
在数字化浪潮席卷全球的今天,非结构化的表格数据以惊人的速度增长,它们隐藏在扫描文档、统计报表图片以及PDF格式的金融报告中。如何高效地从这些数据中提取有价值的信息,成为企业和研究机构面临的一大挑战。传统的人工处理方式效率低下且容易出错,已无法满足日益增长的数据处理需求。因此,表格识别技术应运而生,它不仅是文档智能理解的关键,也是数据分析的重要基石。
然而,传统的通用表格识别模型在面对复杂多变的表格格式时,常常显得力不从心。这些模型在处理诸如合并单元格、嵌套表格或是不规则排版等情况时,识别精度会显著下降,难以满足不同应用场景的特定需求。为了解决这一难题,百度飞桨团队推出了新一代开源表格识别解决方案——PP-TableMagic,旨在通过创新的技术架构和强大的功能,为表格结构化信息提取领域带来革命性的突破。
PP-TableMagic的核心在于其创新的多模型组网架构,这一架构能够实现高精度的端到端表格识别,并且支持全场景高定制化的模型微调。它不仅仅是一个简单的表格识别工具,更是一个强大的、可定制的解决方案,能够适应各种复杂场景下的表格识别需求。该方案的发布,无疑为表格识别技术的发展注入了新的活力。
PP-TableMagic的技术架构
PP-TableMagic采用了一种独特的多模型串联组网方案,它将表格识别任务分解为三个关键步骤:表格分类、表格结构识别和单元格检测。这种分而治之的方法,使得每个模型都可以专注于特定的任务,从而提高整体的识别精度和效率。
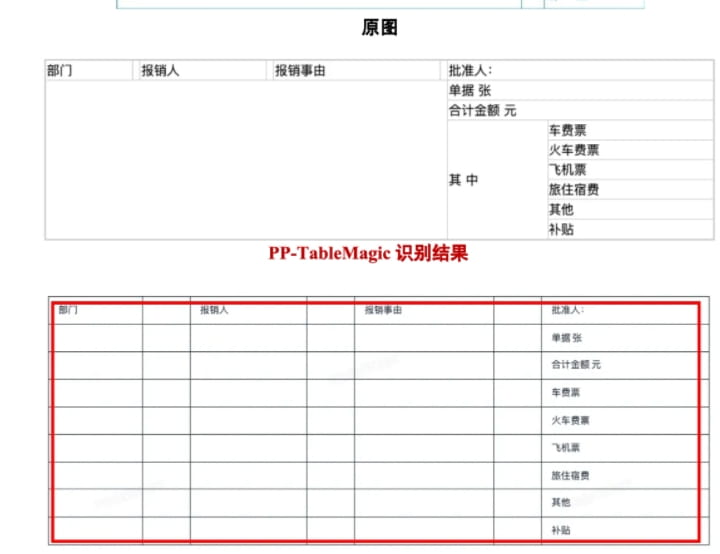
表格分类:PP-TableMagic首先使用飞桨团队自研的轻量级表格分类模型PP-LCNet_x1_0_table_cls,对输入的表格进行分类。该模型能够高精度地区分有线表和无线表,为后续的表格结构识别选择合适的处理策略。有线表指的是具有明显边框线的表格,而无线表则没有明显的边框线,通常依赖于空白区域来分隔单元格。PP-LCNet_x1_0_table_cls模型的轻量级设计,使其能够在保证精度的前提下,实现快速的分类,从而提高整体的识别效率。
单元格检测:在完成表格分类后,PP-TableMagic使用业界首个开源表格单元格检测模型RT-DETR-L_table_cell_det,对表格中的单元格进行精确定位。该模型能够识别各种类型的表格单元格,包括规则的矩形单元格和不规则的合并单元格。RT-DETR-L_table_cell_det模型的强大之处在于其能够有效地处理单元格之间的重叠和遮挡,从而保证单元格检测的准确性。通过精确定位每个单元格的位置,PP-TableMagic为后续的表格结构识别提供了重要的基础。
表格结构识别:最后,PP-TableMagic使用新一代表格结构识别模型SLANeXt,对表格的HTML结构进行解析。SLANeXt模型在表格HTML结构解析方面表现出色,它使用了更强的特征表征能力的Vary-ViT-B作为视觉编码器,相比前代模型SLANet和SLANet_plus,进一步提升了表格结构识别的准确性。SLANeXt模型能够将检测到的单元格信息和分类信息,转化为结构化的HTML表格,从而实现表格的完整识别。通过自优化结果融合算法,PP-TableMagic能够生成最终的、高质量的HTML表格预测结果。
PP-TableMagic的优势
PP-TableMagic的创新架构设计赋予了其诸多优势,使其在表格识别领域脱颖而出:
高精度:通过多模型串联组网方案,PP-TableMagic能够充分利用每个模型的优势,从而实现高精度的表格识别。表格分类模型能够准确地区分有线表和无线表,单元格检测模型能够精确定位每个单元格的位置,表格结构识别模型能够准确解析表格的HTML结构。这些模型的协同工作,使得PP-TableMagic在各种复杂场景下都能保持较高的识别精度。
高适应性:PP-TableMagic的多模型组网架构使其具有很高的适应性。该架构允许用户根据实际需求,对关键模型进行微调,从而优化整体的识别性能。例如,在处理特定类型的表格时,用户可以针对性地微调表格结构识别模型,以提高对该类型表格的识别精度。这种灵活性使得PP-TableMagic能够适应各种不同的应用场景。
低成本:与传统的端到端表格识别模型相比,PP-TableMagic的多模型组网架构降低了模型微调的成本。用户只需对关键模型进行微调,而无需对整个模型进行重新训练,从而节省了大量的时间和计算资源。此外,PP-TableMagic还支持分支级调整,允许用户针对特定类型的表格数据进行优化,进一步降低了微调的成本。
PP-TableMagic的实际应用
PP-TableMagic在实际应用中展现出了强大的能力。它不仅能够直接处理表格,还能通过定制化的模型微调满足不同场景的需求。与传统端到端表格识别模型的微调相比,PP-TableMagic的多模型组网架构允许用户仅对关键模型进行微调,从而避免了“此消彼长”的性能问题,同时减少了数据标注的工作量。此外,对于资深开发者而言,PP-TableMagic的架构还支持分支级调整,能够针对特定类型的表格数据进行优化,进一步提升整体识别能力。
例如,在金融领域,PP-TableMagic可以用于自动提取财务报表中的数据,从而提高财务分析的效率。在医疗领域,它可以用于自动识别病历中的表格数据,从而帮助医生更好地了解患者的病情。在教育领域,它可以用于自动提取试卷中的表格数据,从而方便教师进行批改和统计。总而言之,PP-TableMagic的应用前景非常广泛,几乎可以应用于任何需要处理表格数据的领域。
PP-TableMagic的易用性
为了帮助用户快速上手,PP-TableMagic提供了详细的安装指南和使用教程。用户可以通过PaddleX提供的Python API轻松调用模型,进行表格识别和结果导出。此外,PP-TableMagic还支持高性能推理、服务化部署以及端侧部署,能够满足不同用户的需求。百度飞桨团队还计划在3月13日举办线上课程,深度解析PP-TableMagic的技术细节,并开设产业场景实战营,带领用户体验从数据准备到模型部署的完整开发流程。
PP-TableMagic的易用性体现在以下几个方面:
- 详细的文档:PP-TableMagic提供了详细的安装指南和使用教程,帮助用户快速了解和使用该工具。文档中包含了各种示例代码和操作步骤,即使是没有经验的用户也能轻松上手。
- 简单的API:PP-TableMagic提供了PaddleX Python API,用户可以通过简单的几行代码调用模型,进行表格识别和结果导出。API的设计简洁明了,易于理解和使用。
- 灵活的部署方式:PP-TableMagic支持多种部署方式,包括高性能推理、服务化部署以及端侧部署。用户可以根据自己的需求选择合适的部署方式,从而实现最佳的性能和效率。
结论与展望
PP-TableMagic作为百度AI开源的新一代表格识别解决方案,以其创新的多模型组网架构、高精度、高适应性和低成本等优势,为表格结构化信息提取领域带来了重大突破。它的发布不仅为开发者提供了一个强大的工具,也为各行各业的数据处理带来了新的可能性。
随着人工智能技术的不断发展,表格识别技术也将迎来更多的创新和突破。我们期待PP-TableMagic能够在未来的发展中,不断完善和优化,为用户带来更好的体验和服务。同时,我们也希望更多的开发者能够加入到PP-TableMagic的开源社区中,共同推动表格识别技术的发展。








