
腾讯混元图生视频模型:让静态图像跃然生动
在人工智能领域,图像生成视频技术(Image-to-Video, I2V)一直是研究的热点。近日,腾讯混元推出了其开源的图生视频模型,为这一领域带来了新的突破。该模型允许用户通过上传一张图片并进行简短描述,即可生成一段5秒钟的短视频,赋予静态图像以动态的生命力。这一技术的开源,无疑将加速视频创作领域的创新。
混元图生视频的核心功能
混元图生视频模型具备多项引人注目的功能,使其在众多I2V模型中脱颖而出:
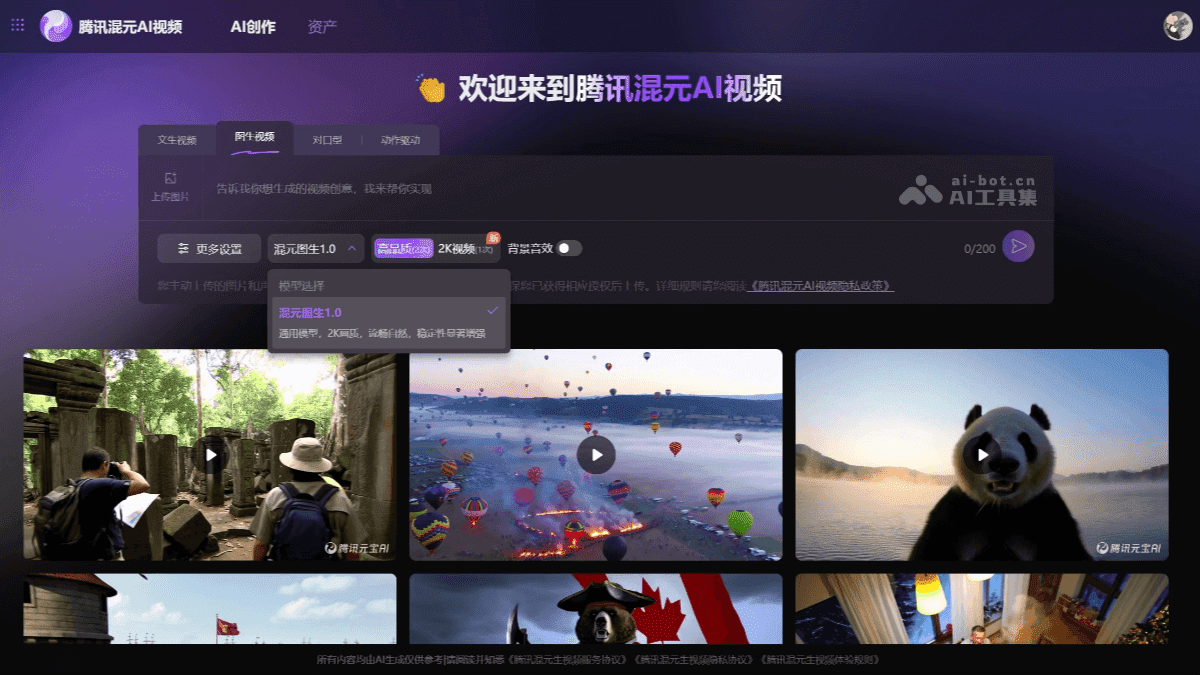
- 图生视频生成:用户上传一张图片,并辅以简短的文字描述,模型便能将静态图片转化为一段生动的短视频。更令人惊喜的是,该模型还支持自动生成与视频内容相匹配的背景音效,为视频增添更多趣味性和表现力。

音频驱动功能:用户上传人物图片,并输入相应的文本或音频,模型便能精准地匹配嘴型,使图片中的人物“说话”或“唱歌”,并呈现出符合语气的面部表情。这一功能为虚拟角色的创作和互动提供了强大的支持。
动作驱动功能:用户上传图片后,选择预设的动作模板,模型便能使图片中的人物完成跳舞、挥手、做体操等动作。这一功能在短视频创作、游戏角色动画和影视制作等领域具有广泛的应用前景。
高质量视频输出:该模型支持高达2K的高清画质输出,确保生成的视频在细节和清晰度方面都表现出色。同时,该模型适用于写实、动漫和CGI等多种角色和场景,具有广泛的适应性。
技术原理深度剖析
混元图生视频模型的技术实现融合了多种先进的人工智能技术,使其在视频生成质量和效率方面都达到了新的高度:
图像到视频的生成框架:HunyuanVideo-I2V采用了图像潜在拼接技术,将参考图像的信息无缝整合到视频生成过程中。具体而言,输入图像首先经过预训练的多模态大型语言模型(MLLM)处理,生成语义图像token,然后与视频潜在token拼接,实现跨模态的全注意力计算。这种方法有效地利用了图像信息,提高了视频生成的质量和一致性。
多模态大型语言模型(MLLM):模型采用了具有Decoder-only结构的MLLM作为文本编码器,从而显著增强了对输入图像语义内容的理解能力。与传统的CLIP或T5模型相比,MLLM在图像细节描述和复杂推理方面表现更佳,能够更好地实现图像与文本描述信息的深度融合。这种设计使得模型能够更准确地理解用户的意图,生成更符合要求的视频。
3D变分自编码器(3D VAE):为了高效处理视频和图像数据,HunyuanVideo-I2V使用CausalConv3D技术训练了一个3D VAE,将像素空间中的视频和图像压缩到紧凑的潜在空间。这种设计显著减少了后续模型中的token数量,使得模型能够在原始分辨率和帧率下进行训练,从而提高了训练效率和生成质量。
双流转单流的混合模型设计:在双流阶段,视频和文本token通过多个Transformer块独立处理,避免相互干扰;在单流阶段,将视频和文本token连接起来,进行多模态信息融合。这种设计巧妙地捕捉了视觉和语义信息之间的复杂交互,从而提升了生成视频的连贯性和语义一致性。
渐进式训练策略:模型采用了渐进式训练策略,从低分辨率、短视频逐步过渡到高分辨率、长视频。这种方法有效地提高了模型的收敛速度,并确保了生成视频在不同分辨率下的高质量。通过逐步增加训练难度,模型能够更好地学习视频生成的复杂规律。
提示词重写模型:为了解决用户提示词的语言风格和长度多变性问题,HunyuanVideo-I2V引入了提示词重写模块。该模块能够将用户输入的提示词转换为模型更易理解的格式,从而提高生成效果。这种设计使得模型能够更好地适应不同用户的需求,提高用户体验。
可定制化LoRA训练:模型支持LoRA(Low-Rank Adaptation)训练,允许开发者通过少量数据训练出具有特定效果的视频生成模型,例如“头发生长”或“人物动作”等特效。这种可定制化的训练方式为开发者提供了更大的灵活性,使得他们能够根据自己的需求定制模型,实现各种创意效果。
如何使用混元图生视频模型
腾讯混元图生视频模型提供了多种使用方式,以满足不同用户的需求:
通过混元AI视频官网体验:用户可以直接访问腾讯混元AI视频官网,选择图生视频功能,上传一张图片并输入简短描述,即可生成一段5秒的短视频。这种方式简单易用,适合普通用户体验。
使用腾讯云API接口:企业和开发者可以通过腾讯云申请API接口,实现更高效的视频生成和定制化开发。这种方式适合需要大规模生成视频或进行深度定制的专业用户。
本地部署开源模型:对于需要更高定制化的用户,腾讯混元图生视频模型已在GitHub开源,支持本地部署和定制化开发。这种方式适合有一定技术基础,希望深入研究和定制模型的开发者。
硬件要求
如果选择本地部署开源模型,需要满足一定的硬件要求:
- GPU:NVIDIA显卡,支持CUDA,最低60GB显存(生成720p视频),推荐80GB显存。
- 操作系统:Linux(官方测试环境)。
- CUDA版本:推荐CUDA 11.8或12.0。
应用场景展望
混元图生视频模型具有广泛的应用前景,有望在多个领域带来创新:
创意视频生成:用户可以通过上传图片和描述,快速生成各种创意短视频,例如节日祝福视频、个人形象展示视频等。这种方式降低了视频创作的门槛,让更多人能够参与到视频创作中来。
特效制作:通过LoRA训练,可以实现各种定制化特效,例如头发生长、人物动作等。这些特效可以应用于短视频、电影、游戏等领域,为内容创作提供更多可能性。
动画与游戏开发:可以快速生成角色动画,降低制作成本。在游戏开发中,可以用于生成游戏角色的动画、场景动画等,提高开发效率。
开源地址
- Github仓库: https://github.com/Tencent/HunyuanVideo-I2V
- Huggingface模型库:https://huggingface.co/tencent/HunyuanVideo-I2V
总而言之,腾讯混元开源的图生视频模型凭借其强大的功能和灵活的应用方式,为视频创作领域带来了新的活力。随着技术的不断发展和完善,我们有理由相信,I2V技术将在未来发挥更大的作用,为人们的生活带来更多便利和乐趣。








