
在人工智能领域,多模态大模型正逐渐成为研究和应用的热点。最近,阿里通义等机构推出了一款名为HumanOmni的多模态大模型,该模型专注于人类中心场景,旨在通过融合视觉和听觉信息,更全面地理解人类的行为、情感和交互。
HumanOmni模型基于超过240万个视频片段和1400万条指令进行预训练,它能够处理视频、音频或两者的结合输入,从而实现对人类行为的深入理解。该模型采用了一种动态权重调整机制,可以根据不同的场景灵活地融合视觉和听觉信息,使其在情感识别、面部描述和语音识别等方面表现出色。HumanOmni的应用场景非常广泛,包括电影分析、特写视频解读和实拍视频理解等。
HumanOmni的核心功能
HumanOmni模型具有以下几个核心功能:
多模态融合:HumanOmni能够同时处理视觉(视频)、听觉(音频)和文本信息,通过指令驱动的动态权重调整机制,将不同模态的特征进行融合,从而实现对复杂场景的全面理解。这种多模态融合能力使得模型能够从不同的角度理解人类行为,从而提高其理解的准确性和全面性。
人类中心场景理解:模型通过三个专门的分支分别处理面部相关、身体相关和交互相关场景,根据用户指令自适应地调整各分支的权重,以适应不同的任务需求。这种设计使得模型能够更好地理解人类在不同场景下的行为和情感。
情绪识别与面部表情描述:在动态面部情感识别和面部表情描述任务中,HumanOmni表现出色,超越了现有的视频-语言多模态模型。这表明该模型在理解人类情感方面具有很强的能力。
动作理解:通过身体相关分支,模型能够有效理解人体动作,适用于动作识别和分析任务。这使得模型能够应用于体育分析、康复治疗等领域。
语音识别与理解:在语音识别任务中,HumanOmni通过音频处理模块(如Whisper-large-v3)实现对语音的高效理解,支持特定说话人的语音识别。这使得模型能够应用于智能客服、语音助手等领域。
跨模态交互:模型结合视觉和听觉信息,能够更全面地理解场景,适用于电影片段分析、特写视频解读和实拍视频理解等任务。这种跨模态交互能力使得模型能够更好地理解人类在复杂场景下的行为。
灵活的微调支持:开发者可以基于HumanOmni的预训练参数进行微调,以适应特定的数据集或任务需求。这使得模型能够应用于各种不同的领域。
HumanOmni的技术原理
HumanOmni模型的技术原理主要包括以下几个方面:
- 多模态融合架构:HumanOmni通过视觉、听觉和文本三种模态的融合,实现对复杂场景的全面理解。在视觉部分,模型设计了三个分支:面部相关分支、身体相关分支和交互相关分支,分别用于捕捉面部表情、身体动作和环境交互的特征。通过指令驱动的融合模块动态调整权重,根据用户指令自适应地选择最适合任务的视觉特征。这种多模态融合架构使得模型能够从不同的角度理解人类行为,从而提高其理解的准确性和全面性。
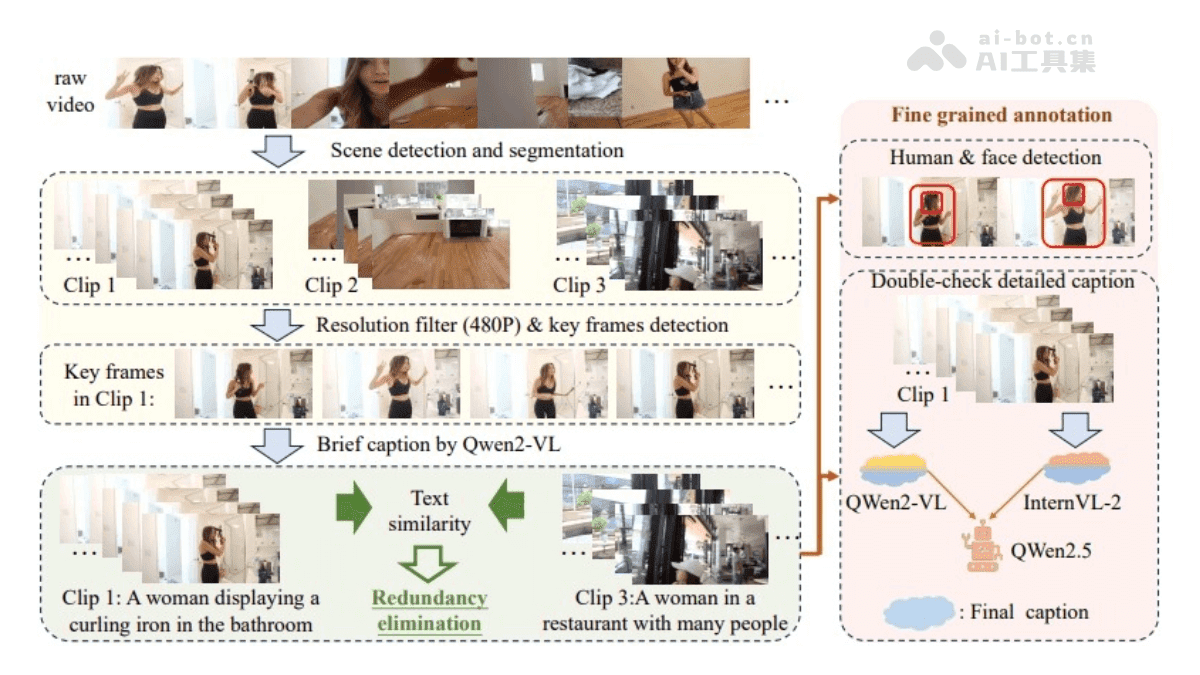
动态权重调整机制:HumanOmni引入了一种指令驱动的特征融合机制。通过BERT对用户指令进行编码,生成权重,动态调整不同分支的特征权重。在情感识别任务中,模型会更侧重于面部相关分支的特征;在交互场景中,会优先考虑交互相关分支。这种动态权重调整机制使得模型能够根据不同的任务自适应地调整其关注点,从而提高其性能。
听觉与视觉的协同处理:在听觉方面,HumanOmni使用Whisper-large-v3的音频预处理器和编码器处理音频数据,通过MLP2xGeLU将其映射到文本域。视觉和听觉特征在统一的表示空间中结合,进一步输入到大语言模型的解码器中进行处理。这种听觉与视觉的协同处理使得模型能够更好地理解人类的语音和行为。
多阶段训练策略:HumanOmni的训练分为三个阶段:
- 第一阶段构建视觉能力,更新视觉映射器和指令融合模块的参数。
- 第二阶段发展听觉能力,仅更新音频映射器的参数。
- 第三阶段进行跨模态交互集成,提升模型处理多模态信息的能力。这种多阶段训练策略使得模型能够更好地学习视觉和听觉信息,并将其融合在一起。
数据驱动的优化:HumanOmni基于超过240万个人类中心视频片段和1400万条指令数据进行预训练。数据涵盖了情感识别、面部描述和特定说话人的语音识别等多个任务,模型在多种场景下表现出色。这种数据驱动的优化使得模型能够更好地理解人类的行为和情感。
HumanOmni的应用场景展望
HumanOmni的应用场景非常广泛,以下是一些可能的应用场景:
影视与娱乐:HumanOmni可用于影视制作,例如虚拟角色动画生成、虚拟主播和音乐视频创作。通过分析演员的面部表情和肢体动作,模型可以生成逼真的虚拟角色动画,从而降低影视制作的成本。
教育与培训:在教育领域,HumanOmni可以创建虚拟教师或模拟训练视频,辅助语言学习和职业技能培训。通过分析学生的语音和行为,模型可以提供个性化的学习建议,从而提高学习效果。
广告与营销:HumanOmni能够生成个性化广告和品牌推广视频,通过分析人物情绪和动作,提供更具吸引力的内容,提升用户参与度。通过分析用户的行为和偏好,模型可以生成更符合用户需求的广告,从而提高广告的点击率。
社交媒体与内容创作:HumanOmni可以帮助创作者快速生成高质量的短视频,支持互动视频创作,增加内容的趣味性和吸引力。通过分析用户的反馈,模型可以提供内容创作建议,从而提高内容的质量。
项目地址
对于希望深入研究或使用HumanOmni的开发者和研究人员,以下是该项目的相关资源链接:
- Github仓库:https://github.com/HumanMLLM/HumanOmni
- HuggingFace模型库:https://huggingface.co/StarJiaxing/HumanOmni-7B
- arXiv技术论文:https://arxiv.org/pdf/2501.15111
通过这些资源,您可以了解HumanOmni的更多细节,并开始将其应用到您的项目中。
总而言之,HumanOmni作为一款专注于人类中心场景的多模态大模型,在情感识别、面部描述和语音识别等方面表现出色,具有广泛的应用前景。随着人工智能技术的不断发展,相信HumanOmni将在更多领域发挥其独特的价值。








