
在数字时代,栩栩如生的虚拟形象变得越来越重要。无论是虚拟现实(VR)、增强现实(AR)、游戏,还是影视制作,高品质的3D头像都是提升用户体验的关键。近日,慕尼黑工业大学和Meta Reality Labs联合推出了一项引人注目的创新成果——Avat3r,它是一种能够高效生成高保真、可动画3D头像的大型高斯重建模型。本文将深入探讨Avat3r的技术原理、功能特性、应用场景,以及它对未来虚拟形象生成领域的潜在影响。
Avat3r:3D头像生成的新标杆
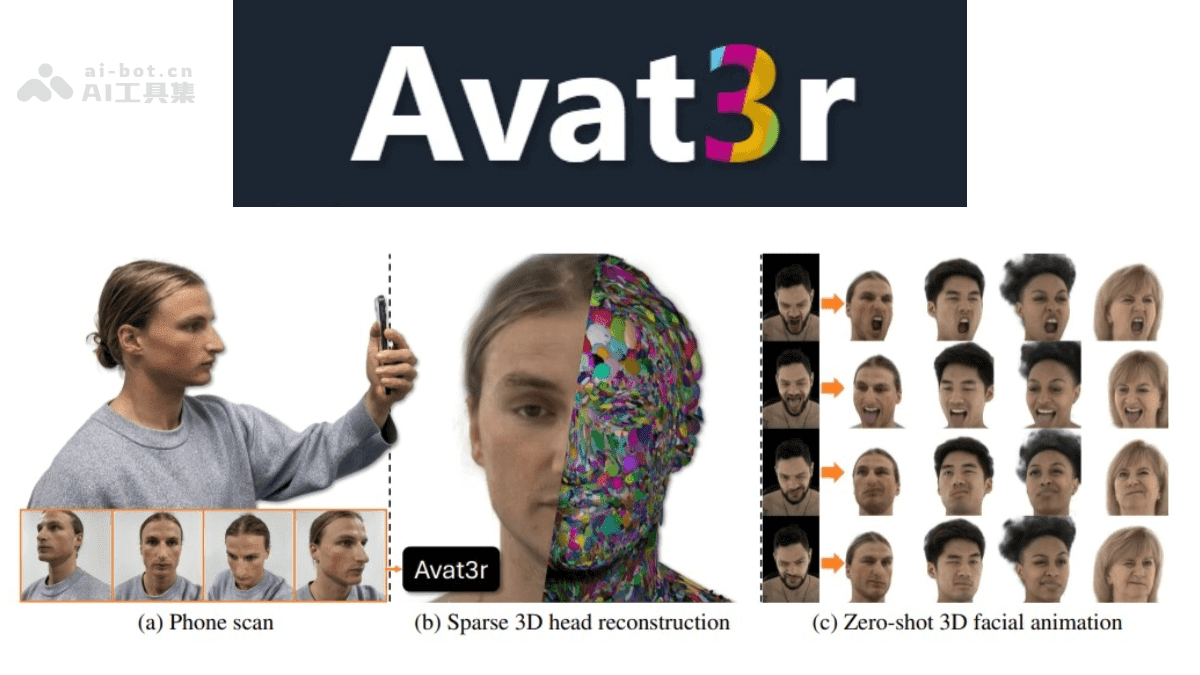
Avat3r的出现,旨在解决传统3D头像生成方法中存在的计算资源需求高、动画效果不自然等问题。传统的3D建模技术往往需要耗费大量时间和算力,并且对于捕捉细微的面部表情变化也存在局限性。Avat3r通过结合高斯重建技术和深度学习,仅需几张输入图像,就能够快速生成高质量、可动画的3D头部头像,极大地降低了计算成本,并提升了生成效率。这一突破性的进展,无疑为虚拟形象的应用开辟了更广阔的前景。
Avat3r的核心功能
Avat3r之所以能够在3D头像生成领域脱颖而出,离不开其独特的功能特性。以下是Avat3r的几个主要功能:
高效生成:
Avat3r最大的亮点在于其高效的生成能力。与传统的3D建模方法相比,Avat3r只需少量输入图像,即可快速生成高质量的3D头部头像。这大大减少了建模所需的时间和计算资源,使得3D头像的生成变得更加便捷。
动画化能力:
除了静态的3D模型,Avat3r还具备强大的动画化能力。通过简单的交叉注意力机制,Avat3r能够为生成的3D头部头像赋予生动的动画效果,支持实时表情控制。这意味着用户可以根据自己的需要,调整头像的表情,使其更加富有表现力。
鲁棒性:
Avat3r在训练过程中,使用了大量不同表情的图像,这使得模型具有很强的鲁棒性。即使输入图像质量不高,例如手机拍摄的模糊照片或单目视频帧,Avat3r依然能够生成高质量的3D头像。这大大拓宽了Avat3r的应用范围,使其能够适应各种不同的输入条件。
多源输入支持:
Avat3r支持多种来源的输入,包括智能手机拍摄的照片、单张图像,甚至是古董半身像。这意味着用户可以使用各种不同的图像来源,生成个性化的3D头像,极大地提升了使用的灵活性。
Avat3r的技术原理
Avat3r的强大功能,源于其背后精湛的技术原理。以下将深入剖析Avat3r的技术构成:
高斯重建技术:
Avat3r采用了3D高斯喷洒技术(3D Gaussian-splatting)作为基础表示。这种技术将3D空间中的点用高斯分布表示,每个高斯分布不仅描述点的空间位置,还编码颜色、法线等属性。通过这种方式,Avat3r能够高效地重建和渲染复杂的3D头部模型,实现高质量的视觉效果。
与传统的基于网格的3D建模方法相比,高斯喷洒技术具有更高的灵活性和效率。它可以更好地处理复杂的几何结构和纹理细节,并且能够实现更快的渲染速度。这使得Avat3r在生成高质量3D头像的同时,也能够保证较高的效率。
多视图数据学习:
Avat3r从多角度视频数据集中学习三维人头的强大先验。这意味着模型在训练过程中,接触了大量不同角度、不同光照条件下的头部图像。通过这种方式,Avat3r能够更好地理解三维人头的结构和特征,从而在仅有少量输入图像的情况下,也能生成高质量的3D头部头像。
此外,多视图数据学习还提高了Avat3r的鲁棒性。即使输入图像存在遮挡、模糊等问题,模型依然能够根据已学习到的先验知识,推断出完整的3D头部结构。
动画化技术:
Avat3r的动画化能力,得益于其创新的交叉注意力机制。模型在训练时,会输入不同表情的图像,从而学习不同表情之间的对应关系。在生成3D头像后,Avat3r可以通过交叉注意力机制,将输入的表情信息传递到3D模型上,实现实时的表情控制。
这种交叉注意力机制,不仅简单高效,而且具有很强的泛化能力。即使是模型未曾见过的表情,Avat3r也能够根据已学习到的知识,进行合理的推断和生成。
结合先验模型:
为了进一步优化重建效果,Avat3r还结合了DUSt3R的位置图和Sapiens的广义特征图。这些先验模型为3D头部的几何结构和纹理提供了额外的约束,使得生成的头像更加真实和精细。
DUSt3R是一种用于估计3D人体姿态和形状的模型,它可以提供头部的位置和方向信息。Sapiens则是一种用于生成逼真的人脸纹理的模型,它可以提供头部的颜色和光照信息。通过结合这些先验模型,Avat3r能够生成更加逼真和自然的3D头像。
高效性和泛化能力:
Avat3r在少输入和单输入场景中表现出色,能在几分钟内从几张输入图像生成高质量的3D头像。这意味着用户无需耗费大量时间和精力,即可获得个性化的3D形象。
此外,Avat3r还具备良好的泛化能力,能够处理来自不同来源的输入,如智能手机照片或单张图片。这使得Avat3r能够适应各种不同的应用场景,满足不同用户的需求。
Avat3r的应用场景
Avat3r的强大功能和广泛的适用性,使其在多个领域都具有巨大的应用潜力:
虚拟现实(VR)和增强现实(AR):
在VR和AR应用中,用户需要一个虚拟的身份来与其他用户进行互动。Avat3r可以生成高质量且可动画化的3D头部头像,为用户提供个性化的虚拟形象,增强沉浸感和互动体验。
影视制作和视觉特效:
在影视制作中,角色建模和动画生成是一项耗时耗力的工作。Avat3r仅需几张输入图像即可生成高质量的3D头像,大大缩短了制作周期,降低了制作成本。
游戏开发:
在游戏开发中,角色的3D头像对于提升游戏体验至关重要。Avat3r可以快速生成角色的3D头像,并支持实时动画化,为玩家提供更具沉浸感的游戏体验。
数字人和虚拟助手:
数字人和虚拟助手是未来人机交互的重要形式。Avat3r可用于生成数字人的3D头像,头像可以结合语音合成和自然语言处理技术,为用户提供更加自然和个性化的交互体验。
项目地址
总结与展望
Avat3r作为慕尼黑工业大学和Meta Reality Labs的联合研究成果,代表了3D头像生成领域的最新进展。它通过结合高斯重建技术、多视图数据学习、交叉注意力机制和先验模型,实现了高效、高质量、可动画的3D头像生成。Avat3r的出现,不仅降低了3D头像生成的门槛,也为虚拟现实、增强现实、影视制作、游戏开发等领域带来了新的机遇。随着技术的不断发展,我们有理由相信,未来的虚拟形象将会更加逼真、个性化和智能化,为人们的生活带来更多的乐趣和便利。








