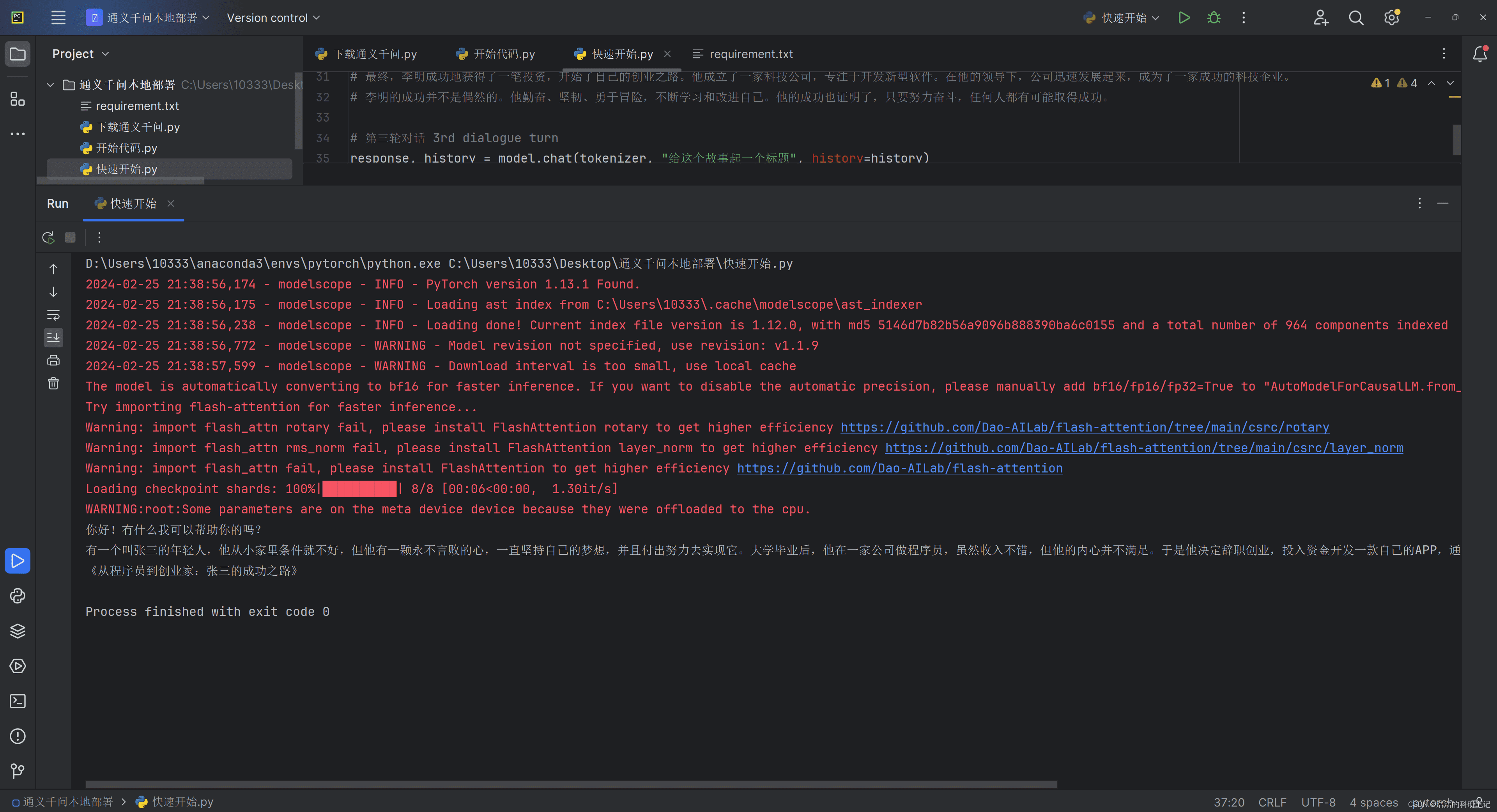

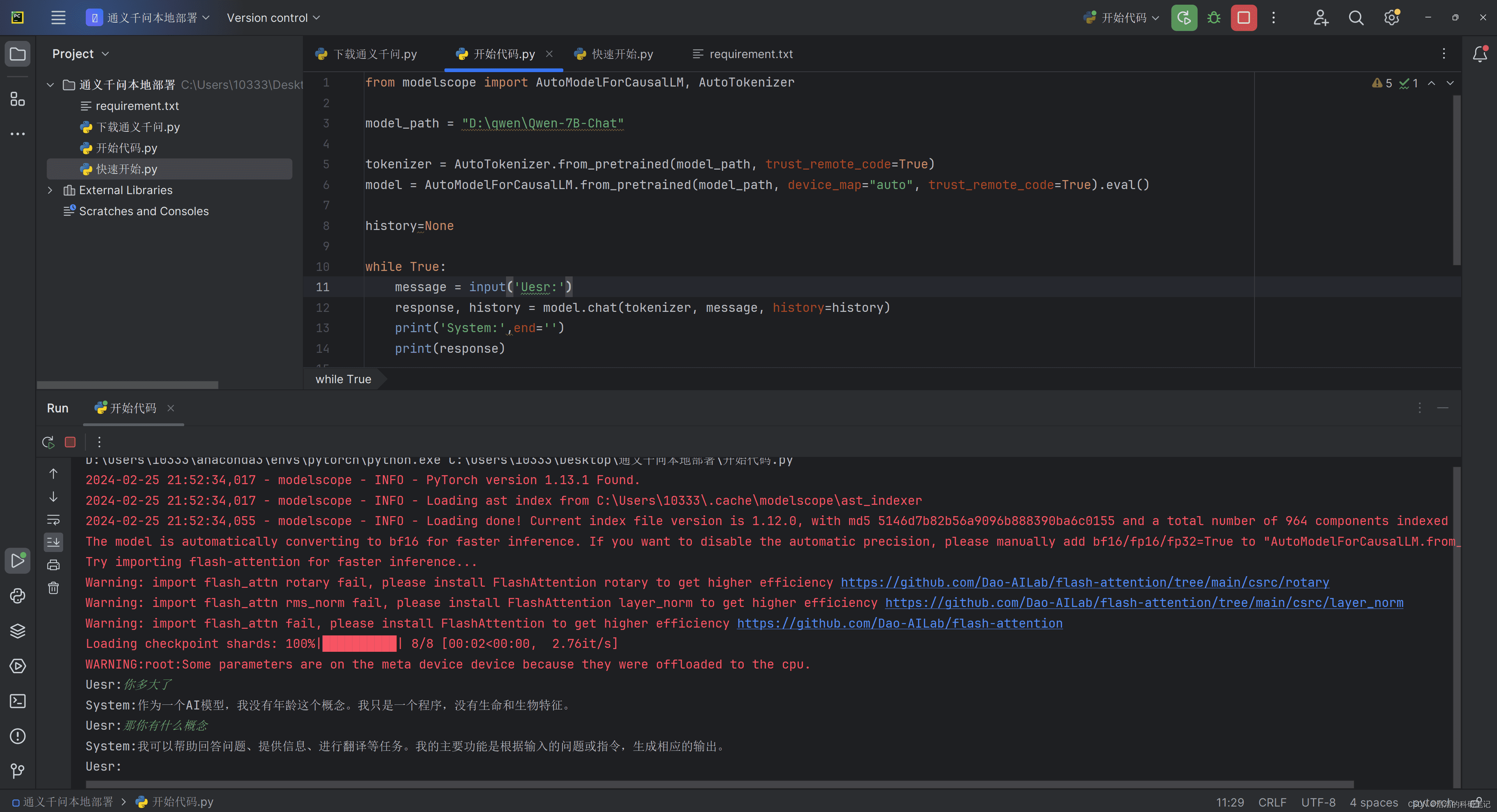
然而,直接运行上述代码会发现,模型生成速度较慢,用户体验不佳。尤其是在输出较长文本时,等待时间会更长。
4. 流式输出:提升用户体验的关键
为了解决生成速度慢的问题,可以采用流式输出的方式,即模型逐字或逐句生成文本,并实时显示给用户。这需要借助swift库。
4.1 Swift库的安装与使用
首先,安装swift库:
pip install ms-swift注意,是ms-swift,而不是swift。安装错误的库会导致后续代码无法正常运行。
官方提供了一个流式输出的示例代码:

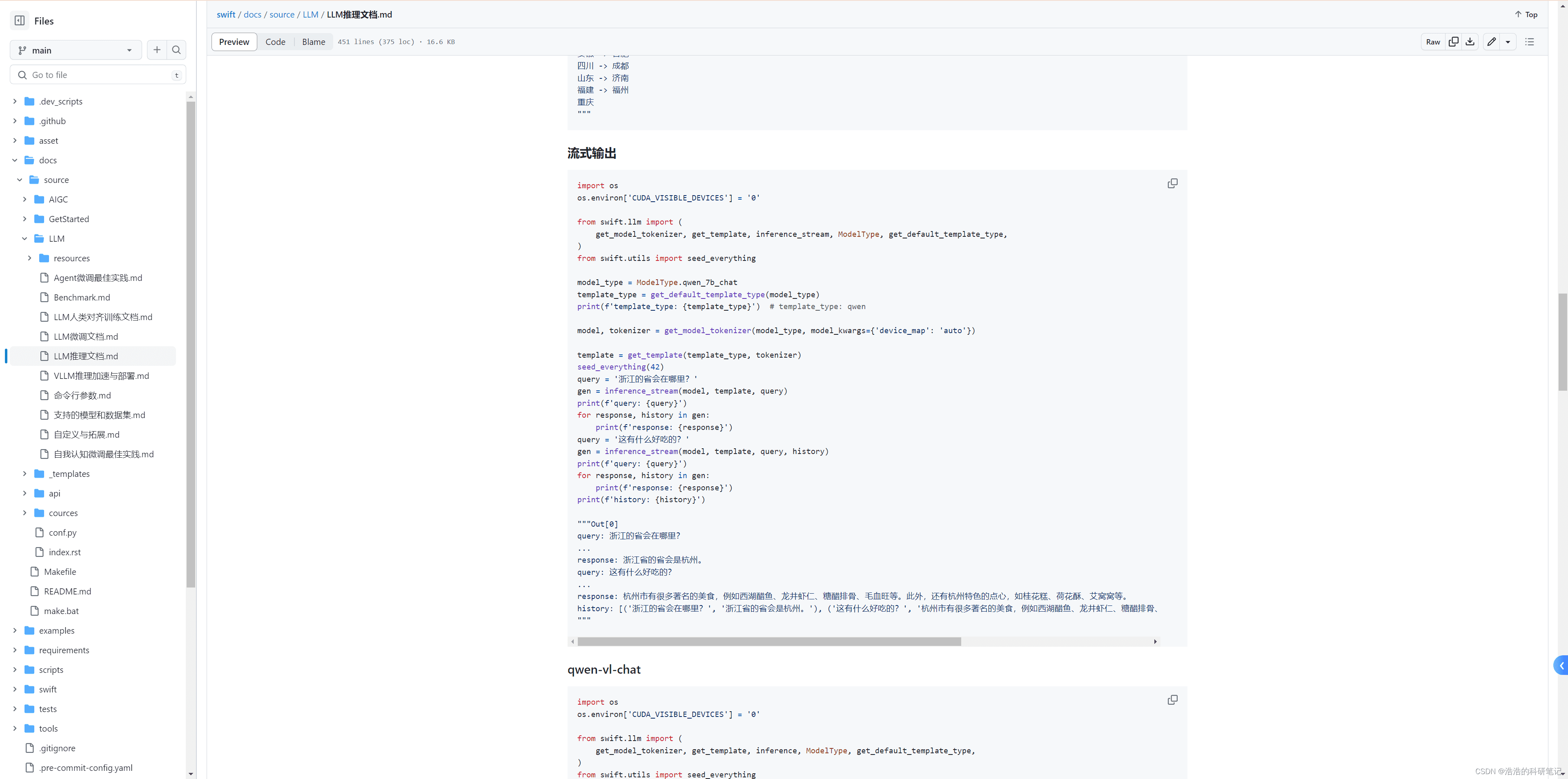
该代码集成了模型下载和推理功能。首次运行时,会自动下载模型文件。但该代码无法在无网络环境下运行。
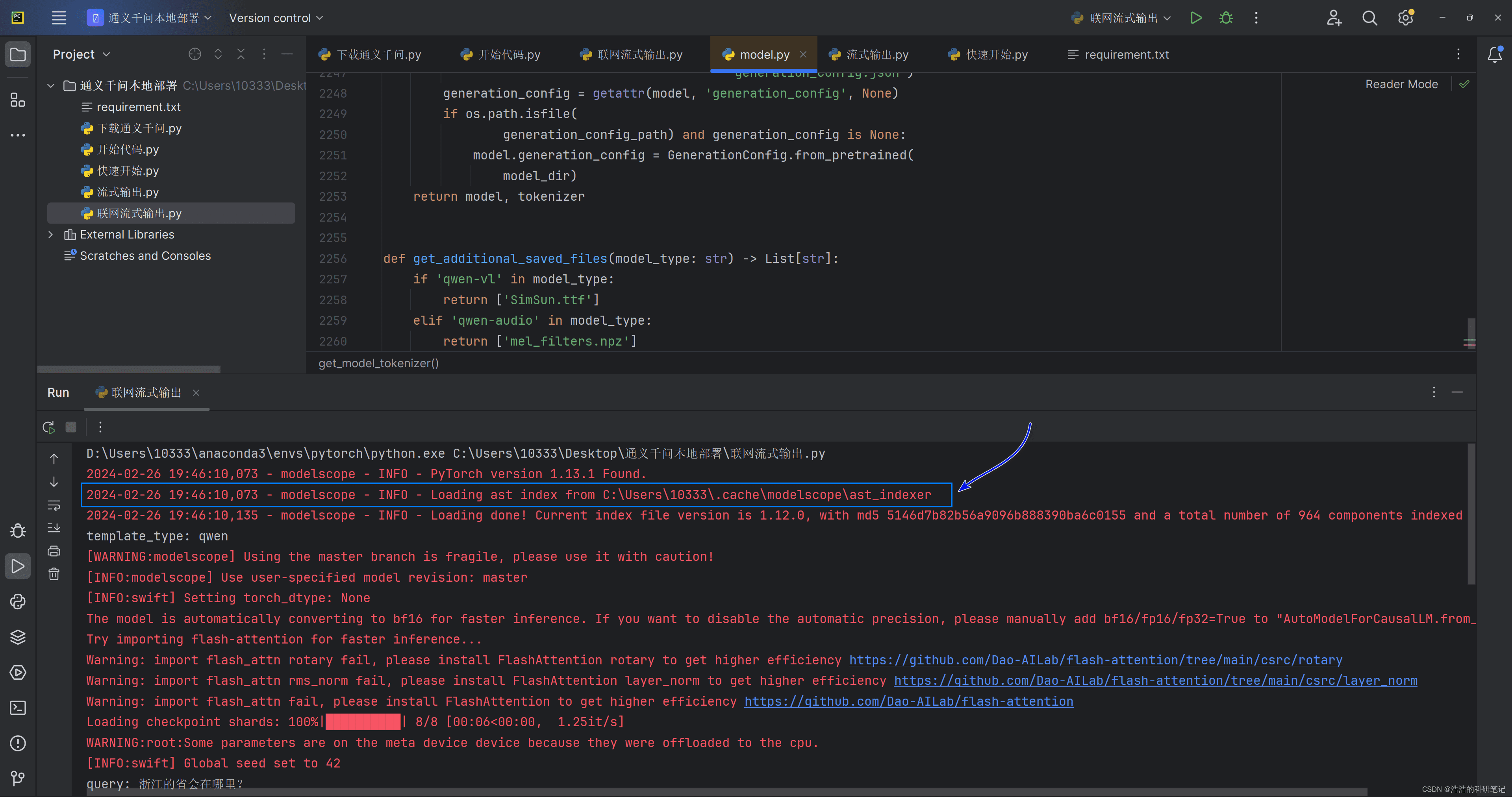
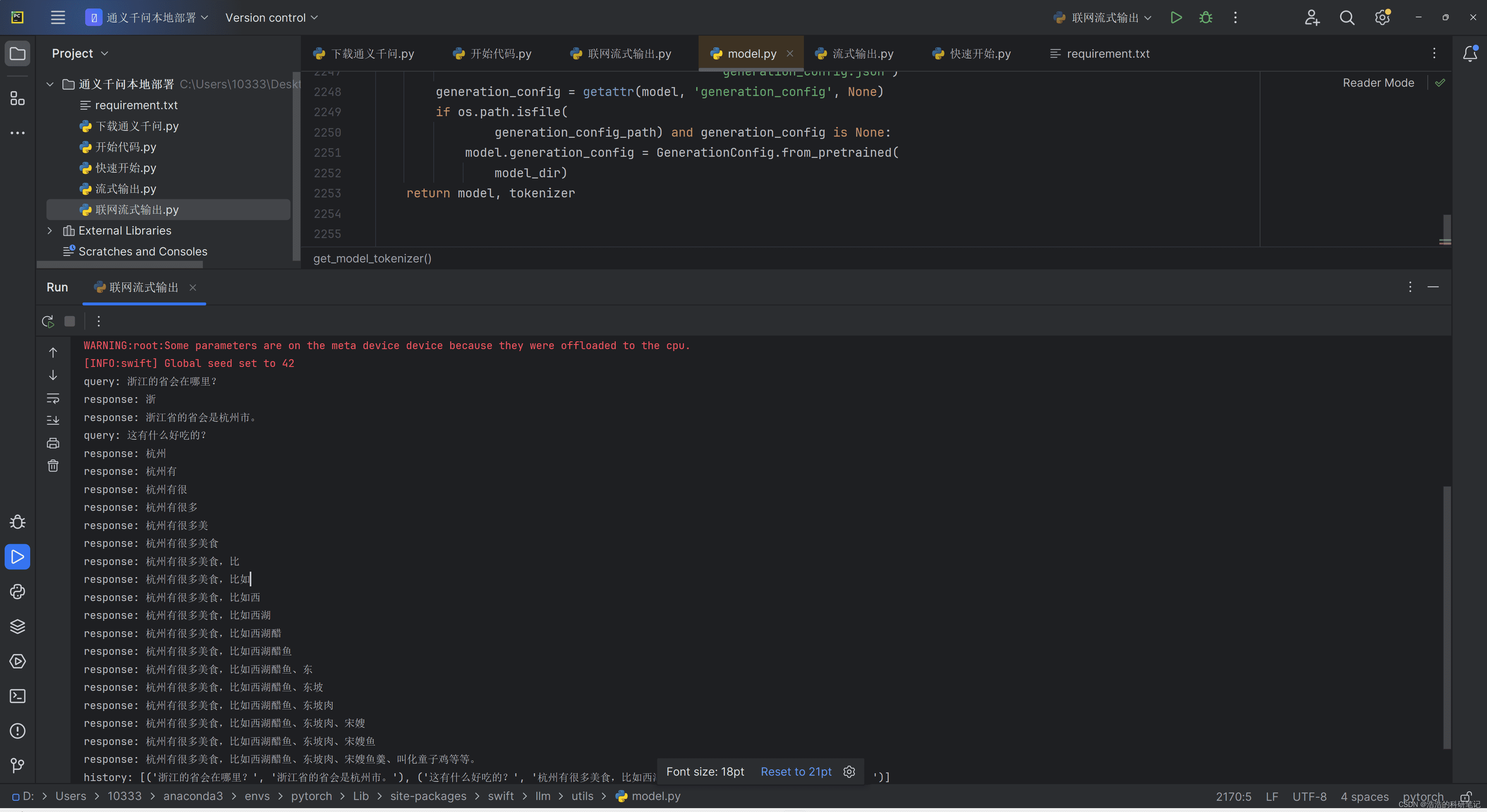
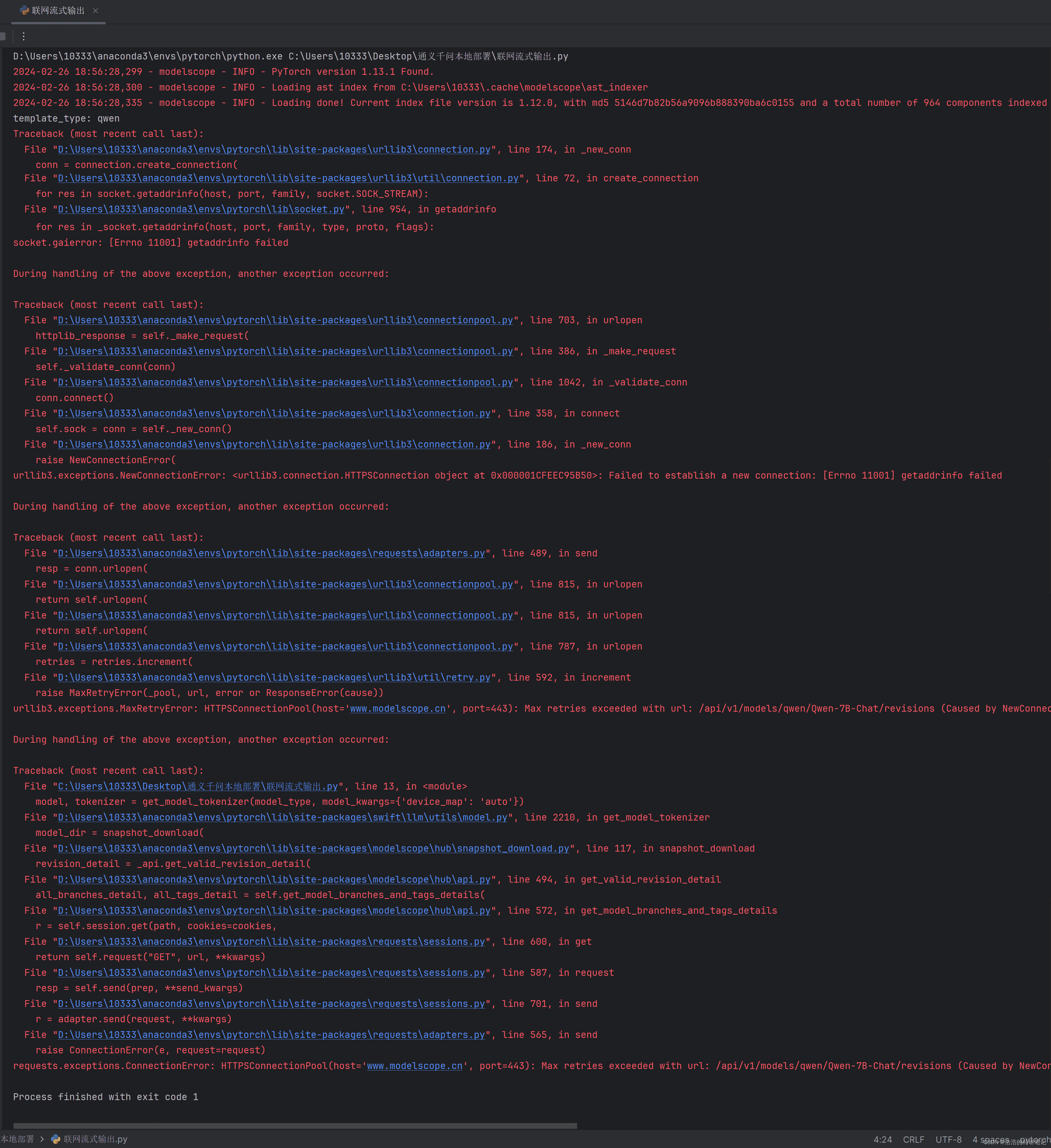
为了实现离线流式输出,需要对代码进行改造。以下是一个可行的方案:
from modelscope import AutoModelForCausalLM, AutoTokenizer
from swift.llm import inference_stream, get_template
model_path = "你的模型存放目录"
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto", trust_remote_code=True).eval()
template_type = 'qwen'
template = get_template(template_type, tokenizer)
history = None
while True:
query = input('User:')
gen = inference_stream(model, template, query, history)
print(f'System:', end="")
for response, h in gen:
print(response[before_len:],end="")
before_len = len(response)
history = h
print()这段代码使用swift中的inference_streamAPI进行流式输出,并加载本地模型。before_len变量用于记录上一次输出的文本长度,避免重复输出。
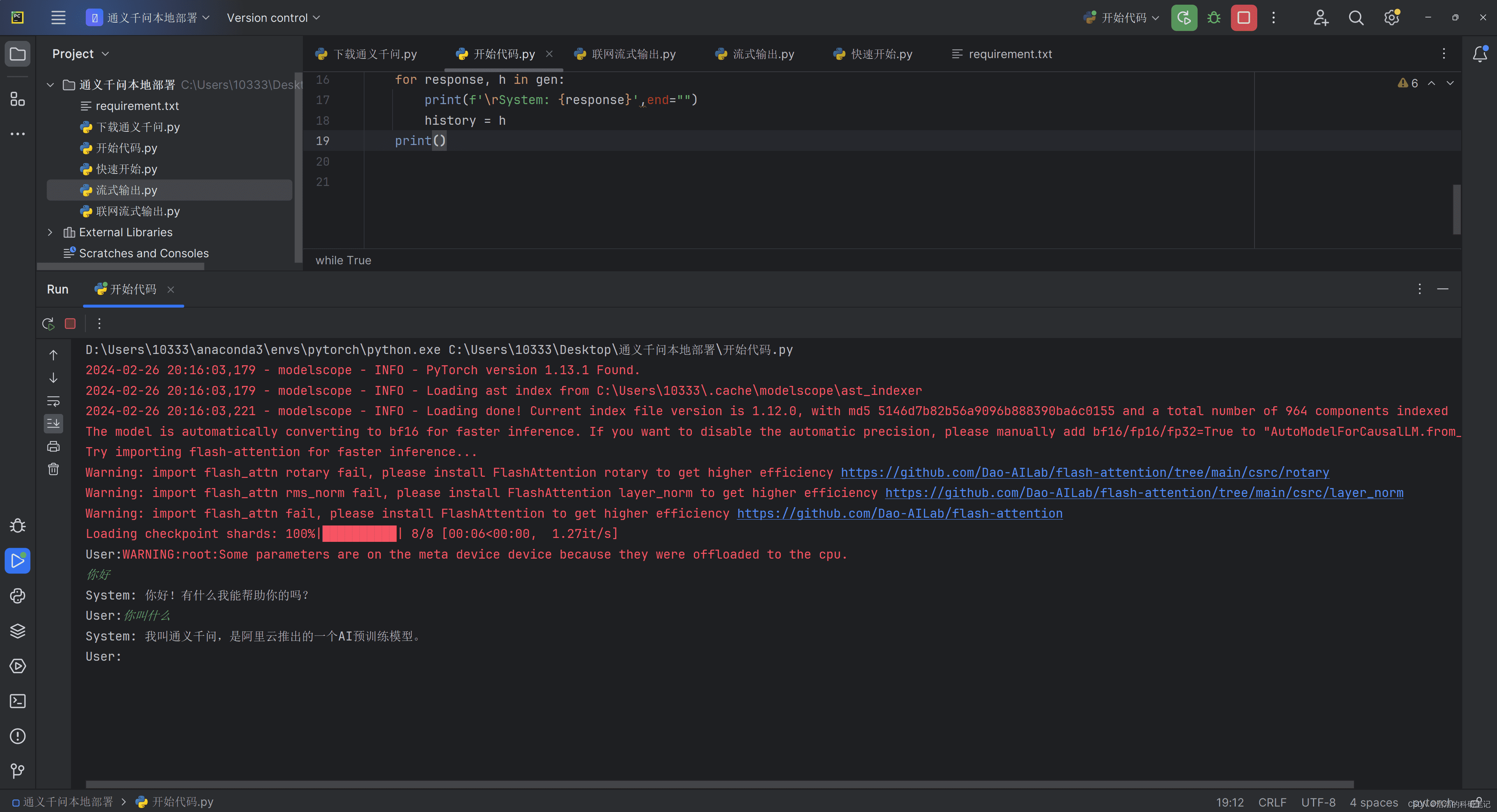
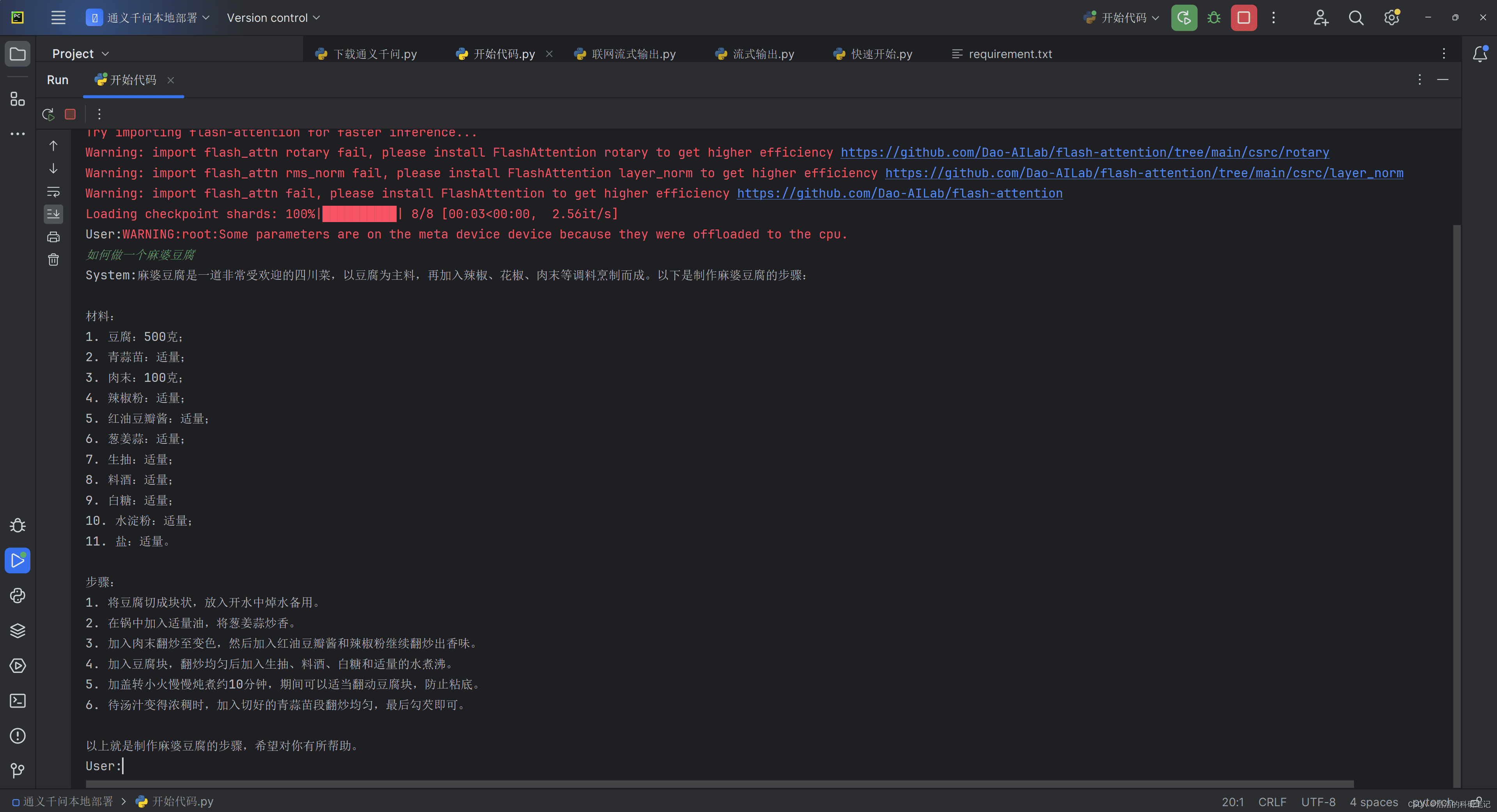
4.2 代码详解
- 导入必要的库:
modelscope用于加载模型和分词器,swift.llm包含流式输出所需的API。 - 指定模型路径:
model_path变量定义了本地模型文件的存放路径。 - 加载模型和分词器:使用
AutoTokenizer.from_pretrained和AutoModelForCausalLM.from_pretrained加载模型和分词器。device_map="auto"表示自动选择设备运行模型。 - 获取模板:
get_template函数用于获取特定类型的模板,用于定义模型的输入格式。 - 初始化历史记录:
history变量用于存储对话历史。 - 进入无限循环:持续接收用户输入并生成回应。
- 调用
inference_stream函数:传入模型、模板、用户查询和历史记录,开始生成模型的回应。 - 逐字输出:遍历生成器
gen的输出,打印新生成的回应部分,并更新已打印文本的长度和历史记录。
5. 环境配置:详细步骤(2024.7.20更新)
由于电脑重装系统,重新部署时遇到了一些问题。以下是详细的部署步骤,供参考:
- 配置清华源:
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple- 创建conda虚拟环境:
conda create --name llm python=3.10建议选择Python 3.10版本。
- 安装modelscope:
pip install modelscope- 安装PyTorch:
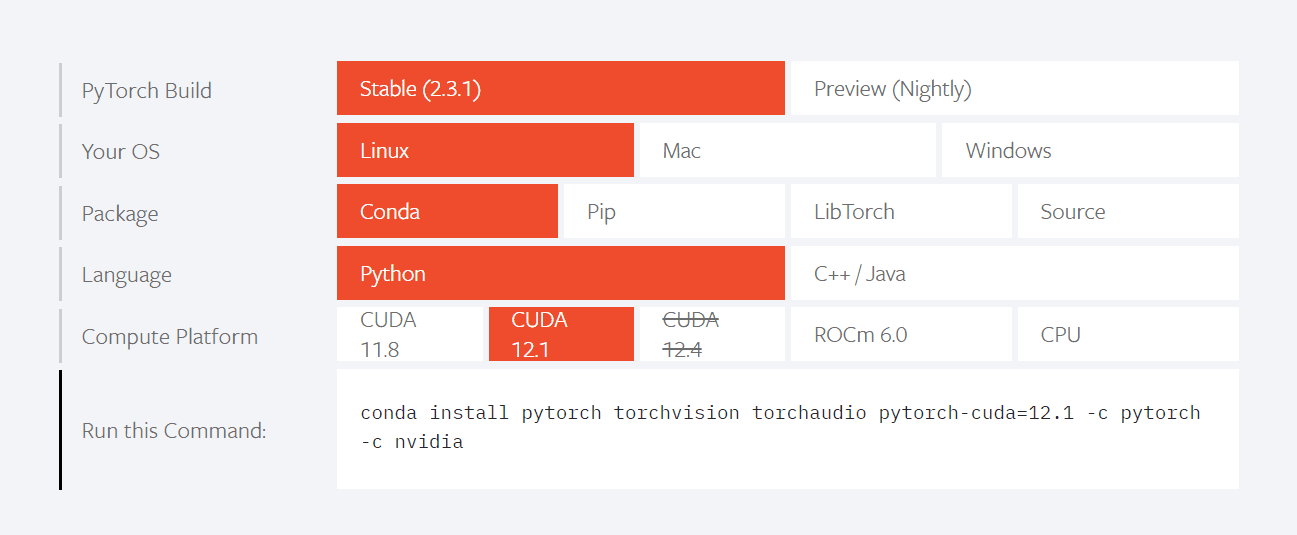
conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia根据CUDA版本选择合适的安装命令。
- 安装依赖:
pip install transformers==4.32.0 accelerate tiktoken einops scipy transformers_stream_generator==0.0.4 peft- 安装swift:
pip install ms-swift- 修复Hugging Face bug:
conda install chardet
最终,使用pip list命令查看已安装的库及其版本信息。
6. 其他模型测试与问题修复
6.1 Qwen1.5-1.8B模型测试
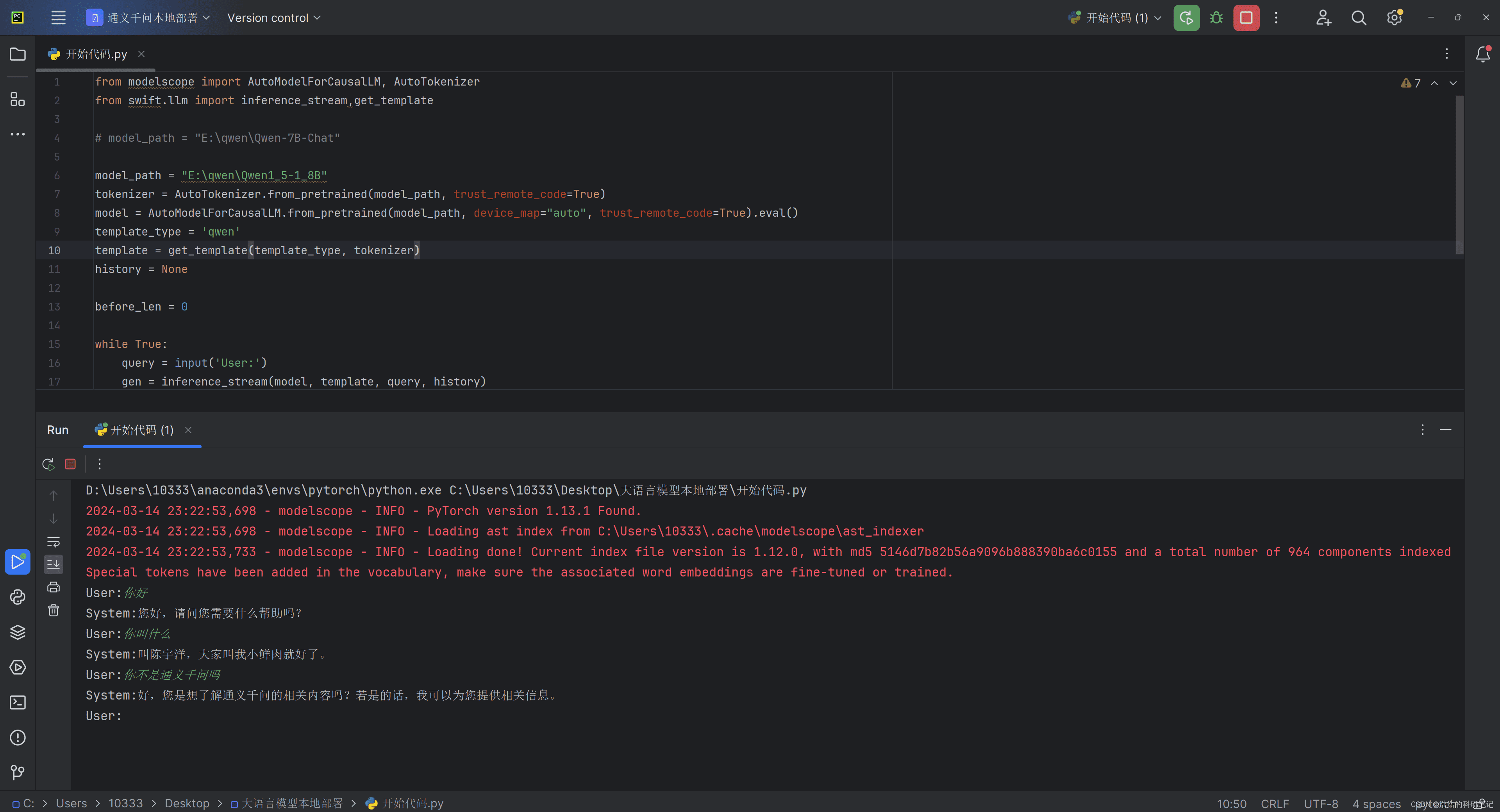
Qwen1.5-1.8B模型可以使用相同的代码运行,只需修改模型路径即可。
https://modelscope.cn/models/qwen/Qwen1.5-1.8B/files
但该模型的性能较差,无法完成复杂的任务。
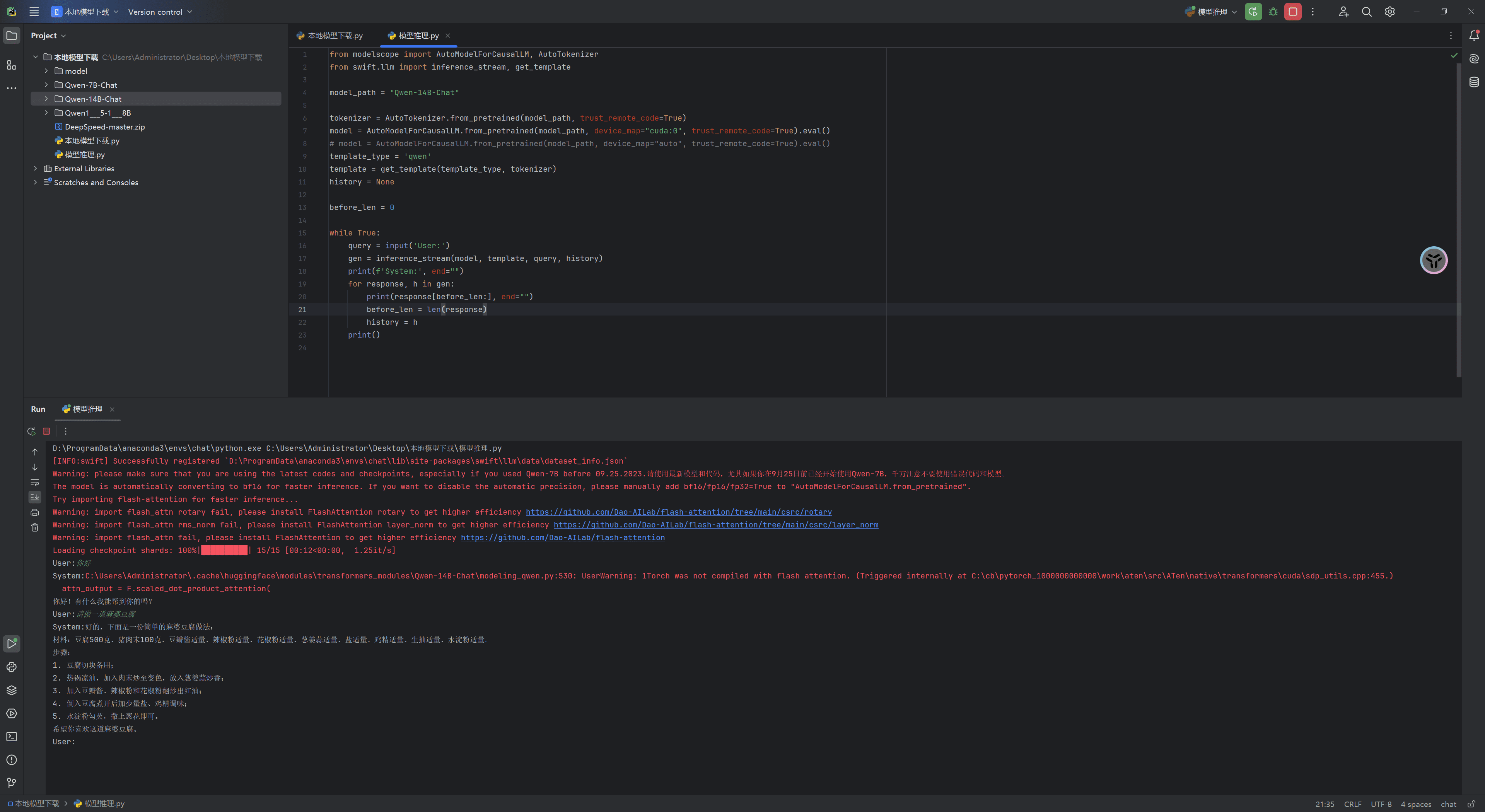
6.2 Qwen-14B-chat模型测试
Qwen-14B-chat模型也可以使用相同的代码运行。虽然推理速度较慢,但在4070Ti显卡上可以带动。
7. 相关文档链接
- Qwen-7B-Chat模型介绍下载地址:https://modelscope.cn/models/qwen/Qwen-7B-Chat/summary
- swift文档地址:https://github.com/modelscope/swift/blob/main/docs/source/LLM/LLM%E6%8E%A8%E7%90%86%E6%96%87%E6%A1%A3.md
通过本文,你应该能够成功在本地部署通义千问,并实现流式输出。希望这些经验能帮助你更好地探索大语言模型的魅力。后续,我将继续分享更多关于大语言模型的实践经验,敬请期待。








