
Cohere发布全新多模态AI模型Aya Vision:迈向通用人工智能的新里程碑
人工智能领域的创新浪潮持续涌动,近日,著名人工智能初创公司Cohere通过其非营利研究实验室,重磅推出了一款名为Aya Vision的多模态AI模型。该模型一经发布,便以其卓越的性能和独特的设计理念,在业界引起了广泛关注。据Cohere官方宣称,Aya Vision在多项关键性能指标上均处于行业领先地位,预示着人工智能技术在跨模态理解和应用方面取得了新的突破。
Aya Vision的核心优势在于其强大的多模态处理能力。该模型能够无缝衔接图像和文本两种不同的信息模态,从而实现一系列复杂的任务,包括但不限于:根据图像内容生成详细的描述性文字(即图像说明)、准确回答与图像内容相关的各类问题、实现多语种之间的文本翻译,以及生成23种主要语言的简洁摘要。更值得一提的是,Cohere为了推动人工智能技术的普及和发展,决定通过WhatsApp平台免费向全球研究人员提供Aya Vision的使用权限,这一举措无疑将极大地降低了科研门槛,加速了相关领域的研究进程。
Cohere在其官方博客中强调,尽管近年来人工智能技术取得了长足的进步,但在不同语言之间的模型表现仍然存在显著差异,尤其是在处理涉及文本和图像的多模态任务时,这一问题尤为突出。而Aya Vision的诞生,正是为了弥合这一差距,实现更加公平和高效的跨语言信息处理。
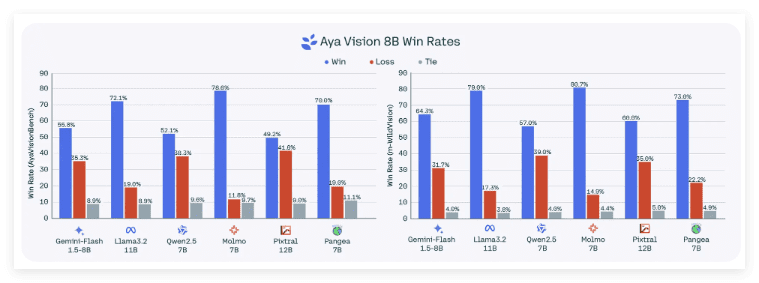
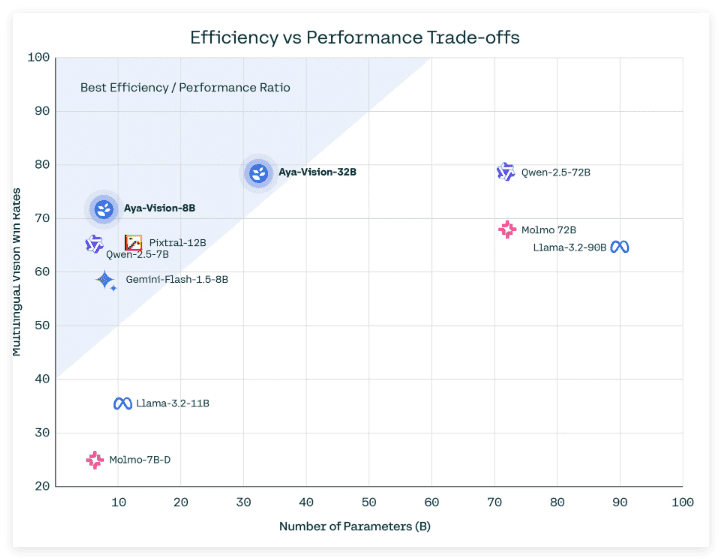
Aya Vision共发布了两个版本,分别为Aya Vision 32B和Aya Vision 8B。其中,Aya Vision 32B被誉为“新边界”,代表了当前多模态AI模型的最高水平。在多项视觉理解基准测试中,Aya Vision 32B的表现甚至超越了规模为其两倍的竞争对手模型,例如Meta的Llama-3 290B Vision。与此同时,Aya Vision 8B也在某些评估中展现出了超越部分规模为其十倍的模型的实力,充分证明了Cohere在模型设计和优化方面的卓越能力。
为了促进人工智能技术的开放和共享,Cohere选择在AI开发平台Hugging Face上以Creative Commons 4.0许可证的形式发布这两个模型。这意味着广大开发者和研究人员可以自由地使用、修改和分享Aya Vision,但同时也需要遵守Cohere的可接受使用附录,并且不得将其用于商业应用。
Cohere透露,Aya Vision的训练过程采用了“多样化的”英语数据集。为了使其能够更好地理解和处理其他语言的信息,研究人员将这些数据集翻译成多种语言,并使用合成标注进行训练。合成标注是指由AI生成的标注信息,它可以帮助模型在训练过程中更好地理解和解释数据。尽管合成数据存在潜在的缺点,但包括OpenAI在内的许多竞争对手也在越来越多地使用合成数据来训练模型,以提高模型的性能和效率。
Cohere指出,通过使用合成标注训练Aya Vision,他们能够在减少资源消耗的同时,依然取得具有竞争力的表现。“这充分展示了我们对效率的重视,即利用更少的计算资源实现更多的成果。” 这一策略不仅降低了模型的开发成本,也使其更易于部署和应用。
为了进一步支持研究社区,Cohere还发布了一套全新的基准评估工具——AyaVisionBench。该工具旨在全面考察模型在视觉与语言结合任务中的能力,例如识别两张图像之间的细微差异,以及将屏幕截图转换为可执行的代码。这些任务不仅具有高度的挑战性,而且在实际应用中也具有重要的价值。
当前,人工智能行业正面临着所谓的“评估危机”。这一危机主要源于流行基准的广泛使用,这些基准的总分与大多数AI用户真正关心的任务能力之间的相关性较差。换句话说,模型在这些基准上的高分并不一定意味着它在实际应用中也能表现出色。Cohere声称,AyaVisionBench的推出,旨在为评估模型的跨语言和多模态理解能力提供一个“广泛且具有挑战性”的框架,从而更准确地反映模型在实际应用中的性能。
AyaVisionBench的设计理念是更加注重对模型实际能力的考察,而不是仅仅关注其在特定数据集上的表现。通过提供多样化的评估任务和更严格的评估标准,AyaVisionBench有望帮助研究人员更全面地了解模型的优缺点,从而更好地指导模型的改进和优化。
多模态AI模型是人工智能领域的一个重要发展方向。与只能处理单一类型数据的传统AI模型相比,多模态AI模型能够同时处理多种类型的数据,例如图像、文本、音频和视频等。这使得它们能够更好地理解和模拟人类的认知过程,从而在各种实际应用中发挥更大的作用。
Aya Vision的发布,无疑将进一步推动多模态AI技术的发展和应用。通过其强大的多模态处理能力和开放的共享模式,Aya Vision有望成为研究人员和开发者手中的一把利器,帮助他们解决各种复杂的实际问题,并创造出更多具有创新性的应用。
多模态AI的应用前景
多模态AI技术在许多领域都具有广阔的应用前景。以下是一些典型的应用场景:
- 智能客服:多模态AI可以分析用户的语音、文本和图像,从而更准确地理解用户的问题和需求,并提供更个性化的服务。
- 自动驾驶:多模态AI可以同时处理来自摄像头、雷达和激光雷达等多种传感器的信息,从而更准确地感知周围环境,并做出更安全的驾驶决策。
- 医疗诊断:多模态AI可以分析医学影像、病历和基因数据等多种信息,从而更准确地诊断疾病,并制定更有效的治疗方案。
- 内容创作:多模态AI可以根据用户的文本描述自动生成图像、音乐和视频等内容,从而极大地提高内容创作的效率和质量。
多模态AI面临的挑战
尽管多模态AI具有巨大的潜力,但也面临着许多挑战。以下是一些主要的挑战:
- 数据融合:如何有效地融合来自不同模态的数据是一个重要的挑战。不同模态的数据具有不同的特征和结构,如何将它们有效地整合在一起是一个难题。
- 模态对齐:如何将不同模态的数据对齐也是一个挑战。例如,在图像描述任务中,需要将图像中的对象与文本描述中的词语对齐。
- 知识迁移:如何将从一个模态学习到的知识迁移到另一个模态也是一个挑战。例如,可以将从图像识别任务中学到的知识迁移到文本分类任务中。
- 计算复杂度:多模态AI模型的计算复杂度通常很高,需要大量的计算资源才能进行训练和推理。这限制了多模态AI在资源受限设备上的应用。
结论与展望
Cohere发布的Aya Vision多模态AI模型,无疑是人工智能领域的一项重要进展。它不仅在技术上实现了新的突破,而且在应用上也展现出了广阔的前景。然而,多模态AI技术仍然面临着许多挑战,需要研究人员和开发者共同努力,不断探索和创新。相信在不久的将来,多模态AI将会在各个领域发挥越来越重要的作用,为人类社会带来更多的福祉。
随着人工智能技术的不断发展,我们有理由相信,未来的AI模型将会更加智能、更加高效、更加易用。而像Aya Vision这样的创新性成果,无疑将为我们描绘出一幅更加美好的未来图景。








