
AI智能水平新挑战:ARC-AGI-2让顶尖模型遭遇瓶颈
人工智能(AI)领域又迎来了一项新的挑战。Arc Prize 基金会近日发布了全新的测试基准——ARC-AGI-2,旨在更精准地评估AI模型的通用智能水平。这项由著名AI研究者François Chollet共同创立的基金会表示,ARC-AGI-2对当前领先的AI模型提出了前所未有的严峻考验。

根据 Arc Prize 基金会的排行榜数据,即使是那些被认为是“推理型”的AI模型,如OpenAI的o1-pro和DeepSeek的R1,在ARC-AGI-2测试中的得分也仅徘徊在1%到1.3%之间。而像GPT-4.5、Claude3.7Sonnet和Gemini2.0Flash这样更为强大的非推理模型,得分也仅在1%左右。ARC-AGI测试的核心在于一系列精心设计的拼图问题,这些问题要求AI模型从不同颜色的方块中识别出隐藏的视觉模式,并最终生成正确的“答案”网格。这些问题的关键设计理念是迫使AI模型适应前所未见的新问题,以此来测试其真正的泛化能力。
为了建立一个可靠的人类基准,Arc Prize 基金会邀请了超过400名参与者进行ARC-AGI-2测试。结果显示,这些参与者的平均得分高达60%,远远超过了任何AI模型的得分。François Chollet在社交媒体上评论说,ARC-AGI-2相比于前一个版本ARC-AGI-1,能够更有效地测量AI模型的实际智能。这项新的测试旨在评估AI系统是否能够高效地获取超出其训练数据范围之外的全新技能。
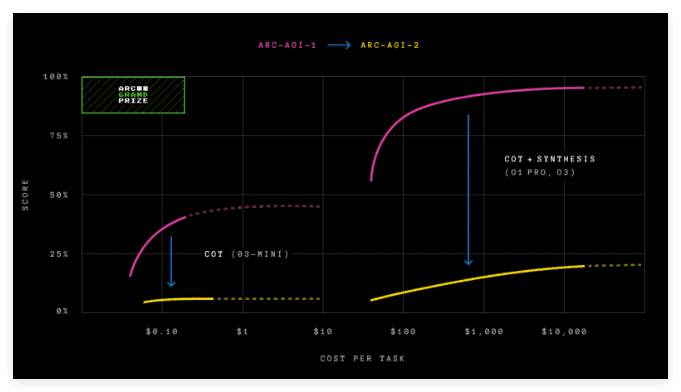
ARC-AGI-2在设计上相较于ARC-AGI-1有了显著的改进,尤其是在引入了“效率”这一关键指标。它要求模型在没有任何记忆依赖的情况下,即时地解释模式。正如Arc Prize 基金会的共同创始人Greg Kamradt所强调的那样,智力不仅仅体现在解决问题的能力上,效率同样是一个至关重要的因素。这意味着,一个真正智能的AI系统不仅应该能够找到解决方案,还应该能够以最快的速度和最少的资源消耗来实现这一目标。
值得注意的是,OpenAI的o3模型曾在ARC-AGI-1中以75.7%的得分遥遥领先,直到2024年才被其他模型超越。然而,令人惊讶的是,o3在ARC-AGI-2中的得分却大幅下降至仅为4%,而且在每个任务上的计算成本高达200美元。这一结果凸显了ARC-AGI-2测试对于评估AI模型真实智能的严格性和有效性。
ARC-AGI-2的发布正值技术界对新的AI进展衡量标准的呼声日益高涨之际。Hugging Face的联合创始人Thomas Wolf曾明确表示,AI行业目前缺乏足够的测试来衡量那些被称为人工通用智能(AGI)的关键特征,包括创造力、适应性和解决复杂问题的能力。现有的许多基准测试往往侧重于特定任务的性能,而忽略了AI系统在面对全新挑战时的泛化能力。
与此同时,Arc Prize 基金会还宣布了2025年的Arc Prize竞赛,公开挑战开发者在ARC-AGI-2测试中达到85%的准确率,并且每个任务的花费仅为0.42美元。这项竞赛旨在鼓励研究人员和开发者们探索新的AI架构和算法,以期在通用智能方面取得更大的突破。
ARC-AGI-2:AI通用智能评估的新标杆
随着人工智能技术的飞速发展,我们对于如何准确评估AI的智能水平的需求也日益迫切。传统的基准测试往往侧重于特定任务的性能,例如图像识别或自然语言处理,而忽略了AI系统在面对全新、未知的挑战时的泛化能力。为了弥补这一缺陷,Arc Prize 基金会推出了ARC-AGI-2,一项旨在更全面、更准确地衡量AI通用智能水平的全新测试。
ARC-AGI-2的设计理念是基于抽象推理的概念,它要求AI系统能够从一系列视觉模式中学习,并将这些模式应用到新的、未知的场景中。这种测试方式模仿了人类解决问题的过程,即首先理解问题的本质,然后运用已有的知识和经验来找到解决方案。与传统的基准测试相比,ARC-AGI-2更加注重考察AI系统的学习能力、适应能力和创造能力。
ARC-AGI-2的挑战性
ARC-AGI-2之所以能够成为AI领域的一项重大挑战,主要归功于其独特的设计和严格的评估标准。以下是ARC-AGI-2的一些关键特征:
- 抽象推理:ARC-AGI-2的核心在于抽象推理能力。测试中的问题并非简单地重复训练数据中的模式,而是需要AI系统理解隐藏在视觉模式背后的抽象概念,并将其应用到新的情境中。
- 泛化能力:ARC-AGI-2旨在评估AI系统的泛化能力,即其在面对未见过的数据时的表现。为了实现这一目标,测试中的问题都经过精心设计,以确保AI系统无法通过简单的记忆或模式匹配来解决问题。
- 效率:ARC-AGI-2不仅关注AI系统的准确性,还强调其效率。测试要求AI系统在有限的计算资源和时间内找到解决方案,这模拟了现实世界中资源有限的场景。
- 人类基准:为了更好地理解AI系统的表现,ARC-AGI-2设立了一个人类基准。通过对比AI系统和人类在同一测试中的表现,我们可以更清楚地了解AI在通用智能方面与人类的差距。
顶尖AI模型在ARC-AGI-2中的表现
ARC-AGI-2的测试结果显示,即使是最先进的AI模型,在通用智能方面仍然与人类存在显著差距。例如,OpenAI的GPT-4.5、Claude3.7Sonnet和Gemini2.0Flash等模型在ARC-AGI-2中的得分仅为1%左右,远低于人类参与者的平均得分60%。
这一结果表明,当前AI模型在抽象推理、泛化能力和效率方面仍然存在很大的提升空间。尽管这些模型在特定任务上表现出色,但在面对全新的、未知的挑战时,它们的表现往往不尽如人意。这凸显了开发更具通用性和适应性的AI系统的重要性。
ARC-AGI-2对AI研究的意义
ARC-AGI-2的发布对AI研究领域具有重要的意义。它为研究人员提供了一个新的、更具挑战性的基准测试,可以帮助他们更好地评估AI系统的通用智能水平。此外,ARC-AGI-2还可以促进AI研究的创新,鼓励研究人员探索新的AI架构和算法,以期在通用智能方面取得更大的突破。
ARC-AGI-2的出现也引发了人们对于AI发展方向的思考。我们是否应该继续专注于开发在特定任务上表现出色的AI系统,还是应该将更多的精力投入到开发更具通用性和适应性的AI系统?这是一个值得深入探讨的问题。
迎接AI通用智能的挑战
ARC-AGI-2的发布标志着AI研究进入了一个新的阶段。在这个阶段,我们不仅要关注AI在特定任务上的性能,更要关注其在通用智能方面的表现。通过不断地挑战和改进AI系统,我们可以逐步缩小AI与人类在智能方面的差距,最终实现真正的通用人工智能。
Arc Prize 基金会举办的2025年Arc Prize竞赛为研究人员提供了一个绝佳的机会,可以共同努力,在ARC-AGI-2测试中取得更大的突破。我们期待着看到更多创新性的AI解决方案涌现,为AI通用智能的发展做出贡献。
行业专家观点
Hugging Face的联合创始人Thomas Wolf认为,AI行业目前缺乏足够的测试来衡量人工通用智能的关键特征,包括创造力。ARC-AGI-2的出现,无疑是朝着这个方向迈出的重要一步。它提供了一个更加全面、更加严格的评估标准,可以帮助我们更好地了解AI的真实能力。
未来展望
随着AI技术的不断发展,我们有理由相信,未来的AI系统将会在ARC-AGI-2等通用智能测试中取得更好的成绩。通过不断地研究和创新,我们有望开发出真正具有通用性和适应性的AI系统,为人类社会带来更大的福祉。
未来的AI发展方向将不仅仅局限于特定任务的优化,更重要的是提升AI的通用智能水平。这需要我们从多个方面入手,包括改进AI的架构、算法和训练方法。只有这样,我们才能真正实现人工智能的潜力,创造一个更加美好的未来。
总而言之,ARC-AGI-2的发布是AI领域的一个重要里程碑。它为我们提供了一个新的视角,可以更全面地评估AI的智能水平,并为未来的AI研究指明了方向。我们期待着看到AI技术在通用智能方面取得更大的突破,为人类社会的发展做出更大的贡献。








