
在人工智能视频生成领域,一场由开源社区引领的“平民革命”正在发生。过去,动辄数百万美元的训练成本使得AI视频创作似乎只是科技巨头的专属游戏。然而,随着Open-Sora 2.0的横空出世,这一局面正在被彻底颠覆。这款性能直逼商业级水准的110亿参数大模型,仅花费20万美元(224张GPU)便训练成功,相较于那些耗资巨大的闭源模型,其性价比优势显而易见。
Open-Sora 2.0的发布,无疑为视频生成领域带来了前所未有的开放性。它不仅具备媲美甚至超越百万美元级模型的强大实力,更以开放的姿态,将模型权重、推理代码、训练流程全盘托出,为高质量视频创作打开了新的可能性。这意味着,曾经遥不可及的AI视频生成技术,如今已变得触手可及,每个人都有机会参与到这场激动人心的创作浪潮中来。
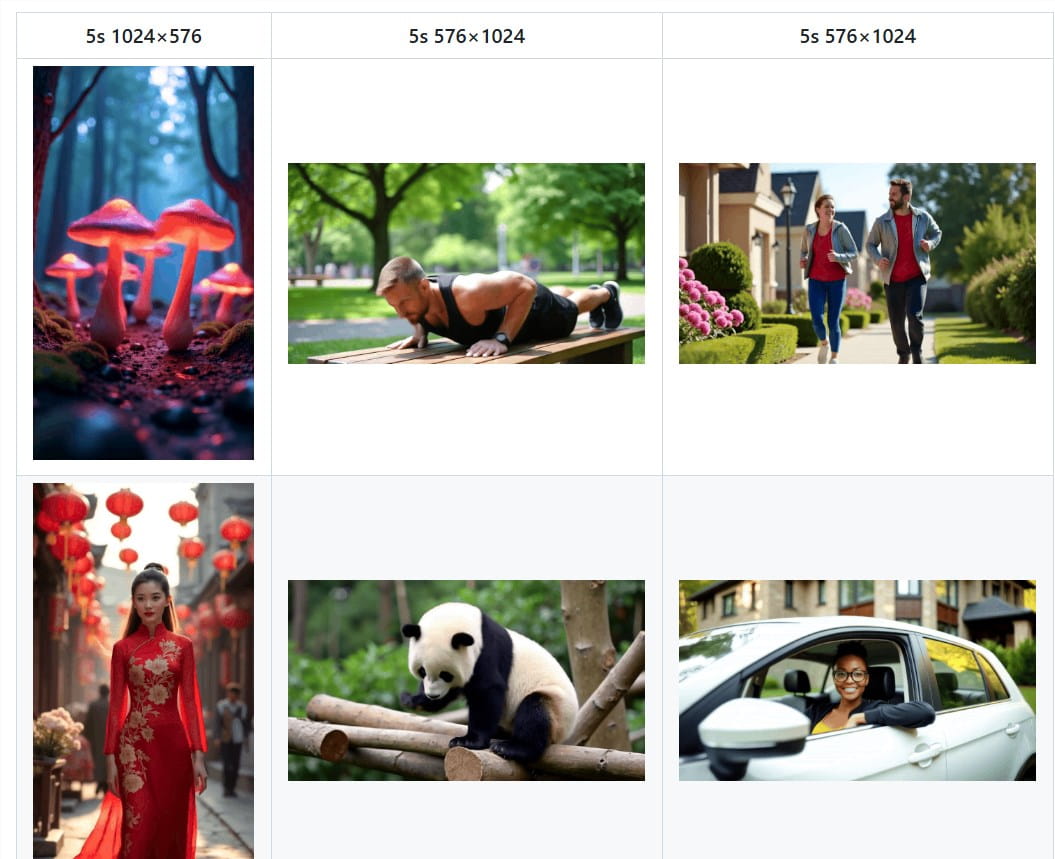
硬核实力:数据说话,眼见为实
Open-Sora 2.0的生成效果究竟如何?让我们通过一系列Demo视频来一探究竟:
- 运镜如神,动作幅度精准:无论是人物的细腻动作,还是场景的宏大调度,Open-Sora 2.0都能精准控制运动幅度,画面表现力十足。
- 画质高清,流畅度丝滑:720p高清分辨率,24FPS稳定帧率,Open-Sora 2.0生成的视频,清晰度、流畅度都无可挑剔,视觉体验卓越。
- 场景百变,驾驭能力全面:田园风光、都市夜景、科幻宇宙……各种复杂场景,Open-Sora 2.0都能轻松驾驭,画面细节丰富,相机运镜流畅自然。
Open-Sora 2.0并非只是“花架子”,而是拥有真正的技术实力。它以110亿的参数规模,在VBench和用户主观评测中,都取得了足以媲美HunyuanVideo和30B Step-Video等闭源模型的卓越成绩。
用户说了算:偏好性评测力压群雄
在视觉效果、文本一致性、动作表现三大维度上,Open-Sora 2.0至少有两项指标超越了开源SOTA模型HunyuanVideo,甚至超越了Runway Gen-3Alpha等商业模型,证明了“低成本也能有好货”。
VBench榜单:实力认证,性能逼近天花板
在视频生成领域权威的VBench榜单上,Open-Sora 2.0的进步速度惊人。从1.2版本到2.0版本,它与OpenAI Sora闭源模型之间的性能差距,从4.52%缩减到0.69%,几乎可以忽略不计。更令人振奋的是,Open-Sora 2.0在VBench评测中得分,已经超越了腾讯HunyuanVideo,再次证明其“低投入,高产出”的巨大优势,为开源视频生成技术树立了新的里程碑。
低成本炼成记:开源背后的技术密码
Open-Sora自开源以来,就以其高效、优质的视频生成能力,迅速成为开源社区的热门项目。但随之而来的挑战是:如何打破高质量视频生成“成本高企”的魔咒,让更多人能够参与进来?Open-Sora团队迎难而上,通过一系列技术创新,将模型训练成本降低了5-10倍。要知道,市面上动辄数百万美元的训练费用,Open-Sora 2.0仅用20万美元就完成了。
Open-Sora不仅开源了模型代码和权重,还公开了全流程训练代码,构建起了一个充满活力的开源生态。在短短半年时间内,Open-Sora的学术论文引用量就接近百次,在全球开源影响力榜单上名列前茅,超越了所有开源I2V/T2V视频生成项目,成为当之无愧的“开源视频生成领头羊”。
模型架构:传承与创新并举
Open-Sora 2.0在模型架构上,既传承了1.2版本的精髓,又进行了大胆创新:延续了3D自编码器和Flow Matching训练框架,并保留了多桶训练机制,确保模型能够处理各种长度和分辨率的视频。同时,又引入了多项技术,让视频生成能力更上一层楼:
- 3D全注意力机制加持:更精准地捕捉视频中的时间和空间信息,让生成的视频画面更连贯、细节更丰富。
- MMDiT架构“神助攻”:更准确地理解文本指令和视频内容之间的关联,让文生视频的语义表达更精准、更到位。
- 模型规模扩容至11B:更大的模型容量,意味着更强的学习能力和生成潜力,视频质量自然水涨船高。
- FLUX模型“打底”,训练效率“起飞”:借鉴开源图生视频模型FLUX的成功经验,进行模型初始化,大幅降低了训练时间和成本,让模型训练效率提升。
高效训练秘籍:开源全流程,助力成本“狂降”
为了将训练成本降到最低,Open-Sora 2.0在数据、算力、策略等方面都做足了功课:
- 数据“精挑细选”,质量“万里挑一”:Open-Sora团队深知数据质量的重要性,对训练数据进行筛选,确保每一份数据都是高质量的,从源头上提升模型训练效率。多阶段、多层次的数据筛选机制,配合各种过滤器,让视频数据质量更上一层楼,为模型训练提供了优质的“燃料”。
- 算力“精打细算”,低分辨率训练“打头阵”:高分辨率视频训练的成本远高于低分辨率视频,二者之间的算力差距巨大。Open-Sora 2.0巧妙地避开了“硬碰硬”,优先进行低分辨率训练,高效学习视频中的运动信息,在大幅降低成本的同时,确保模型能够掌握视频生成的“核心技能”。
- 策略“灵活多变”,图生视频“曲线救国”:Open-Sora 2.0并没有一开始就“死磕”高分辨率视频训练,而是采取了更聪明的策略——优先训练图生视频模型,加速模型收敛速度。事实证明,图生视频模型在提升分辨率时,收敛速度更快,训练成本更低。在推理阶段,Open-Sora 2.0还支持“文生图再生视频”(T2I2V)模式,用户可以先通过文本生成高质量图像,再将图像转化为视频,获得更精细的视觉效果。
并行训练“火力全开”,算力利用率提升
Open-Sora 2.0深知团队合作的重要性,采用了高效的并行训练方案,将ColossalAI和系统级优化技术整合,最大程度提升计算资源利用率,让GPU集群火力全开,实现更高效的视频生成训练。一系列技术加持,让Open-Sora 2.0的训练效率提升,成本大幅降低:
- 序列并行+ZeroDP:优化大规模模型分布式计算效率。
- 细粒度Gradient Checkpointing:在降低显存占用的同时,保持计算效率。
- 训练自动恢复机制:确保有效训练时间,减少资源浪费。
- 高效数据加载+内存管理:优化I/O,防止训练阻塞,加速训练流程。
- 异步模型保存:减少模型存储对训练干扰,提高GPU利用率。
- 算子优化:针对关键计算模块深度优化,加速训练过程。
这些优化措施相结合,Open-Sora 2.0在高性能和低成本之间找到了平衡,大幅降低了高质量视频生成模型的训练门槛,让更多人能够参与到这场技术盛宴中来。
高压缩比AE,推理速度提升
训练成本降低还不够,推理速度也要跟上!Open-Sora 2.0瞄准未来,探索高压缩比视频自编码器(AE)的应用,进一步降低推理成本,提升视频生成速度。目前主流视频模型采用4×8×8自编码器,生成768px、5秒视频,单卡耗时近30分钟,推理效率有待提升。Open-Sora 2.0训练了一款高压缩比(4×32×32)的视频自编码器,将推理时间缩短至单卡3分钟以内,速度提升了10倍!
高压缩比编码器虽好,训练难度却极大。Open-Sora团队迎难而上,在视频升降采样模块中引入残差连接,成功训练出重建质量媲美SOTA视频压缩模型,且压缩比更高的VAE,为高效推理奠定了基础。为了解决高压缩比自编码器训练数据需求大、收敛难度高等问题,Open-Sora还提出了基于蒸馏的优化策略,并利用已训练好的高质量模型进行初始化,减少数据和时间需求。同时,重点训练图生视频任务,利用图像特征引导视频生成,加速高压缩自编码器收敛,最终实现了推理速度和生成质量的双赢。
Open-Sora团队坚信,高压缩比视频自编码器将是未来视频生成技术发展的关键方向。目前初步实验结果已展现出惊人的推理加速效果,他们希望借此吸引更多社区力量,共同探索高压缩比视频自编码器的潜力,推动高效、低成本视频生成技术更快发展,让AI视频创作真正普及。
Open-Sora 2.0的开源,标志着AI视频生成技术正在走向普及化和大众化。它不仅降低了视频生成的成本,更提供了开放的平台,让更多人能够参与到技术创新和应用中来。我们有理由相信,在开源社区的共同努力下,AI视频生成技术将会迎来更加美好的未来。








