
在人工智能领域,Meta AI 团队的最新研究成果——视频联合嵌入预测架构(V-JEPA)模型,无疑为视频理解带来了新的突破。这一创新模型旨在模仿人类视觉系统处理信息的方式,即通过识别物体和运动模式来理解周围环境。其核心在于揭示无监督学习背后的基本原理,并提出了一个关键假设:连续感官输入的表示应该能够相互预测。
早期的研究主要通过慢特征分析和谱技术来保持时间一致性,从而防止表示崩溃。而当前的方法则更多地结合了对比学习和掩蔽建模,以确保表示在时间上的不断演变。这些现代技术不仅关注时间不变性,还通过训练预测网络来映射不同时间步的特征关系,进而提升整体表现。特别是在处理视频数据时,时空掩蔽技术的应用显著提高了学习表示的质量。
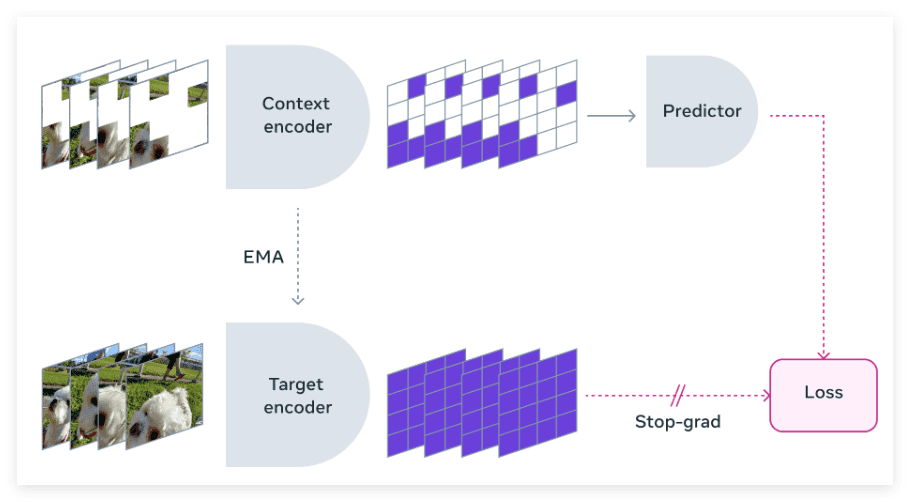
Meta AI 团队与多家知名机构紧密合作,共同开发了 V-JEPA 模型。该模型以特征预测为核心,专注于无监督视频学习。与传统方法不同,V-JEPA 不依赖于预训练编码器、负样本、重建或文本监督,而是直接从原始视频数据中学习。在训练过程中,V-JEPA 使用了超过两百万个公共视频,并在运动和外观任务上取得了显著的成果,更令人印象深刻的是,这些成果无需进行额外的微调。
V-JEPA 的训练方法独特而高效,它通过视频数据构建对象中心的学习模型。首先,神经网络从视频帧中提取对象中心的表示,从而捕捉运动和外观特征。这些表示随后通过对比学习得到进一步的增强,以提高对象的可分性。接下来,基于Transformer的架构被用于处理这些表示,以模拟对象之间的时间交互。整个框架通过大规模数据集的训练,以优化重建准确性和跨帧一致性。

为了验证 V-JEPA 的性能,研究人员将其与像素预测方法进行了比较。结果显示,V-JEPA 在多个方面表现优越,特别是在冻结评估中。尽管在 ImageNet 分类任务中略有不足,但经过微调后,V-JEPA 在使用更少的训练样本的情况下,超越了基于 ViT-L/16 模型的其他方法。尤其值得一提的是,V-JEPA 在运动理解和视频任务上表现出色,不仅训练效率更高,而且在低样本设置下仍然能够保持较高的准确性。
V-JEPA 模型的成功,展示了特征预测作为无监督视频学习独立目标的有效性。该模型在各类图像和视频任务中表现出色,并且在无需参数适应的情况下超越了以往的视频表示方法。尤其是在捕捉细微运动细节方面,V-JEPA 展现出了其在视频理解领域的巨大潜力。
V-JEPA 模型的技术原理
V-JEPA 模型的核心在于其特征预测能力,它通过预测视频中不同时间步的特征来实现对视频内容的理解。这种方法避免了对大量标注数据的依赖,从而实现了真正的无监督学习。
- 对象中心表示:模型首先从视频帧中提取对象中心的表示。这些表示捕捉了对象的运动和外观特征,为后续的特征预测提供了基础。
- 对比学习增强:为了提高对象的可分性,模型采用了对比学习的方法。通过对比学习,模型能够更好地区分不同的对象,从而提高特征预测的准确性。
- Transformer架构:基于Transformer的架构被用于处理对象之间的关系。Transformer模型能够捕捉对象之间的时间交互,从而更好地理解视频中的动态变化。
- 大规模数据集训练:为了优化模型的性能,V-JEPA 模型通过大规模数据集进行训练。这种训练方式能够提高模型的泛化能力,使其在不同的视频场景中都能表现出色。
V-JEPA 模型的应用前景
V-JEPA 模型的出现,为视频理解领域带来了新的可能性。由于其出色的性能和高效的训练能力,V-JEPA 模型在多个领域都具有广泛的应用前景。
- 视频监控:V-JEPA 模型可以用于视频监控领域,通过分析视频中的运动模式和对象行为,实现智能监控和异常检测。
- 自动驾驶:在自动驾驶领域,V-JEPA 模型可以帮助车辆更好地理解周围环境,从而提高驾驶的安全性和可靠性。
- 智能视频分析:V-JEPA 模型可以用于智能视频分析领域,例如视频内容识别、视频摘要生成等,从而提高视频处理的效率和质量。
- 教育领域:通过分析学生的学习视频,可以了解学生的学习行为和习惯,从而为学生提供个性化的学习建议。
- 医疗健康:在医疗健康领域,V-JEPA 模型可以用于分析医学影像,帮助医生更准确地诊断疾病。
V-JEPA 模型与其他视频理解模型的比较
与其他视频理解模型相比,V-JEPA 模型具有以下优势:
- 无监督学习:V-JEPA 模型是一种无监督学习模型,不需要大量的标注数据进行训练,降低了训练成本。
- 高效的训练能力:V-JEPA 模型具有高效的训练能力,可以在较短的时间内完成训练。
- 强大的表示能力:V-JEPA 模型具有强大的表示能力,可以捕捉视频中的细微运动细节。
- 无需参数适应:V-JEPA 模型在不同的图像和视频任务中表现出色,无需进行参数适应。
结论与展望
Meta AI 团队的 V-JEPA 模型在视频理解领域取得了显著的进展。通过特征预测的方法,V-JEPA 模型实现了高效的无监督视频学习,并在多个任务中表现出色。随着人工智能技术的不断发展,我们有理由相信,V-JEPA 模型将在未来发挥更大的作用,为人类带来更多的便利和创新。








