
在人工智能领域,多模态大语言模型(MLLM)正逐渐崭露头角,它们不仅能够理解文本,还能处理图像等多媒体信息。由北京交通大学、华中科技大学和清华大学联合推出的Migician模型,正是这一领域的杰出代表。Migician专为自由形式的多图像定位(Multi-Image Grounding, MIG)任务设计,通过大规模训练数据集MGrounding-630k,实现了在多幅图像中精确定位与查询相关的视觉区域的能力。本文将深入探讨Migician的技术原理、功能特点、应用场景及其重要意义。
多图像定位任务旨在根据用户的查询(可以是文本描述、图像或两者的组合),在多张图像中找到对应的目标对象或区域。这一任务在实际应用中具有广泛的需求,例如自动驾驶、安防监控、机器人交互等领域。传统的解决方案往往需要将任务分解为多个子任务,例如先生成文本描述,然后再进行定位。这种方法不仅复杂,而且容易产生误差累积。而Migician则采用端到端的模型设计,直接在多图像场景中进行推理,从而避免了传统方法的弊端。
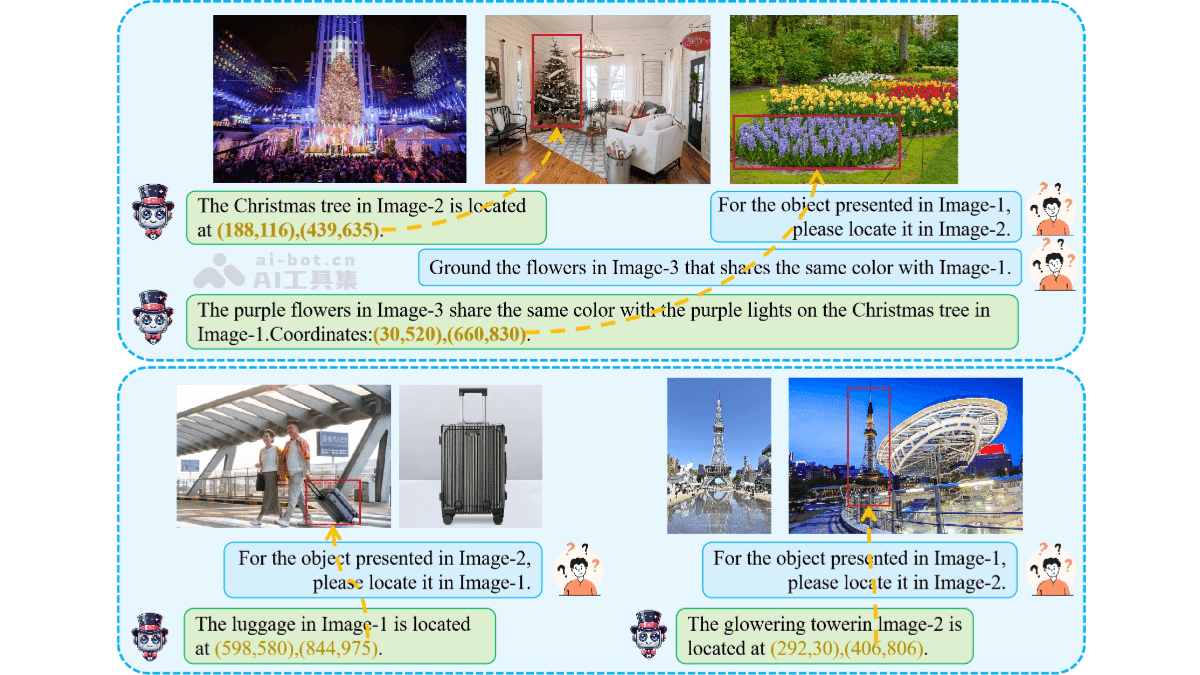
Migician的核心功能在于其强大的跨图像定位能力。它能够在多幅图像中找到与查询相关的对象或区域,并给出其精确位置坐标。更重要的是,Migician支持灵活的输入形式,用户可以使用文本、图像或两者的组合作为查询条件。例如,用户可以输入“在图2中找到与图1相似的物体,但颜色不同”这样的复杂指令,Migician也能准确地完成定位任务。
除了跨图像定位,Migician还支持多种与多图像相关的任务,如对象跟踪、差异识别、共同对象定位等。这使得Migician在处理复杂视觉场景时具有更高的灵活性和适应性。此外,Migician基于端到端的模型设计,能够直接在多图像场景中进行推理,避免了传统方法中的多步推理和错误传播问题,从而提高了定位的准确性和效率。
Migician的技术原理主要包括以下几个方面:
端到端的多图像定位框架: Migician采用端到端的模型架构,直接处理多图像定位任务。这种架构避免了传统方法中将任务分解为多个子任务的复杂性和效率问题。通过同时理解多幅图像的内容,Migician能够根据查询直接输出目标对象的位置。
大规模指令调优数据集(MGrounding-630k): 为了训练Migician的定位能力,研究团队构建了一个包含超过63万条多图像定位任务的数据集MGrounding-630k。该数据集涵盖了多种任务类型,如静态差异定位、共同对象定位、对象跟踪等。结合自由形式的指令,Migician能够学习到多样化的定位能力。
两阶段训练方法: Migician的训练过程分为两个阶段:
- 第一阶段:模型在多种多图像任务上进行训练,学习基本的多图像理解和定位能力。
- 第二阶段:基于自由形式的指令调优,提升模型在复杂查询下的定位能力,并保持对多样化任务的适应性。
多模态融合与推理: Migician结合视觉和语言模态的信息,通过多模态融合实现对复杂查询的理解和定位。它能够处理抽象的视觉语义信息,例如通过对比、相似性或功能关联定位目标对象。
模型合并技术: 为了进一步优化模型性能,研究团队采用了模型合并技术,将不同训练阶段的权重进行平均,从而提高整体的泛化能力。
Migician在多个领域都具有广泛的应用前景:
自动驾驶: 在自动驾驶系统中,Migician可以用于快速定位车辆周围的目标,如行人、车辆、交通标志等。通过多视角感知和动态目标跟踪,Migician可以提高自动驾驶系统的安全性和可靠性。
安防监控: 在安防监控领域,Migician可以联动多个摄像头,识别异常行为或目标。例如,它可以分析人群聚集、快速移动等异常情况,并及时发出警报。
机器人交互: 在机器人交互应用中,Migician可以用于精准定位目标物体,例如在仓库中定位货物、在家庭环境中定位物品等。这有助于机器人在复杂环境中完成抓取、导航等任务。
图像编辑: Migician可以分析多幅图像的内容,实现对象替换、删除或创意内容生成。例如,可以将一张照片中的人物替换到另一张照片中,或者根据用户的描述生成新的图像。
医疗影像: 在医疗影像领域,Migician可以融合多模态影像,快速定位病变区域或异常组织。例如,可以将CT图像和MRI图像结合起来,提高肿瘤的检出率和诊断准确性。
Migician的推出,为多模态模型在复杂视觉场景中的应用提供了新的思路。它不仅能够提高多图像定位的准确性和效率,还能够支持多种与多图像相关的任务。随着人工智能技术的不断发展,Migician有望在自动驾驶、安防监控、机器人交互、图像编辑、医疗影像等领域发挥更大的作用。
Migician的出现,是人工智能领域在多模态学习方向上的一次重要突破。它标志着机器不仅可以理解文本,还能通过视觉信息进行更深入的分析和推理。这种能力的提升,将为人工智能在各个领域的应用带来更广阔的前景。未来,我们可以期待更多类似Migician的创新模型出现,推动人工智能技术不断向前发展。
多模态大语言模型,如Migician,其核心优势在于能够融合来自不同模态的信息。在传统的自然语言处理任务中,模型主要依赖文本数据进行学习和推理。然而,现实世界中的信息往往是多模态的,例如,一张图片可能包含丰富的视觉信息,一段语音可能包含情感信息。通过融合多模态信息,模型可以更全面、更准确地理解现实世界。
在Migician的例子中,模型同时处理图像和文本信息,从而实现更精确的多图像定位。例如,用户可以通过文本描述指定要查找的目标对象,模型则通过分析多张图像,找到与描述相符的对象。这种能力在很多实际应用中都非常有用。例如,在自动驾驶中,模型可以同时分析摄像头拍摄的图像和雷达传感器获取的数据,从而更准确地识别道路上的障碍物。
多模态模型的训练面临着诸多挑战。首先,不同模态的数据具有不同的特点和结构。例如,图像数据是像素点的集合,文本数据是字符或词语的序列。如何将这些不同类型的数据有效地融合在一起,是一个重要的研究问题。其次,多模态数据的标注成本通常很高。例如,要训练一个能够理解图像和文本的模型,需要大量的图像-文本对数据。如何降低标注成本,也是一个重要的研究方向。
为了解决这些挑战,研究人员提出了多种多模态融合方法。例如,一种常见的方法是将不同模态的数据分别编码成向量表示,然后将这些向量表示进行融合。另一种方法是使用注意力机制,让模型自动学习不同模态之间的重要性关系。在数据标注方面,研究人员正在探索半监督学习、弱监督学习等方法,以降低标注成本。
总的来说,多模态大语言模型是人工智能领域的一个重要发展方向。Migician作为其中的杰出代表,展示了多模态模型在多图像定位任务中的巨大潜力。随着技术的不断进步,我们有理由相信,多模态模型将在更多领域发挥重要作用,为人类带来更智能、更便捷的服务。
Migician的成功,也离不开开源社区的贡献。研究团队将Migician的代码和模型开源,为其他研究人员和开发者提供了宝贵的资源。这种开放共享的精神,有助于推动人工智能技术的快速发展。我们期待未来有更多的研究团队能够加入到多模态学习的研究中来,共同推动人工智能技术的进步。








