
在人工智能领域,模型推理性能的提升一直是研究者和开发者关注的焦点。近日,DeepSeek开源周的首日便带来了一项重磅技术——FlashMLA,这是一款专为英伟达Hopper架构GPU设计的高效多层注意力(Multi-Layer Attention)解码内核。该技术的开源,无疑为大模型推理性能的提升注入了新的活力。FlashMLA尤其针对变长序列场景进行了深度优化,能够显著提升大模型在处理此类任务时的推理效率。变长序列在自然语言处理、语音识别等领域广泛存在,例如,不同长度的文本段落、不同时长的语音片段等。FlashMLA的优化,使得大模型能够更高效地处理这些实际应用场景,从而提升整体性能。
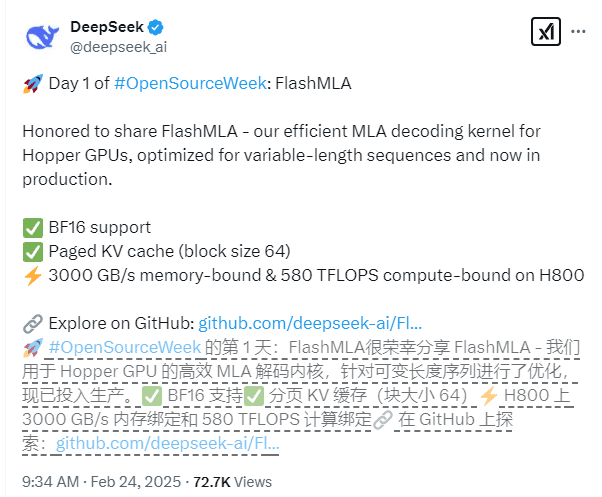
FlashMLA的核心技术特性主要体现在以下几个方面:
BF16精度支持: FlashMLA全面支持BF16(Brain Floating Point 16)精度,这是一种针对深度学习优化的16位浮点格式。相比于传统的FP32(32位浮点)精度,BF16精度可以在一定程度上降低内存占用和计算复杂度,从而加速模型训练和推理过程。同时,BF16精度在保证模型性能的前提下,能够提供更高的计算效率。
页式键值缓存(Paged KV Cache): FlashMLA采用了块大小为64的页式键值缓存系统,这是一种更精细化的内存管理方式。传统的键值缓存通常采用固定大小的块,而页式键值缓存则可以根据实际需求动态分配内存,从而更有效地利用GPU资源。通过更精确的内存管理,FlashMLA能够减少内存碎片,提高内存利用率,并最终提升推理性能。页式键值缓存,可以动态的对GPU的资源进行分配,有效的提升推理的性能。
性能表现: 在CUDA 12.6平台上,FlashMLA在H800 SXM5 GPU上取得了令人瞩目的成绩。在内存受限场景下,FlashMLA的处理速度高达3000GB/s,这意味着它可以在每秒钟处理高达3000GB的数据量。在计算受限场景下,FlashMLA的算力水平达到了580 TFLOPS(每秒万亿次浮点运算),这表明它具有强大的计算能力,能够高效地执行复杂的模型推理任务。这个性能是非常强悍的。
FlashMLA项目已经过生产环境的验证,展现出优异的稳定性。这意味着该技术不仅在实验室环境中表现出色,而且在实际应用中也能够稳定可靠地运行。这种稳定性对于大模型的部署和应用至关重要,因为它能够保证模型在长时间运行过程中不会出现意外故障或性能下降。
DeepSeek团队表示,FlashMLA的设计借鉴了FlashAttention 2&3和cutlass等项目的优秀经验,并在其基础上实现了创新突破。FlashAttention是一种高效的注意力机制,它通过减少内存访问来加速计算过程。Cutlass是英伟达开源的CUDA C++模板库,用于实现高性能的矩阵乘法。FlashMLA借鉴了这些项目的优点,并在此基础上进行了改进和优化,从而实现了更高的性能。
为了方便开发者使用,DeepSeek团队提供了简单的安装命令:只需执行"python setup.py install"即可完成安装。安装完成后,开发者可以运行测试脚本"python tests/test_flash_mla.py"来体验FlashMLA的性能。这种简便的安装和测试方式,降低了开发者的使用门槛,使得更多的人能够快速上手并利用FlashMLA来加速大模型推理。
从技术角度来看,FlashMLA的开源对于大模型推理领域具有重要的意义。它不仅提供了一种高效的解决方案,而且还为研究者和开发者提供了一个学习和借鉴的平台。通过研究FlashMLA的源代码,人们可以深入了解其设计思想和实现细节,从而为自己的项目带来灵感和改进。
FlashMLA的开源,是DeepSeek在推动人工智能技术发展方面迈出的重要一步。它不仅展示了DeepSeek在技术创新方面的实力,而且也体现了其开放合作的态度。相信在未来,FlashMLA将会在大模型推理领域发挥越来越重要的作用,为人工智能应用带来更强大的动力。
FlashMLA技术原理剖析
为了更深入地理解FlashMLA的优势,我们需要对其技术原理进行更详细的剖析。FlashMLA的核心在于其多层注意力机制的优化,这种优化体现在以下几个关键方面:
1. 注意力机制的改进
注意力机制是大模型中的核心组成部分,它允许模型在处理序列数据时,能够关注到不同的部分并赋予不同的权重。传统的注意力机制在计算过程中需要大量的内存访问,这成为了性能瓶颈。FlashMLA通过改进注意力机制的计算方式,减少了内存访问,从而提高了计算效率。
具体来说,FlashMLA采用了类似于FlashAttention的思想,将注意力矩阵分块存储,并在计算过程中利用GPU的共享内存进行加速。这种分块计算的方式,可以减少对全局内存的访问,从而降低延迟并提高吞吐量。FlashMLA对注意力的机制进行了升级和改进。
2. 内存管理优化
内存管理是大模型推理性能的关键因素之一。FlashMLA采用了页式键值缓存(Paged KV Cache)系统,对内存进行更精细化的管理。传统的键值缓存通常采用固定大小的块,这种方式容易导致内存碎片和浪费。页式键值缓存则可以根据实际需求动态分配内存,从而更有效地利用GPU资源。
此外,FlashMLA还采用了内存池技术,预先分配一定大小的内存块,并在需要时从内存池中获取。这种方式可以避免频繁的内存分配和释放操作,从而减少系统开销并提高性能。通过对内存的精细化管理,FlashMLA可以充分利用GPU资源,提高推理效率。
3. BF16精度支持的优势
FlashMLA全面支持BF16精度,这为模型推理带来了多方面的优势。首先,BF16精度可以降低内存占用,使得模型能够更好地适应内存受限的场景。其次,BF16精度可以减少计算复杂度,从而加速计算过程。最重要的是,BF16精度在保证模型性能的前提下,能够提供更高的计算效率。
为了充分利用BF16精度的优势,FlashMLA在底层CUDA代码中进行了大量的优化。例如,它采用了专门针对BF16精度的SIMD指令,以及优化的数据排布方式。通过这些优化,FlashMLA能够在BF16精度下实现更高的性能。
FlashMLA的应用场景展望
FlashMLA作为一款高效的多层注意力解码内核,具有广泛的应用前景。以下是一些典型的应用场景:
1. 自然语言处理
自然语言处理(NLP)是大模型应用最广泛的领域之一。FlashMLA可以用于加速各种NLP任务,例如文本生成、机器翻译、文本分类等。通过提高推理效率,FlashMLA可以使得这些任务能够更快地完成,从而提升用户体验。
例如,在机器翻译任务中,FlashMLA可以加速解码过程,使得翻译结果能够更快地呈现给用户。在文本生成任务中,FlashMLA可以提高生成速度,使得模型能够更快地生成高质量的文本内容。
2. 语音识别
语音识别是另一个重要的应用领域。FlashMLA可以用于加速语音识别模型的推理过程,从而提高识别速度和准确率。通过提高推理效率,FlashMLA可以使得语音识别系统能够更快地响应用户的语音输入。
例如,在语音助手应用中,FlashMLA可以加速语音识别过程,使得助手能够更快地理解用户的指令。在语音转文本应用中,FlashMLA可以提高转录速度,使得用户能够更快地将语音内容转换为文本。
3. 图像处理
图像处理也是大模型应用的重要领域之一。FlashMLA可以用于加速各种图像处理任务,例如图像分类、目标检测、图像生成等。通过提高推理效率,FlashMLA可以使得这些任务能够更快地完成,从而提升用户体验。
例如,在图像分类任务中,FlashMLA可以加速模型推理,使得图像能够更快地被分类。在目标检测任务中,FlashMLA可以提高检测速度,使得模型能够更快地识别出图像中的目标。
4. 其他领域
除了上述领域之外,FlashMLA还可以应用于其他各种需要大模型推理的场景。例如,在金融领域,FlashMLA可以用于加速风险评估模型的推理过程。在医疗领域,FlashMLA可以用于加速疾病诊断模型的推理过程。在自动驾驶领域,FlashMLA可以用于加速感知模型的推理过程。
总之,FlashMLA作为一款高效的多层注意力解码内核,具有广泛的应用前景。相信在未来,它将会在各个领域发挥越来越重要的作用,为人工智能应用带来更强大的动力。
总结与展望
DeepSeek开源的FlashMLA,无疑是大模型推理领域的一项重要进展。它通过对多层注意力机制的优化,实现了更高的推理性能和更低的资源消耗。FlashMLA的开源,不仅为开发者提供了一个强大的工具,也为研究者提供了一个学习和借鉴的平台。相信在未来,FlashMLA将会在大模型推理领域发挥越来越重要的作用,推动人工智能技术的不断发展。
随着人工智能技术的不断进步,大模型将会在越来越多的领域得到应用。而FlashMLA的出现,为大模型的部署和应用提供了更强大的支持。我们期待着FlashMLA在未来能够取得更大的突破,为人工智能领域带来更多的惊喜。








