
在数据处理领域,高性能和大规模是永恒的追求。DeepSeek 开源的 Smallpond,正是一款为应对这些挑战而生的轻量级数据处理框架。它巧妙地结合了 DuckDB 的强大分析能力和 3FS 的分布式存储优势,旨在为用户提供高效、便捷的大规模数据处理体验。本文将深入探讨 Smallpond 的技术原理、功能特性、性能表现以及应用场景,帮助读者全面了解这款新兴的数据处理利器。
Smallpond:轻量级数据处理的新选择
Smallpond 并非一个全新的概念,而是在现有技术基础上的一次创新性整合。它充分利用了 DuckDB 作为高性能分析引擎的优势。DuckDB 以其出色的查询性能和对 SQL 的良好支持而闻名,能够高效地处理各种数据分析任务。同时,Smallpond 借助 3FS 的分布式存储能力,实现了对 PB 级别数据集的处理能力。这种轻量级的设计使得 Smallpond 易于部署和使用,无需复杂的配置和长时间运行的服务,即可完成数据处理任务。
Smallpond 的核心功能与特性
Smallpond 的设计目标是提供一个简单、高效且可扩展的数据处理框架。为了实现这一目标,Smallpond 具备以下几个核心功能和特性:
- 轻量级和易用性:Smallpond 提供了简洁的 API 和易于理解的工作流程,降低了用户的使用门槛。用户可以通过简单的几行代码,即可完成复杂的数据处理任务。
- 高性能数据处理:Smallpond 采用 DuckDB 作为其核心的 SQL 引擎,能够充分利用 DuckDB 的优化技术,实现对大规模数据集的高效处理。无论是复杂的查询还是数据转换,Smallpond 都能以优异的性能完成。

- PB 级数据扩展性:Smallpond 基于 3FS 构建,3FS 作为一个分布式文件系统,能够提供 PB 级别的存储容量。这意味着 Smallpond 可以轻松处理大规模数据集,满足各种数据密集型应用的需求。
- 便捷操作:Smallpond 的设计理念是“即用即走”,用户无需部署和维护长时间运行的服务。只需在需要时启动 Smallpond,完成数据处理任务后即可关闭,大大简化了运维负担。
- 快速上手:Smallpond 提供了详细的文档和示例数据,帮助用户快速上手。用户可以使用 DuckDB SQL 对数据进行处理,无需学习新的编程语言或框架。
Smallpond 的技术原理剖析
Smallpond 的强大功能背后,是其精心设计的技术架构。理解 Smallpond 的技术原理,有助于更好地利用它来解决实际问题。
- 数据加载:Smallpond 基于 3FS 加载数据,支持多种常见的数据格式,如 Parquet、CSV 等。用户可以通过简单的配置,即可将数据加载到 Smallpond 中。
- 数据处理:Smallpond 使用 DuckDB 的 SQL 引擎对数据进行处理。DuckDB 支持标准的 SQL 语法,并提供了丰富的内置函数,用户可以使用 SQL 语句进行复杂的查询和分析操作。
- 数据存储:处理后的数据可以保存回 3FS,Smallpond 支持分区存储,将数据按照一定的规则分割成多个部分,并存储在不同的节点上。这有助于提高数据的读写效率,并支持并行处理。
- 并行处理:Smallpond 支持数据分区和并行处理,能够充分利用集群的计算资源,提高数据处理效率。通过将数据分割成多个部分,并在不同的节点上并行处理,Smallpond 能够显著缩短数据处理时间。
Smallpond 的性能表现
性能是衡量数据处理框架的重要指标。为了评估 Smallpond 的性能,DeepSeek 团队在运行 3FS 的集群上进行了 GraySort 基准测试。该集群包含 50 个计算节点和 25 个存储节点。测试结果显示,Smallpond 在 30 分钟 14 秒内完成了对 110.5 TiB 数据的排序,平均吞吐量达到 3.66 TiB/min。这一结果充分证明了 Smallpond 在大规模数据处理方面的卓越性能。
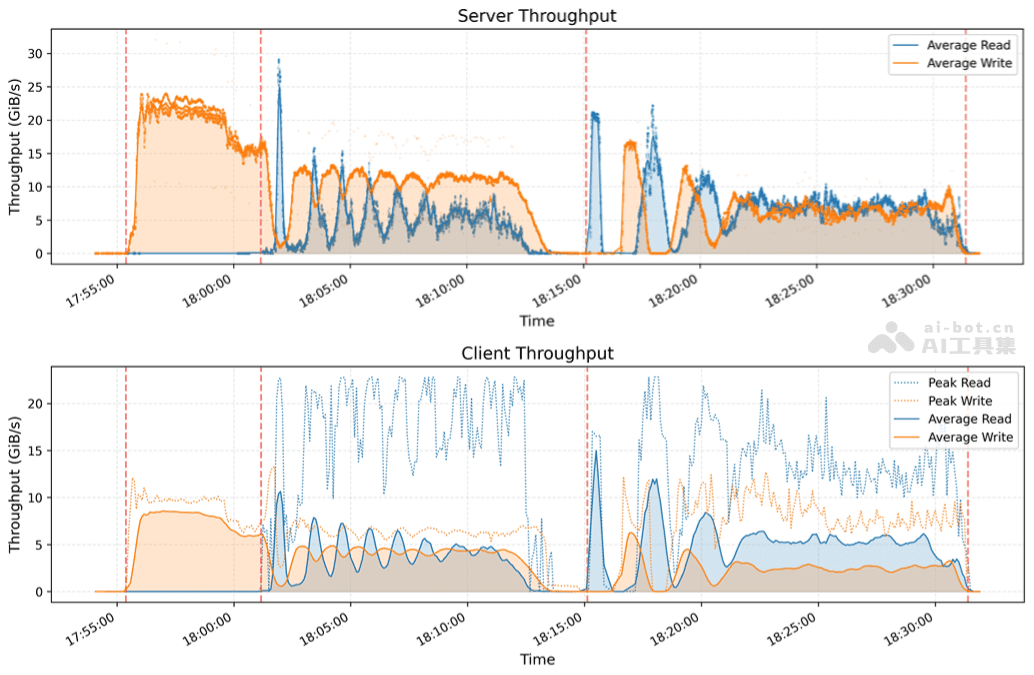
Smallpond 的应用场景展望
Smallpond 的灵活性和高性能使其能够应用于各种数据处理场景。以下是一些典型的应用场景:
- 大规模数据预处理:在机器学习和深度学习领域,数据预处理是一个至关重要的步骤。Smallpond 能够高效地处理和转换大规模数据集,支持数据清洗、格式转换和特征提取等操作,为模型训练提供高质量的输入数据。
- 数据分析与实时查询:Smallpond 能够快速执行复杂的数据分析和实时查询任务,适用于需要快速生成分析结果的场景,如数据仪表盘和实时监控系统。无论是分析历史数据还是实时数据,Smallpond 都能提供快速、准确的结果。
- 分布式机器学习训练:Smallpond 可以为分布式机器学习训练任务提供强大的数据支持,提升训练效率。通过将训练数据存储在 3FS 上,并使用 Smallpond 进行数据预处理和加载,可以显著提高训练速度。
- 嵌入式数据分析应用:Smallpond 的轻量级设计使其能够轻松嵌入到各种应用中,为嵌入式设备或资源受限的环境提供高效的数据分析能力。例如,可以将 Smallpond 嵌入到智能家居设备中,对传感器数据进行实时分析。
- 数据仓库与湖存储集成:Smallpond 可以与现有的数据仓库和数据湖存储系统(如 3FS)无缝集成,支持高效的数据读写和管理。这使得 Smallpond 能够成为构建现代化数据处理和分析架构的关键组件。
如何开始使用 Smallpond
要开始使用 Smallpond,可以按照以下步骤进行:
- 安装 Smallpond:可以从 Smallpond 的 GitHub 仓库(https://github.com/deepseek-ai/smallpond)下载 Smallpond 的源代码,并按照文档中的说明进行安装。
- 配置 3FS:如果需要处理存储在 3FS 上的数据,需要配置 Smallpond 以连接到 3FS 集群。具体的配置方法可以参考 3FS 的文档。
- 编写 SQL 查询:使用 DuckDB SQL 编写数据处理查询。可以使用 Smallpond 提供的示例数据进行练习,或者使用自己的数据进行实验。
- 运行 Smallpond:运行 Smallpond,执行 SQL 查询,并查看结果。可以根据需要调整查询参数和配置,以优化性能。
总结与展望
Smallpond 是一款功能强大、易于使用且性能卓越的轻量级数据处理框架。它通过结合 DuckDB 和 3FS 的优势,为用户提供了一种高效处理大规模数据的新选择。随着数据量的不断增长和数据处理需求的日益复杂,Smallpond 有望在未来的数据处理领域发挥越来越重要的作用。无论是数据科学家、数据工程师还是应用开发者,都可以借助 Smallpond 来简化数据处理流程,提高工作效率,并从数据中挖掘出更多的价值。
希望本文能够帮助读者全面了解 Smallpond,并为读者在实际应用中选择合适的数据处理工具提供参考。随着 Smallpond 的不断发展和完善,相信它将在数据处理领域带来更多的惊喜。








