
探索WarriorCoder:代码生成的全新范式
在软件开发领域,代码生成技术一直备受关注。近日,由华南理工大学与微软联合推出的WarriorCoder,为这一领域带来了新的突破。这款大型语言模型(LLM)专注于代码生成,其独特之处在于不依赖现有专有模型或数据集,而是通过模拟专家模型之间的对抗,生成高质量的训练数据,从而显著提升模型性能。本文将深入探讨WarriorCoder的技术原理、主要功能、应用场景,并分析其在代码生成领域的潜在影响。
WarriorCoder:技术原理深度剖析
WarriorCoder的核心技术在于其创新的专家对抗框架。该框架构建了一个模拟竞技场,让多个先进的代码专家模型(主要为开源LLM)相互对抗。每一轮对抗中,两个模型分别扮演“攻击者”和“防守者”的角色,根据特定的指令生成代码。随后,由其他的模型作为“裁判”,对生成的代码结果进行评估。目标模型则从对抗中的胜者学习,从而逐步整合所有专家模型的优势。这种对抗学习的模式,避免了对人工标注或私有LLM的依赖,降低了数据获取的成本,同时保证了数据的多样性和高质量。
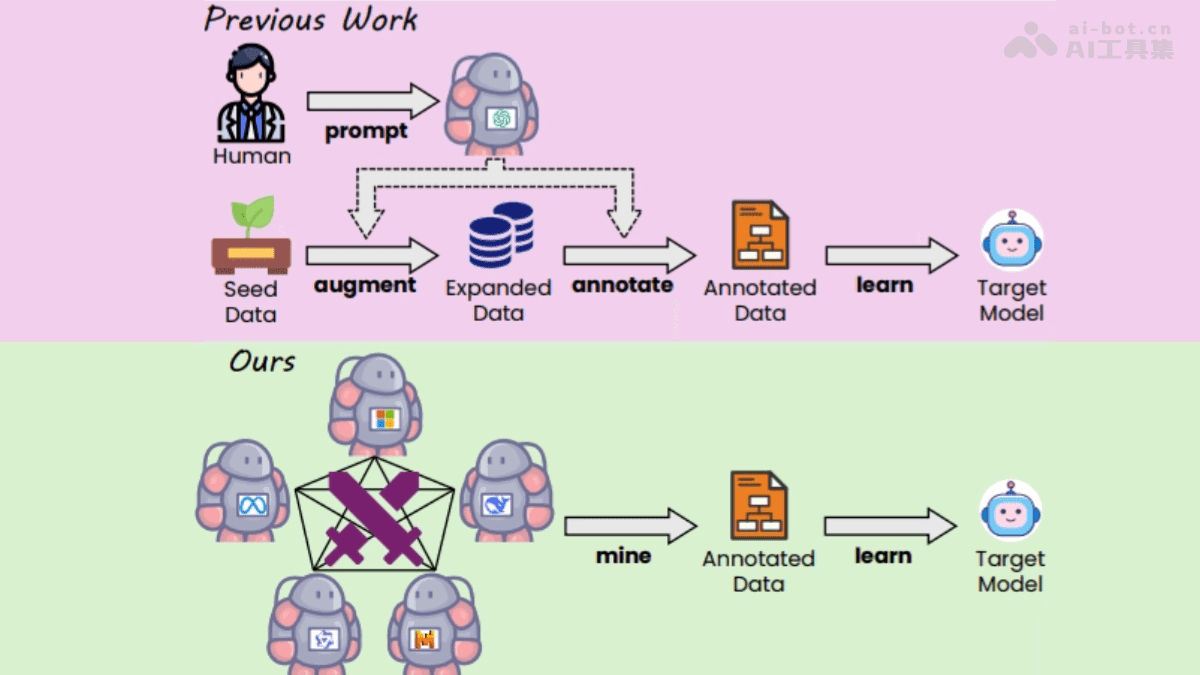
为了进一步提升训练数据的质量,WarriorCoder采用了指令挖掘技术。该技术基于补全的方法,挖掘专家模型已掌握的能力,避免了对私有数据的依赖。通过模型的生成能力,从分布中采样指令,有效避免了模式过拟合和数据偏移的问题。此外,WarriorCoder还引入了难度评估与去重机制,对挖掘出的指令进行去重处理,并由裁判模型评估其难度,最终保留高质量的指令(难度等级为“优秀”或“良好”)。
Elo评分系统在WarriorCoder中扮演着重要的角色。该系统结合局部对抗结果和全局表现,对模型的综合能力进行评估。通过动态更新Elo评分,平衡局部偶然性和全局一致性,避免了弱模型因偶然因素获胜的情况。最终,WarriorCoder使用对抗中胜者的响应作为训练数据,基于监督微调(SFT)训练目标模型。这种方法无需依赖人工标注或私有LLM,可以用低成本生成多样化、高质量的训练数据。
WarriorCoder:核心功能解析
WarriorCoder的功能十分全面,涵盖了代码生成的各个方面:
- 代码生成:根据给定的指令或需求,自动生成高质量的代码片段。这极大地提高了开发效率,让开发者可以将更多精力投入到业务逻辑的实现上。
- 代码优化:对现有代码进行分析和优化,提高其性能和效率。这对于大型项目来说尤为重要,可以有效降低资源消耗,提升用户体验。
- 代码调试:帮助识别和修复代码中的错误或漏洞。通过智能分析代码,WarriorCoder可以快速定位问题所在,并提供相应的修复建议,减少调试时间。
- 代码推理:预测代码的输出或根据输出反推输入,增强对代码逻辑的理解。这对于代码维护和升级非常有帮助,可以更好地理解代码的功能和行为。
- 库和框架的使用:能够生成与特定编程库(如NumPy、Pandas等)相关的代码,提升对复杂库的调用能力。这使得开发者可以更加便捷地使用各种库和框架,构建复杂的应用程序。
- 多语言支持:支持多种编程语言,适应不同开发场景的需求。无论是Python、Java还是C++,WarriorCoder都能提供相应的代码生成和优化服务。
WarriorCoder:应用场景展望
WarriorCoder的应用前景十分广阔,可以应用于各种软件开发场景:
- 自动化代码生成:根据自然语言描述快速生成代码,提升开发效率。例如,开发者只需描述所需的功能,WarriorCoder即可自动生成相应的代码,大大缩短开发周期。
- 代码优化与重构:提供优化建议,提升代码性能和可读性。对于遗留系统,WarriorCoder可以帮助开发者进行代码重构,提高代码质量。
- 代码调试与修复:帮助定位错误并提供修复方案,减少调试时间。在复杂的项目中,调试往往是一项耗时耗力的任务,WarriorCoder可以帮助开发者快速定位问题,提高调试效率。
- 编程教育辅助:生成示例代码和练习题,助力编程学习。对于初学者来说,WarriorCoder可以提供丰富的学习资源,帮助他们更快地掌握编程技能。
- 跨语言代码转换:支持代码从一种语言转换为另一种语言,便于技术栈迁移。在技术栈迁移的过程中,代码转换往往是一项繁琐的任务,WarriorCoder可以自动完成这一过程,降低迁移成本。
WarriorCoder与现有代码生成模型的对比
与现有的代码生成模型相比,WarriorCoder具有以下优势:
- 不依赖私有数据:WarriorCoder不依赖于现有的专有模型或数据集,而是通过模拟专家模型之间的对抗,生成高质量的训练数据。这降低了数据获取的成本,同时也避免了潜在的版权问题。
- 强大的泛化能力:通过整合多个开源代码专家模型的优势,WarriorCoder具有强大的泛化能力,可以适应不同的编程语言和开发场景。
- 持续学习和优化:WarriorCoder的专家对抗框架使其能够不断学习和优化,从而不断提升代码生成的质量和效率。
WarriorCoder的局限性与未来发展方向
尽管WarriorCoder具有诸多优势,但也存在一些局限性:
- 对于复杂业务逻辑的处理能力有待提升:目前,WarriorCoder主要擅长生成通用的代码片段,对于复杂的业务逻辑,可能需要人工干预。
- 对特定领域知识的理解需要加强:在某些特定领域,例如金融、医疗等,WarriorCoder可能需要更多的领域知识才能生成高质量的代码。
未来,WarriorCoder可以从以下几个方面进行改进:
- 引入更多的领域知识:通过引入更多的领域知识,提高WarriorCoder在特定领域的代码生成能力。
- 加强对复杂业务逻辑的处理能力:通过改进模型结构和训练方法,提高WarriorCoder对复杂业务逻辑的处理能力。
- 支持更多的编程语言和开发框架:通过扩展支持的编程语言和开发框架,提高WarriorCoder的适用范围。
总结
WarriorCoder作为一款创新的代码生成大语言模型,通过模拟专家模型之间的对抗,生成高质量的训练数据,从而显著提升模型性能。它具有代码生成、代码优化、代码调试、代码推理、库和框架的使用、多语言支持等多种功能,可以应用于自动化代码生成、代码优化与重构、代码调试与修复、编程教育辅助、跨语言代码转换等多种场景。尽管WarriorCoder还存在一些局限性,但其未来的发展前景十分广阔,有望成为软件开发领域的重要工具。
通过本文的分析,我们可以看到,WarriorCoder不仅是一款强大的代码生成工具,更代表了一种新的代码生成范式。它通过对抗学习和专家模型整合,实现了高质量、多样化的代码生成,为软件开发带来了新的可能性。随着技术的不断发展,我们有理由相信,WarriorCoder将在未来的软件开发领域发挥越来越重要的作用。
更多关于WarriorCoder的信息,请参考其官方技术论文:https://arxiv.org/pdf/2412.17395








