
Gemini 2.0 Flash:多模态能力再升级
近日,谷歌宣布在Google AI Studio和Gemini API上开放Gemini 2.0 Flash的原生图像生成功能,供开发者测试和实验。这一更新标志着Gemini模型在多模态能力上又迈出了重要一步,实现了文本与图像的无缝融合。
Gemini一直以其强大的多模态理解能力著称。它不仅能理解文本,还能理解图像,并在二者之间建立联系。而此次更新,Gemini 2.0 Flash不仅能理解图文,还能直接根据描述生成高质量的图片,实现了图文的“双向奔赴”。
🌟 Gemini 2.0 Flash:四大核心功能
Gemini 2.0 Flash的核心功能包括:
- 文本+图像生成: 根据文本描述,生成与之匹配的高质量图像。
- 对话式图像编辑: 通过自然语言对话的方式,对生成的图像进行修改和调整。
- 真实感图片创作: 结合现实世界的知识,生成逼真的图像内容。
- 高质量文本渲染: 在生成的图像中,准确、清晰地渲染文本内容。
🚀 Gemini 2.0 Flash:三大技术优势
Gemini 2.0 Flash之所以能够实现这些强大的功能,得益于其三大技术优势:
- 多模态能力: 能够同时理解文字、图像,并在二者之间建立联系。
- 智能推理: 能够结合现实世界的知识,生成准确的视觉内容。
- 自然语言交互: 支持用户通过对话方式调整修改图片,类似AI画师助手。
🎮 试玩体验:Gemini 2.0 Flash的惊艳表现
接下来,让我们通过几个实际的例子,来体验一下Gemini 2.0 Flash的强大功能:
场景一:连续插画生成
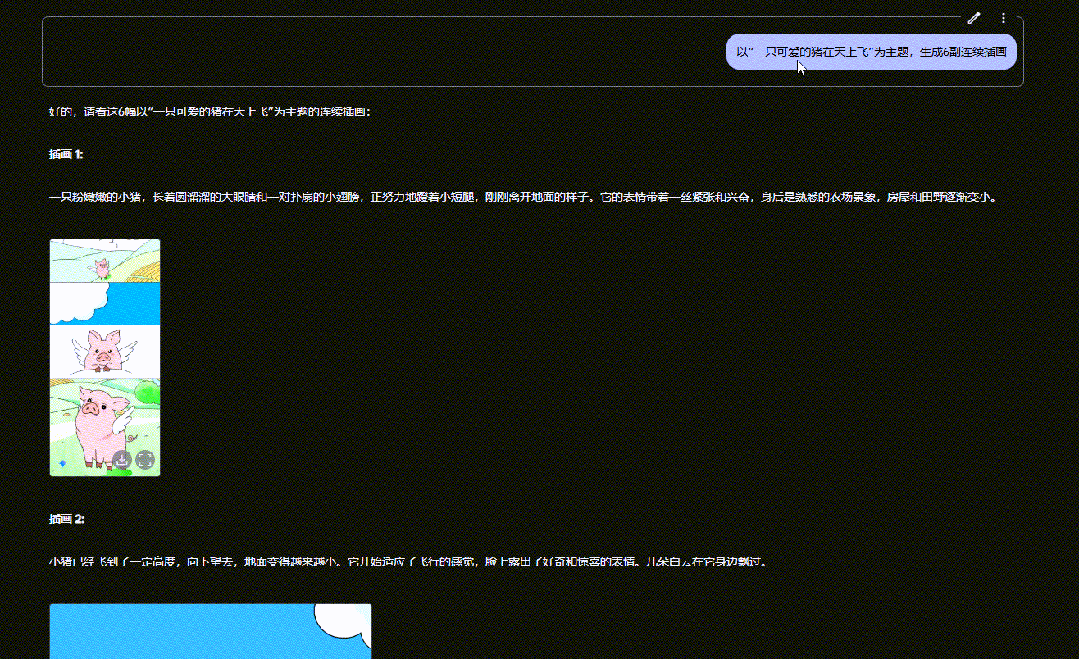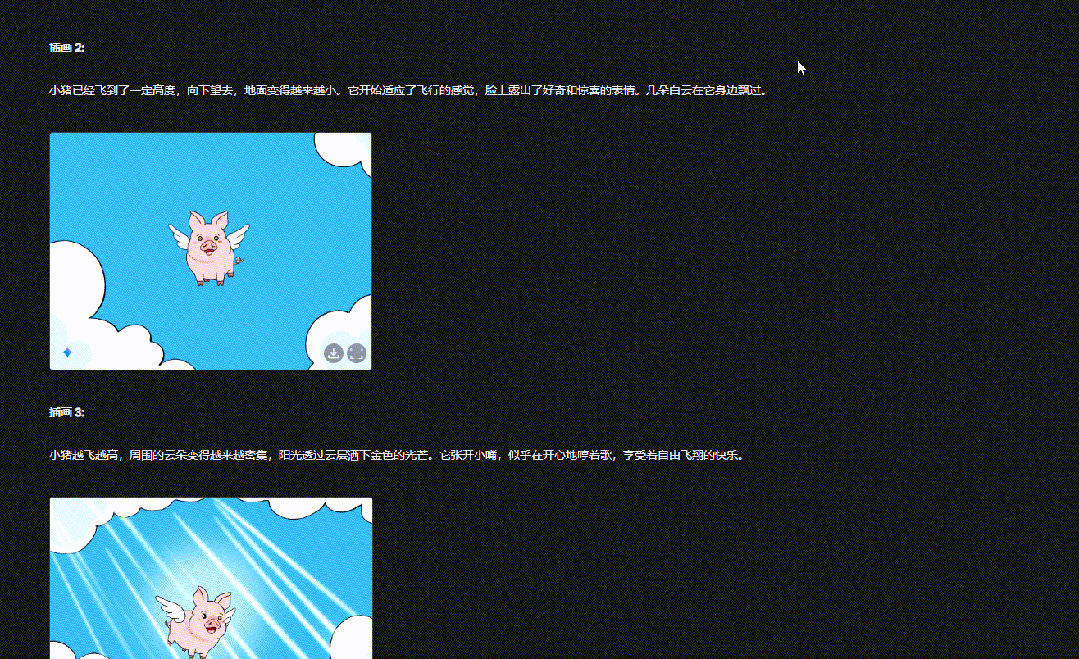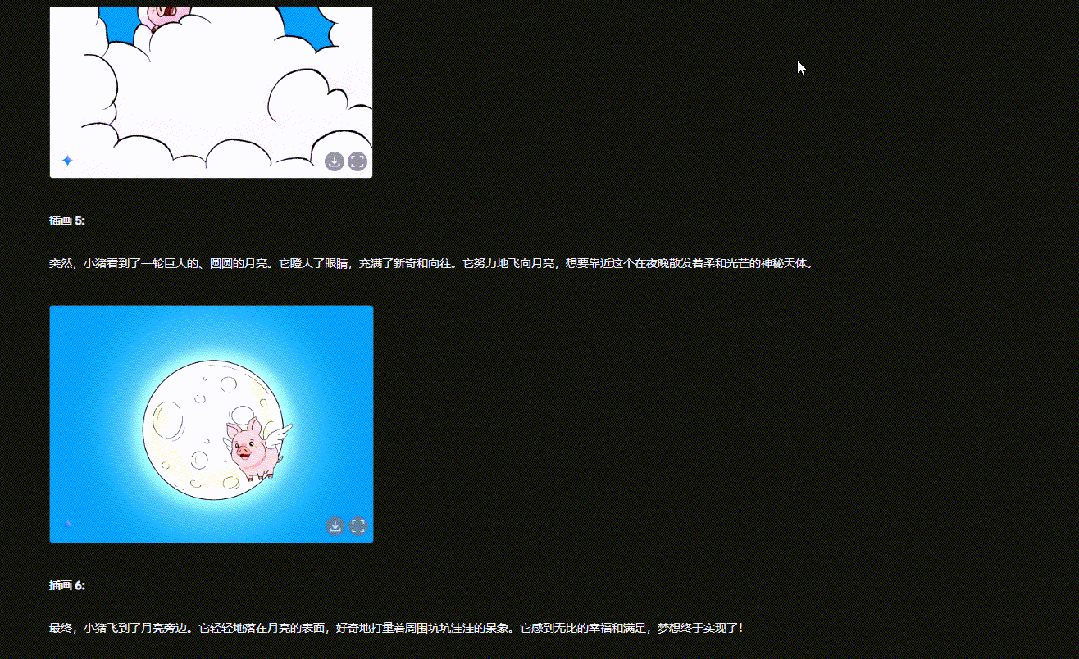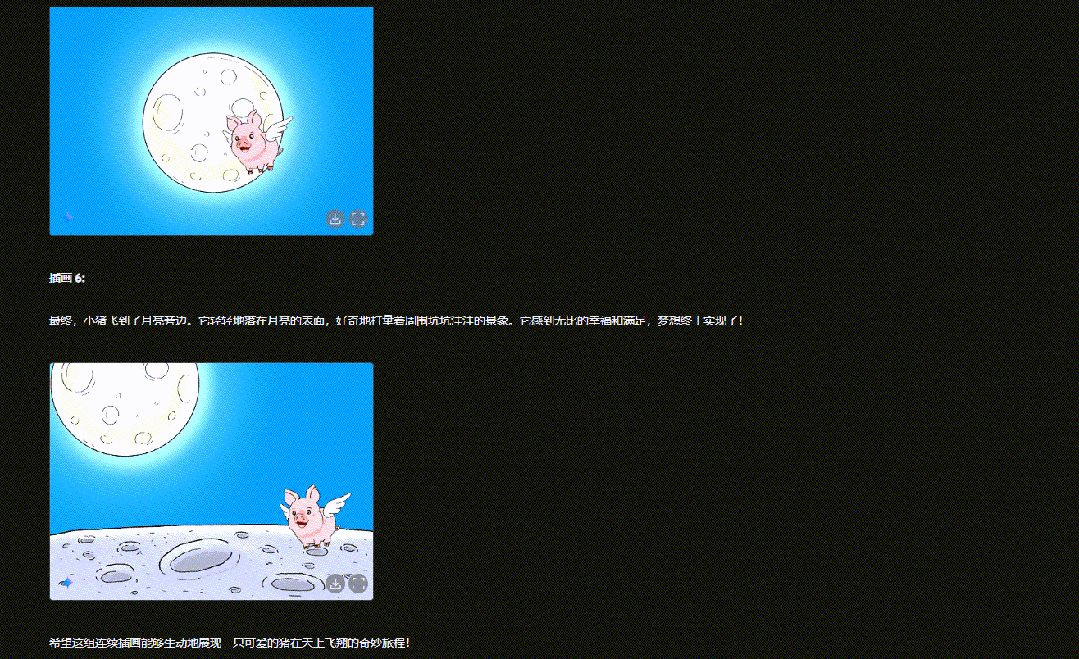
输入描述: “以‘一只可爱的猪在天上飞’为主题,生成6副连续插画。”
Gemini 2.0 Flash会根据文本生成一系列插图,让角色和场景在不同画面中保持一致性。从结果可以看到,它能在一次内容输出中包含多张图,且角色形象始终如一。
进一步,我们还可以要求它修改绘画风格(如卡通风、写实风等)。
这种连续插画生成的能力,为儿童插画故事、古诗插画等内容的创作提供了极大的便利,大大降低了制作门槛。
场景二:对话式图像编辑
输入描述: “生成一个蓝色的房子。”
然后,我们可以通过自然语言对话的方式,对生成的图像进行修改:
- “把房顶改成红色的。”
- “在房子前面加一个花园。”
- “把窗户变大一点。”
Gemini 2.0 Flash能够准确理解我们的指令,并对图像进行相应的修改。这种对话式的图像编辑方式,让AI更像是一位“听话”的画师助手,大大提高了图像编辑的效率和便捷性。
场景三:真实感图片创作
输入描述: “我想做一道东北大乱炖,请告诉我要怎么做,每一步骤请配上图片。”
Gemini 2.0 Flash不仅会给出详细的烹饪步骤,还会为每一步骤配上相应的图片,让整个过程更加直观、易懂。
这种真实感图片创作的能力,得益于Gemini强大的世界知识和推理能力。它能够结合现实世界的知识,生成更符合实际情况的图像内容。
场景四:高质量文本渲染
输入描述: “生成一张小米SU7 Ultra广告海报,要求写上‘极致性能,驭电而行’+商品图。”
Gemini 2.0 Flash能够准确、清晰地渲染出海报中的文字,避免了传统AI画图工具中常见的文字模糊、错别字等问题。
这种高质量的文本渲染能力,使得Gemini 2.0 Flash在广告海报、宣传物料等设计领域具有更强的实用性。
🌐 Gemini 2.0 Flash:AGI的曙光?
在简单体验了Gemini 2.0 Flash的更新之后,我们不禁惊叹于其强大的多模态能力。它不仅能理解多种模态的信息,还能在不同模态间自如转换;不仅能遵循指令,还能理解文化背景和现实世界的细节;不仅能一次性完成任务,还能通过多轮对话持续优化结果。
这种跨模态理解、推理和创作的综合能力,确实让我们仿佛看到了AGI(通用人工智能)的影子。虽然Gemini 2.0 Flash距离真正的AGI还有很长的路要走,但它的出现,无疑为AGI的研究和发展提供了新的思路和方向。
结语:Gemini 2.0 Flash,未来可期
Gemini 2.0 Flash的此次更新,让我们看到了AI技术在多模态领域的巨大潜力。它不仅为内容创作者、设计师等专业人士提供了强大的工具,也为普通用户带来了更加便捷、智能的体验。
随着AI技术的不断发展,我们有理由相信,未来的AI将更加智能、更加强大,为我们的生活和工作带来更多惊喜和改变。








