
就在大家以为DeepSeek“开源周”已经结束的时候,DeepSeek官方突然又扔出了一颗“重磅炸弹”——公布了DeepSeek-V3/R1的推理系统!
这波操作,简直比“One More Thing”还要“One More Thing”!
更让人惊喜的是,DeepSeek不仅介绍了推理系统的设计原则和技术细节,还大方地晒出了在线服务的统计数据,甚至连成本利润率都算得明明白白!
这波操作,不仅让技术圈沸腾,更让大家对AI推理的未来充满了期待。
DeepSeek的“黑科技”:如何实现高性能推理?
DeepSeek-V3/R1推理系统的核心目标,就是实现更高的吞吐量和更低的延迟。为了达到这个目标,DeepSeek采用了跨节点专家并行(EP) 策略,并对计算-通信重叠和负载平衡进行了深度优化。
什么是跨节点专家并行(EP)?
简单来说,EP就是把“专家”(模型中的一部分)分散到不同的GPU上,每个GPU只负责处理一小部分专家。这样做的好处显而易见:
- 提高吞吐量:通过扩展batch大小,提高GPU矩阵计算效率。
- 降低延迟:每个GPU处理的专家更少,减少内存访问需求。
但EP也带来了新的挑战:
- 跨节点通信:需要优化计算工作流,让通信与计算重叠。
- 负载平衡:需要在不同的GPU实例之间进行负载平衡。
DeepSeek如何解决这些挑战?
DeepSeek的工程师们,就像一群“精算师”,对推理过程的每一个环节都进行了精密的优化:
- 利用EP扩展batch大小:
- 预填充阶段:采用EP32策略,每个GPU处理9个路由专家和1个共享专家。
- 解码阶段:采用EP144策略,每个GPU管理2个路由专家和1个共享专家。
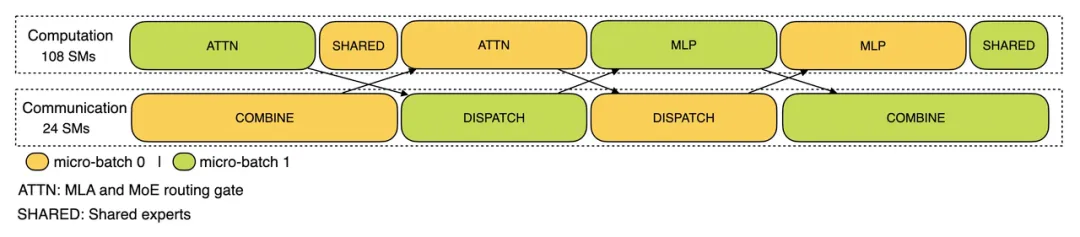
- 隐藏计算背后的通信延迟:
- 预填充阶段:采用"dual-batch"重叠策略,将一个batch请求拆分为两个microbatch,让通信成本隐藏在计算过程中。
- 解码阶段:将注意力层细分为两个step,并使用一个5阶段的pipeline来实现无缝的通信-计算重叠。
- 执行负载平衡:
- 预填充负载平衡器:平衡核心注意力计算和调度发送负载。
- 解码负载平衡器:平衡KV缓存使用率和调度发送负载。
- 专家并行负载平衡器:平衡每个GPU上的专家计算。
这些技术细节,听起来可能有点“烧脑”,但它们却是DeepSeek实现高性能推理的“秘密武器”。
DeepSeek的“透明度”:在线服务数据大公开
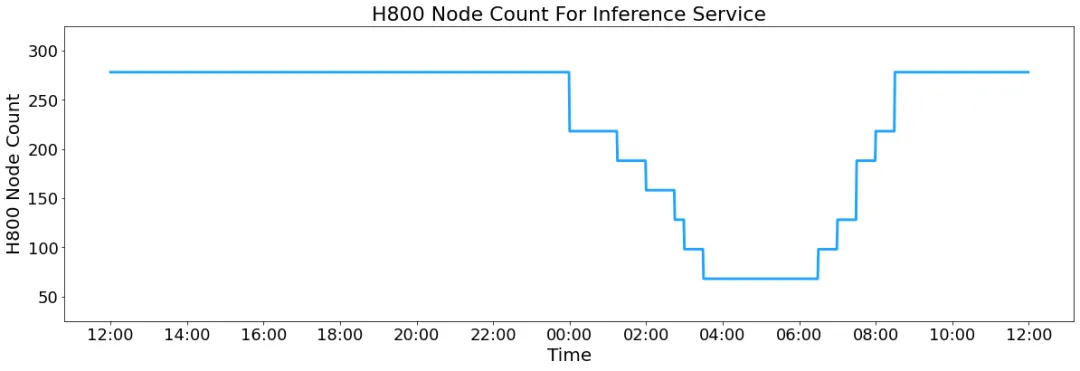
除了技术细节,DeepSeek还公布了在线服务的统计数据,让我们得以一窥其推理系统的真实性能:
- 硬件平台:H800 GPU
- 精度:与训练一致(FP8格式用于矩阵乘法和分发传输,BF16格式用于核心MLA计算和组合传输)
- 吞吐量:
- 预填充阶段:每个H800节点平均约73.7k tokens/s输入(包括缓存命中)
- 解码阶段:每个H800节点平均约14.8k tokens/s输出
- KV缓存命中率:56.3%
这些数据,不仅展示了DeepSeek推理系统的强大性能,更体现了DeepSeek对技术的自信和开放态度。
DeepSeek的“商业经”:成本与收入的博弈
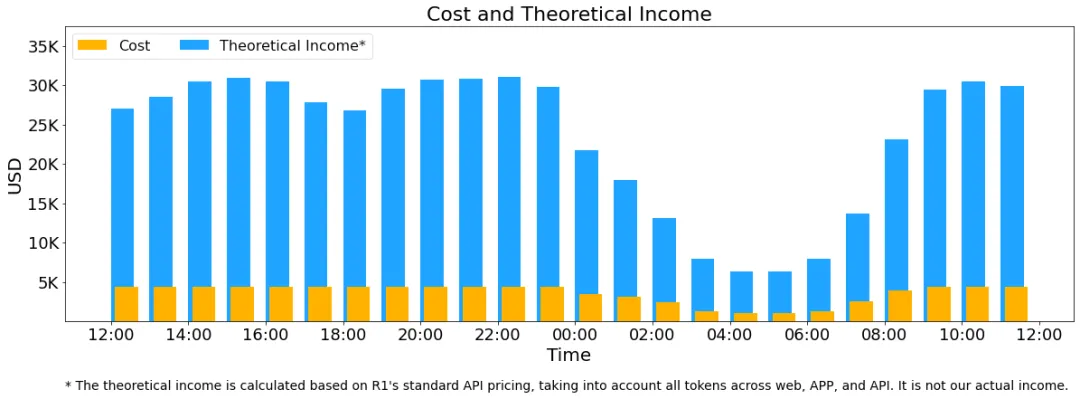
DeepSeek甚至还大胆地估算了理论收入,并解释了实际收入低于预估的原因:
- 理论收入:如果所有tokens都按照DeepSeek-R1的定价计算,每日总收入将达到562,027美元,成本利润率高达545%!
- 实际收入:由于V3定价更低、部分服务免费、夜间折扣等原因,实际收入远低于此数字。
这种“自曝家底”的做法,在AI行业可谓“一股清流”。它不仅让大家看到了AI推理的商业潜力,也让我们对DeepSeek的未来发展充满了信心。
DeepSeek的这一系列操作,不仅展示了其在AI推理领域的技术实力,更体现了其开放、透明的企业文化。我们有理由相信,DeepSeek将在未来的AI浪潮中,继续扮演重要的角色。








